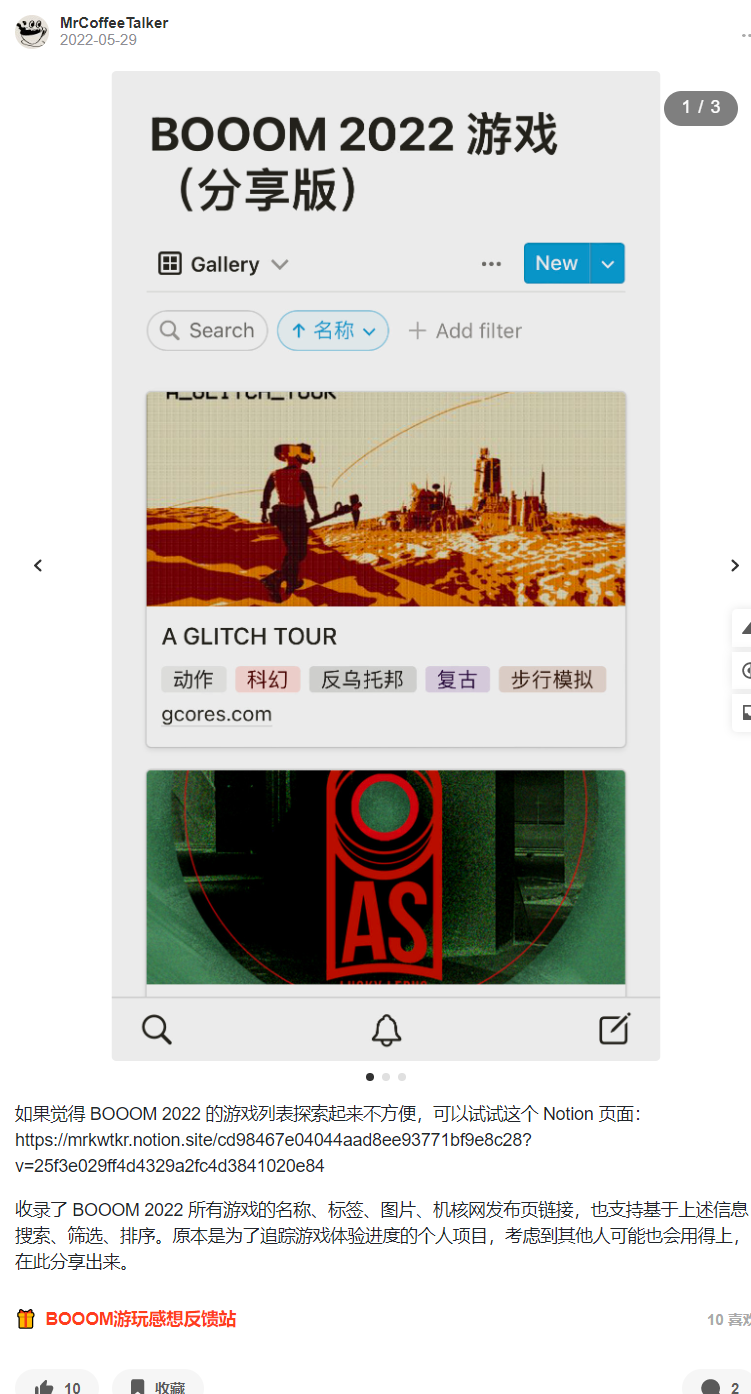
5 月底的那天,我發了一條動態「定一個小目標:體驗完這次 BOOOM 2022 參賽的 113 個作品,為每一款遊戲寫評價、發佈對應的遊玩視頻。」
同一天稍晚,我陷入了疑惑:「這個點讚的西蒙是誰啊?名字好像有點眼熟。」
後來去搜了下,才發現是「那個西蒙」。
之所具體到 113 個作品,並非是我看過官方公開的詳細數目,又或是我一個個的數過,而是因為我在更早前,將這些作品的信息收集了下來,放在了一個 遊戲庫 中。如果說自己為什麼會這麼做,我想到的是去年年底的那次核聚變。
早前做的遊戲庫,收錄了這屆 BOOOM 所有作品的信息
那是我第一次參加線下的遊戲展會,剛好有朋友做過核聚變的志願者,推薦之下瞭解到這個活動。興致沖沖的我預訂了兩天的門票,前一天晚上在書店研究出展的遊戲信息到幾近通宵,只為提前規劃、以便兩天內能更多的瞭解感興趣的遊戲。儘管第一天在找入口時廢了不少時間,但兩天遊覽下來,可以說是充滿了難忘的回憶。
核聚變前一天,我在書店熬夜整理了參展遊戲信息,提前標註了感興趣的遊戲
也是在這一次展會中,我第一次瞭解到了 BOOOM。
依稀記得那個黃黑色的展區,在場地中格外顯眼。在好奇心的驅使下,我去圍觀了一番,當時玩了一個有關時間神廟的解謎遊戲,和現場的開發者交流了遊玩體驗。之後看到隔壁配套 DIY 手柄的解謎遊戲,被一群人圍得水洩不通,也在心中下定決心,想著第二天一定要去上手玩玩看。
我也還記得第一天找入口找了半天,沒有箭頭指引,哪裡是“前”?
然而我終歸是低估了大家的熱情,第二天那個攤位附近依然圍滿了人,眼看著就剩下不到一天的遊覽時間,我便和同行的朋友轉去刷了一下午的抽獎任務,抽完獎後,剛好在隔壁買了一個機組成員的揹包,當時好像是要先線上下單、再線下取貨,便由此下載了機核的 app。
雖然刷完了抽獎任務,遊覽了不少遊戲攤位,但心裡總感覺像是缺了一塊什麼。
時光輾轉,半年過去,我正因興趣研究著遊戲的宣傳片製作,積累了一些想要分享的知識,便開始評估自己已知的幾個平臺。最終我選擇了機核,因為看上去社區討論氛圍最好、圖文也比較符合自己的創作偏好,準備先發一篇有關如何製作宣傳片的綜述性譯介(就是後來的 這篇 )。當我打開 APP 想摸索如何投稿時,偶然刷到了 BOOOM 的推送,也想起了上一次線下試玩的遺憾。
我突然有了一個想法,「體驗完這屆 BOOOM 的所有遊戲」,但要體驗所有的 BOOOM 作品,首先我得知道最終徵集到了多少個作品。經過隨後的一系列折騰,我成功在當天內搭建好了一個遊戲庫,收錄完了 BOOOM 2022 的所有遊戲信息。
在這篇文章中,我將回顧自己搭建這個遊戲庫的歷程,如果你對數據收集、效率提升或信息管理感興趣,或許也能為你解鎖一些新知識。
評估實現方案
在機核已經提供了 BOOOM 遊戲列表 的情況下,數據的來源可以說是很明確了,直接從官方的頁面中獲取就可以。擺在開頭的問題是:如何收集這些數據?收集後又要如何儲存和呈現?
BOOOM 官方頁面的遊戲列表
如果遊戲量不多,比如只有十幾個,那我還可以考慮人工收集一下,但掃一眼 BOOOM 的頁面便知,這次總共徵集到了百餘款作品。如果人工收集一個遊戲要 1 分鐘,怎麼說也得兩小時,而且這是一個高度機械重複的工作,很難保證做到中途會不會喪失動力和興趣,因而我最好考慮更高效的方案。
恰好我對 Python 爬蟲略有了解,便想到用爬蟲來收集數據,這樣不單單能瞭解「有多少個作品」,連每個作品相關的名稱、類型、鏈接等信息都能一併收錄。但是否能爬、如何爬,取決於目標網頁的情況。
為此,我需要從爬蟲開發的角度評估 BOOOM 的活動頁面,我通常會關注的點包括:
需要哪些數據 :比如文本、鏈接、圖片,這部分會影響到數據提取的方式,以及後續如何儲存這些數據
選用哪一種爬蟲庫 :取決於頁面數據的加載方式(靜態/動態)、是否需要登錄、爬取邏輯的複雜度(加載更多/自動翻頁/跳轉新頁面)等,我通常考慮的庫有 scrapy、selenium 和 requests
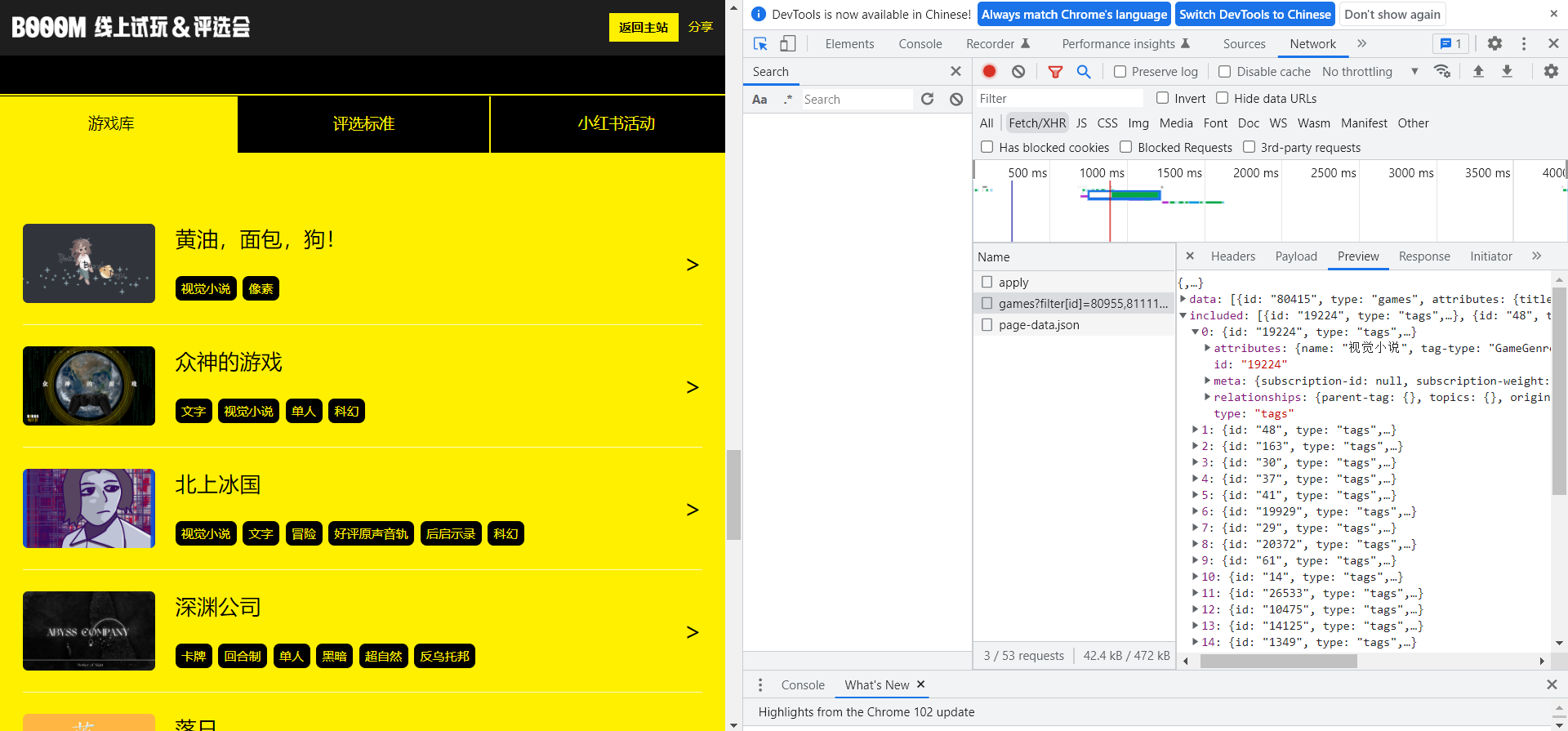
是否有可能不用寫爬蟲 :比如如果能通過 Chrome Network 調試找到發送數據的請求、又比較方便手動構造是最好的,因為能拿到乾淨的 json 數據,而且又省事
寫爬蟲之前,我會先打開 Chrome 瀏覽器的開發者模式,審查頁面元素在 html 中的位置,或是在 Network 分頁中定位請求找到原始數據
經過一番觀察,我有了初步的認知:
官方的 BOOOM 遊戲列表表現為垂直滾動、動態刷新,似乎還帶有隨機排序
列表刷新是有限的,拖到最底部幾次後就完全到底、不會再有新的出來
列表中每個遊戲的信息,涵蓋了標題、封面圖(靜態/動態)、標籤,點擊可以跳轉游戲詳情頁
遊戲的詳情頁,包含更多的圖片(甚至視頻)、文字描述(遊戲介紹、下載方式、致謝詞)、下載按鈕(有的沒有)、開發者信息(有的收錄不全)
結論來說,可以爬,不過得想辦法讓爬蟲模擬人滾動列表的操作,因為這部分的數據是動態加載、每次滾到最下面才會刷新。(具體做法見會在下面展開講)
我也明確了要爬的信息,以及預想的用途:
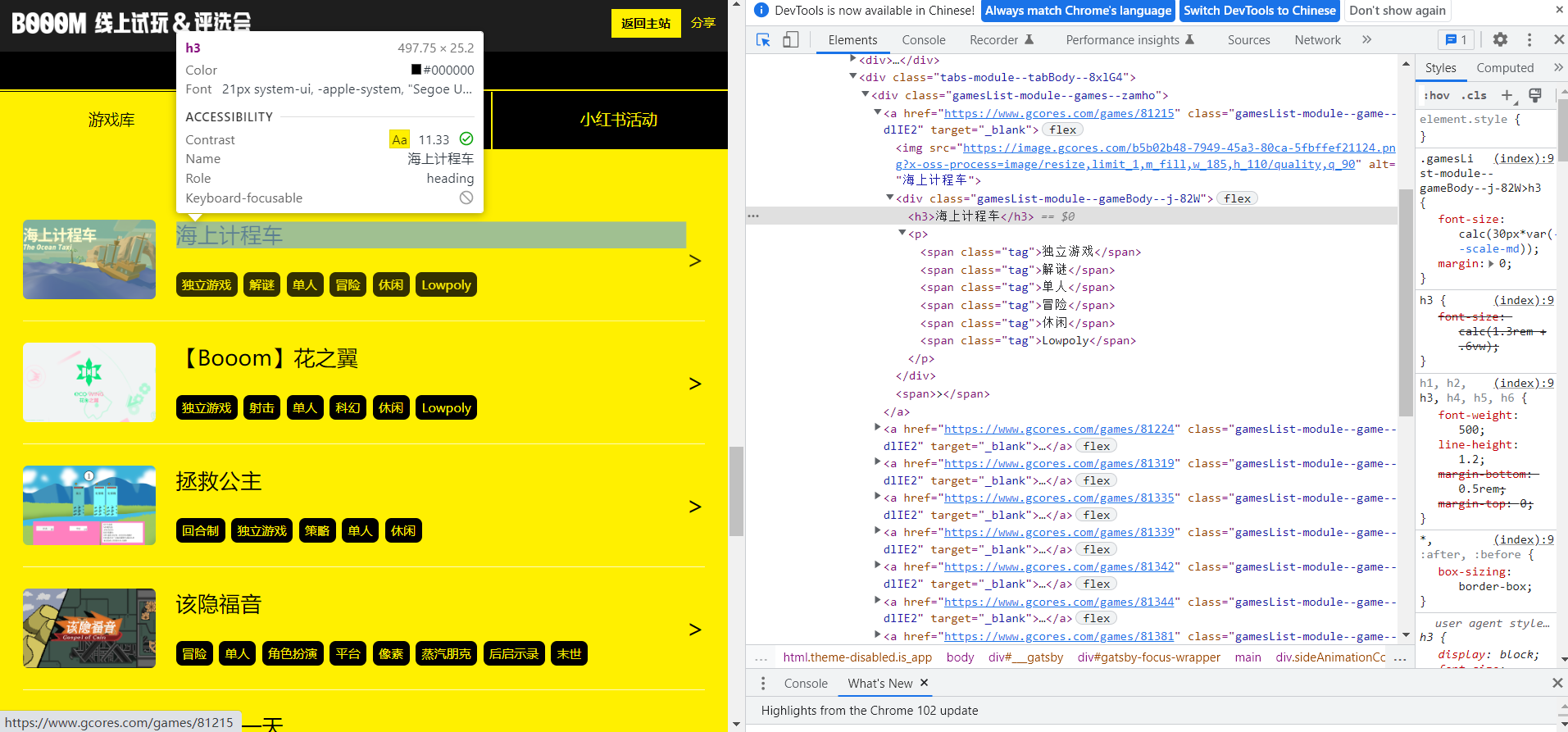
需要收集的信息,基本就是每個遊戲卡片中的這些
收集數據是可以交給爬蟲了,但數據存在哪裡?怎麼查看和使用?
我很快想到了自己常用的 Notion ,一款瑞士軍刀般的筆記軟件,集寫作、計劃、管理於一體,其中的數據庫功能,提供了豐富的數據類型和視圖預設,也支持篩選、排序、搜索,幾乎完美匹配我對 BOOOM 遊戲信息的管理需求。
Notion 官方的自我介紹:不止於一個文檔或工作臺,如何使用 Notion 由你來定
從社區的教程主題來看,Notion 也已經被髮掘了廣泛的用途,寫筆記、做計劃、任務管理、習慣打卡不在話下
定好了數據收集和儲存的方案,我也列出了接下來要做的事:
編寫爬蟲收集數據
將數據導入 Notion
在 Notion 中管理數據
編寫爬蟲收集數據
前面我也提到過,因為官方的遊戲列表是每次滾到最下面才會刷新的,我得想辦法讓爬蟲模擬人滾動列表的操作,這樣才能確保收集到全部的遊戲數據。
BOOOM 官方的遊戲列表是動態刷新的
我因此而選擇了 selenium 庫,一個常用於模擬人為操作、測試網頁的庫,用它來爬取動態頁面簡直不能更合適。
明確了技術方案後,我沒有直接開始寫代碼,而是先自上而下拆解了任務,就像項目管理中的工作拆解結構(Work Breakdown Structure,WBS),我從一個腳本的目的起步,拆解出了每一步要解決的問題:
打開 BOOOM 網頁
模擬滾動頁面,加載完所有數據
遍歷列表,提取所需的信息
將數據存入本地文件
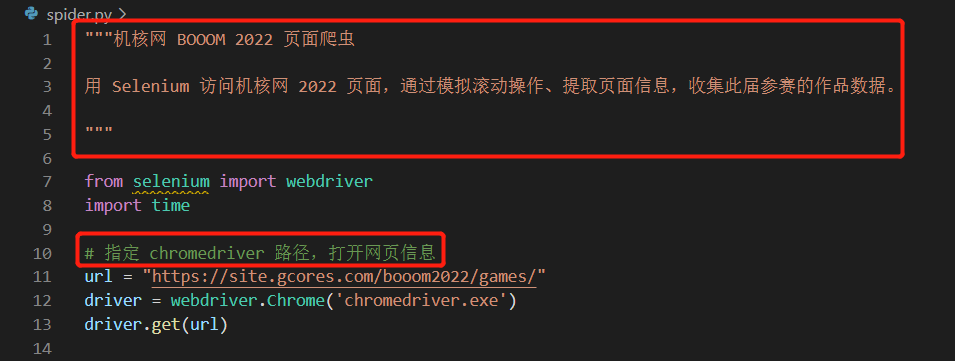
明確了每一步的任務後,啟動 Visual Studio Code(用來寫代碼的軟件),新建了一個 python 文件,然後用註釋寫明瞭腳本的目的、每一步要解決的問題。這部分參考了 Google 的 Python 代碼註釋規範 ,經過個人的實踐,發現確實能避免不少回顧代碼時的一臉懵逼。
在腳本開頭用文檔註釋寫明整個腳本的用途,其餘部分分塊註釋寫明局部代碼的用途
有了這樣大致的框架,接著就要逐個解決每步的問題了,具體的技術細節這裡略過,基本是面向搜索引擎編程,考慮到可能有人會感興趣,這裡概括一下最終是如何實現的:
打開 BOOOM 網頁 :用 selenium 啟動一個 Chrome 瀏覽器,打開 BOOOM 的活動頁
模擬滾動頁面,加載完所有數據 :用 selenium 執行 JavaScript 腳本,獲取網頁滾動高度並模擬滾動,直至滾動高度不再增加
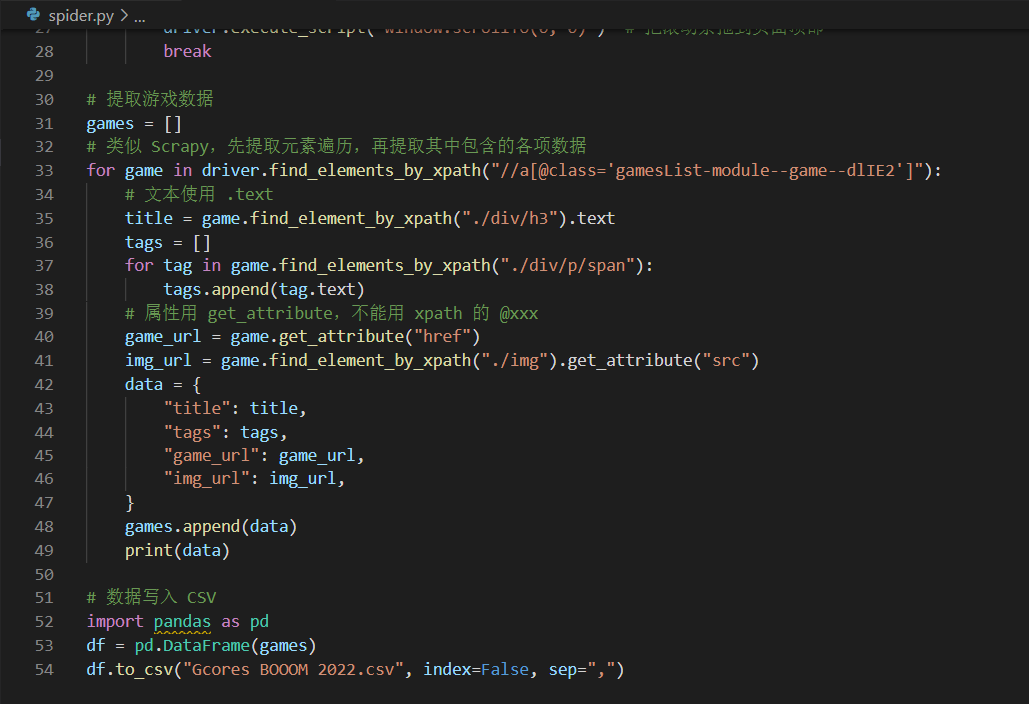
遍歷列表,提取所需的信息 :用 Xpath 表達式(一種用於在 XML 樹狀結構中定位節點的語言)定位網頁中的每一個信息塊,逐個遍歷並繼續用 Xpath 提取文本、鏈接等信息,存入列表套字典的結構裡
將數據存入本地文件 :用 pandas (一個常用於數據處理的庫)將數據導出至 CSV 文件
最終寫了 50 多行的爬蟲代碼(其中有不少是註釋和排版用的空行),運行後便收集完了此次 BOOOM 所有遊戲的數據。
爬蟲代碼可能並沒有你想象得那麼複雜,一般幾十行就能搞定了
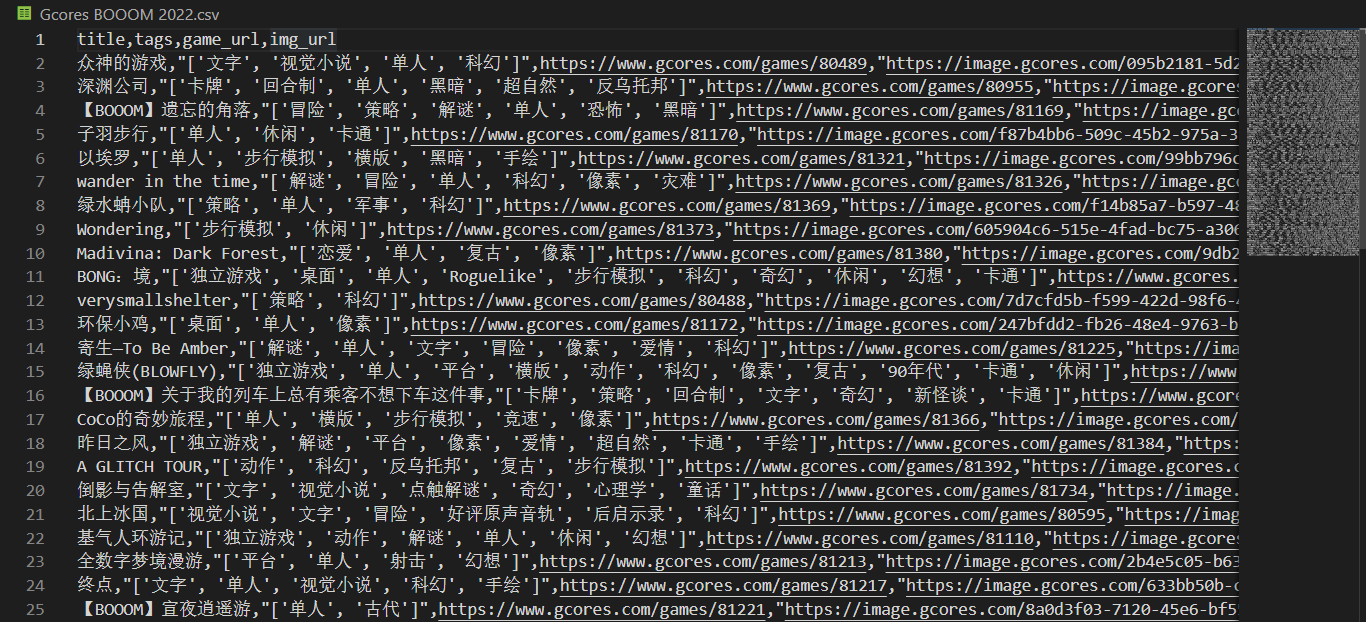
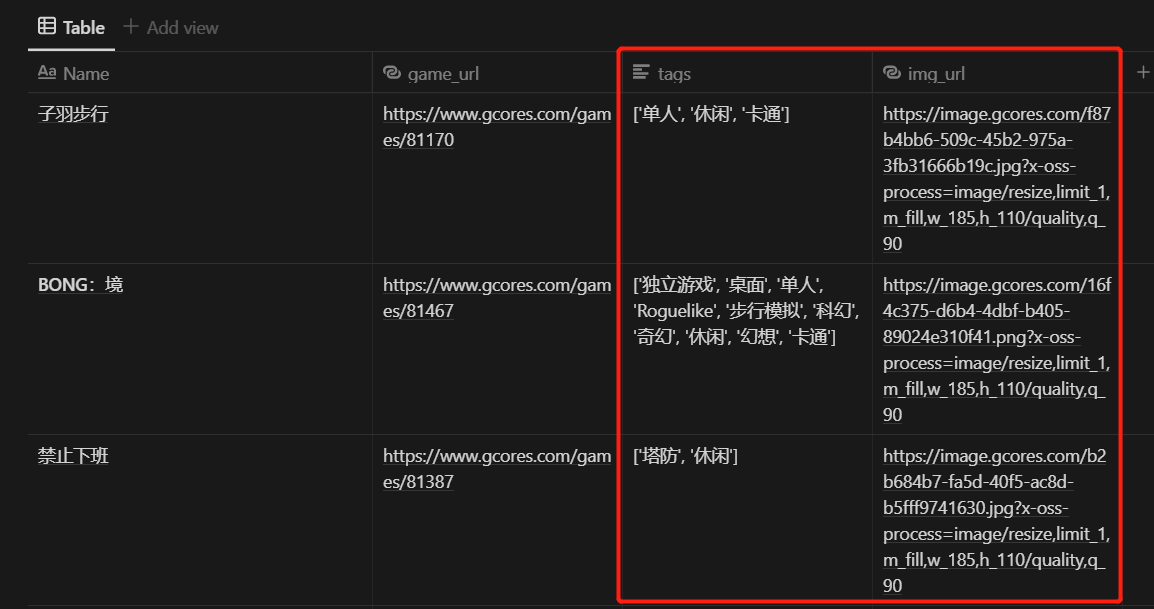
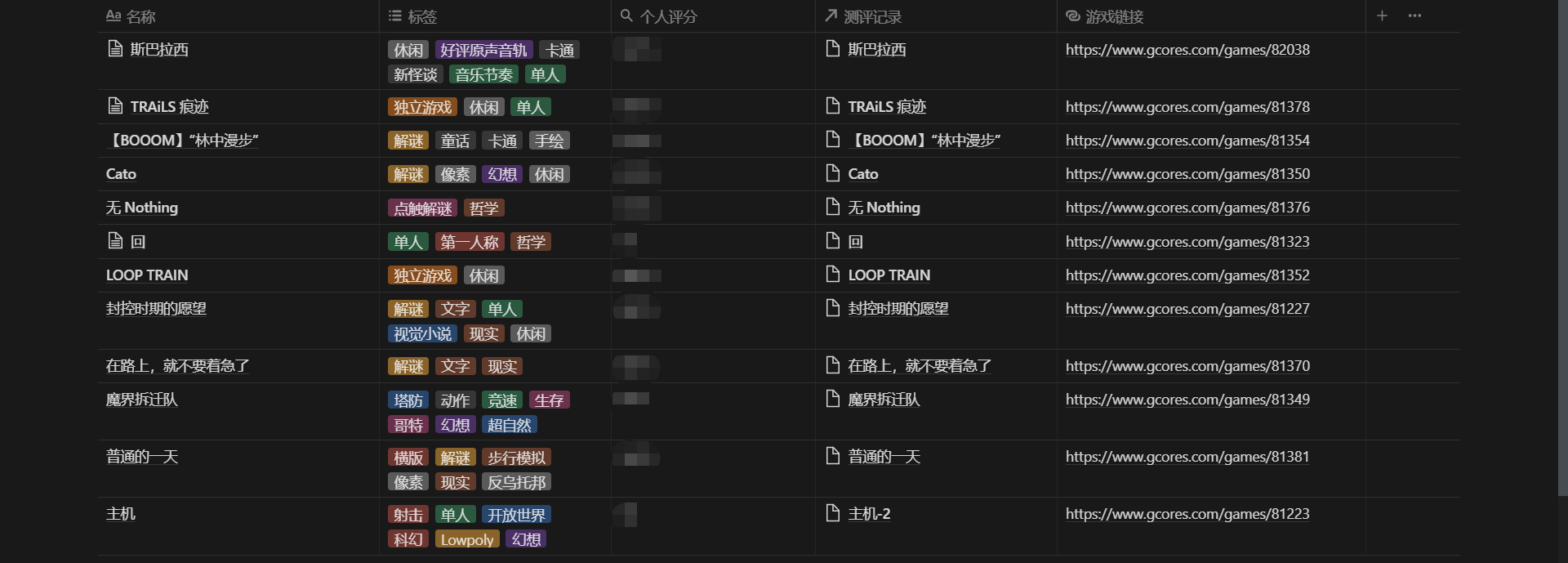
爬到的數據導出到了本地的 CSV 文件,包含了 113 個遊戲的這些數據:
title :文本,遊戲名稱
tags :列表,遊戲打上所有標籤
game_url :文本,遊戲詳情頁的鏈接
img_url :文本,遊戲封面圖的鏈接
爬蟲導出到 CSV 的數據
爬完了數據,按前面的計劃,下一步就是把這些數據導入 Notion 了。
將數據導入 Notion
用過 Notion 的朋友可能會知道,Notion 的數據庫功能是支持直接導入 CSV 的,導入後會自動補全不存在的列、設定好匹配的數據類型,但可惜的是我不能用這個功能。
問題就在於我收集的數據格式,有些是無法被 Notion 識別的,比如標籤和圖片鏈接。圖片鏈接直接導入 Notion 會被識別為鏈接(URL 屬性),而不是我希望看到的圖片(Files & media 屬性),這也意味著我之後要手動設置 100 多次圖片數據,而不巧我是一個極度厭倦重複勞動的人。
CSV 直接導入 Notion,標籤會變成文本、圖片鏈接也沒法顯示對應的圖片
於是新的問題擺在了面前,如何避免重複勞動將這批數據導入 Notion。我很快想到了 Notion API ,這是一套 Notion 官方為了方便開發者編程將 Notion 與第三方工具打通、實現自動化而公開提供的接口。這時的我已經積累了一些使用經驗、也打包了常用的函數,新寫一個導入數據的腳本並不是什麼難事。
Notion 官方對其 API 的介紹:打通 Notion 頁面、數據庫與你日常使用的工具,創建強大的工作流
類似寫爬蟲,我也拆解了這一環節的步驟,將數據導入 Notion 需要經歷兩步:
從本地文件讀取數據
逐條遍歷數據,在指定 Notion 數據庫中新建頁面
之後,針對每個步驟寫代碼實現:
這裡面比較頭疼的是數據格式的轉換,讀取到的原始數據是一個個單獨的變量,但為了讓 Notion API 能正常使用這些數據,必須嚴格按照官方要求、重新包裝成字典/列表層層嵌套的格式。
代碼裡包裝後的數據格式,明顯多出了很多層層嵌套、看得人眼花繚亂
好在 Notion 為使用 API 的開發者提供了相對完善的文檔,比如 這篇文檔 就全面列舉了各種數據類型的格式範例,讓我瞭解瞭如何通過 Files 屬性在 Notion 數據庫中插入圖片。
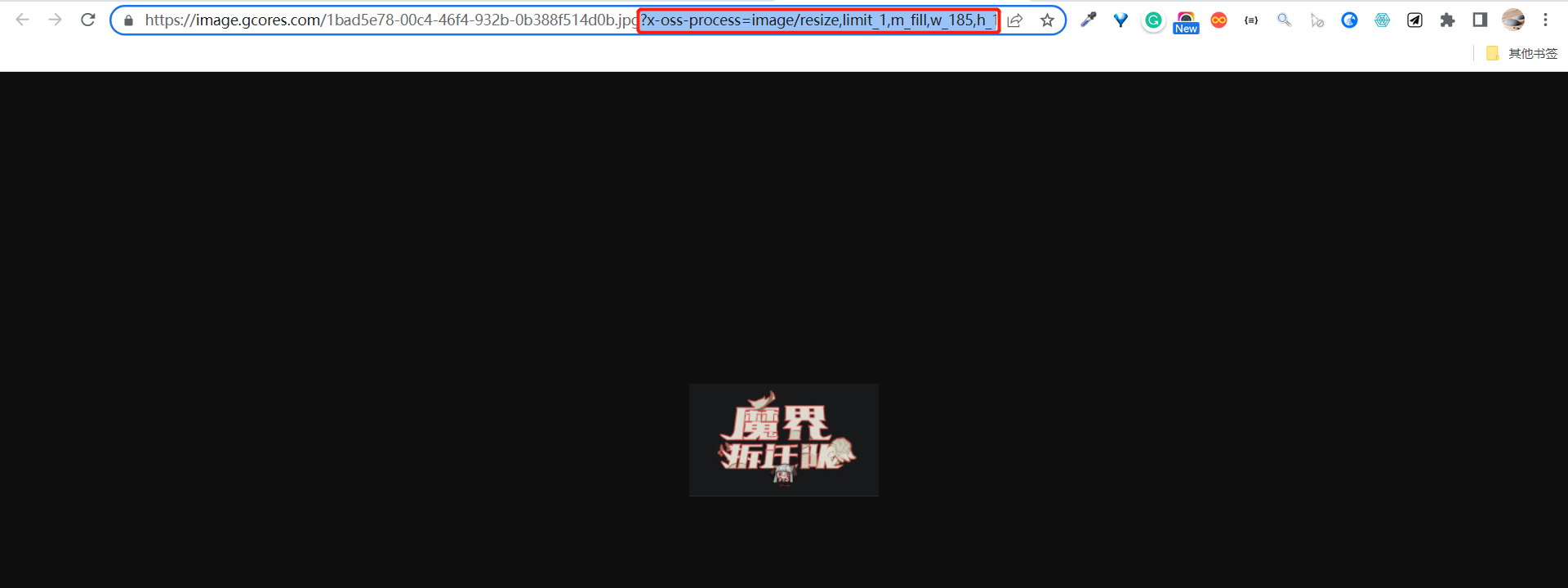
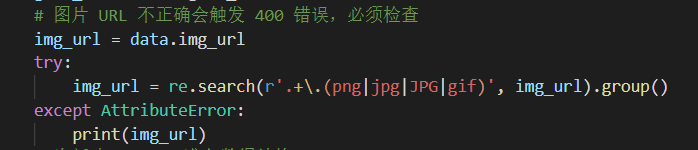
但寫代碼哪有一次就能跑通的,我也在插入圖片這步踩了坑,的確是參考官方文檔寫的,但一個頁面都沒有添加成功,最後排查下來發現是圖片鏈接有問題,Notion API 那邊無法使用帶後綴的圖片鏈接,於是我又加了一步正則匹配處理,才得以解決。
爬到的封面圖鏈接跟著一串後綴,看上去是用來裁剪縮放原始圖片的
正則提取到圖片文件名的後綴為止,圖片鏈接就可以被 Notion API 識別了
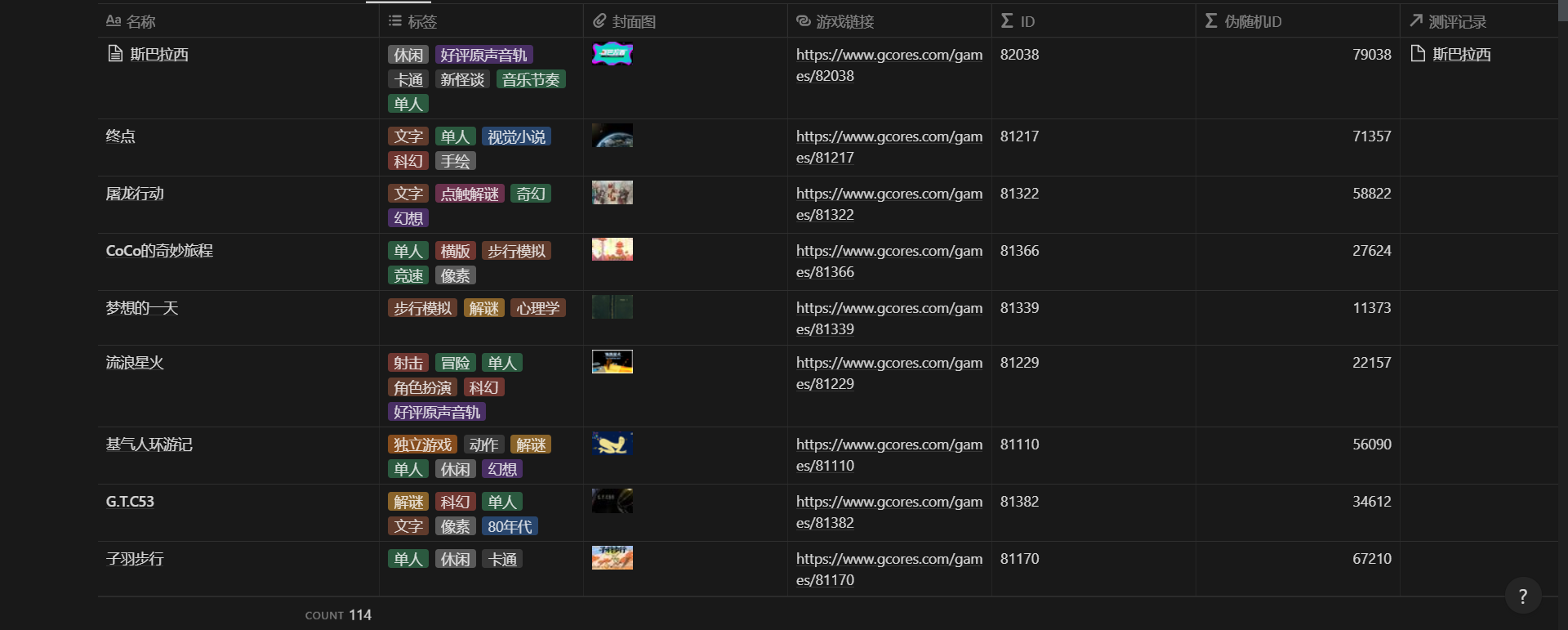
在多次測試、修復完各種大小問題後,最終成功將數據導入了 Notion。
導入 Notion 的遊戲數據
在 Notion 中管理數據
至此,Notion 的數據庫中已經保存了這些信息:
儘管遊戲庫所需的數據都已經導入,但實際用起來還是會有不同的使用案例,因而還要從不同需求出發、設計對應的數據視圖。
我從「體驗完這屆 BOOOM 所有遊戲」的目標出發,列出了這些使用案例:
圍繞體驗進度跟蹤作品
隨機瀏覽作品、找找靈感
查看已體驗作品的評分
列完後,我發現還需要建新的數據庫,因為使用案例 1 和 3 都涉及到個人試玩作品的評分,而現有數據庫管理的對象是遊戲作品,不是評分,如果硬要將評分數據存在這邊的數據庫,會使得信息管理起來過於臃腫。
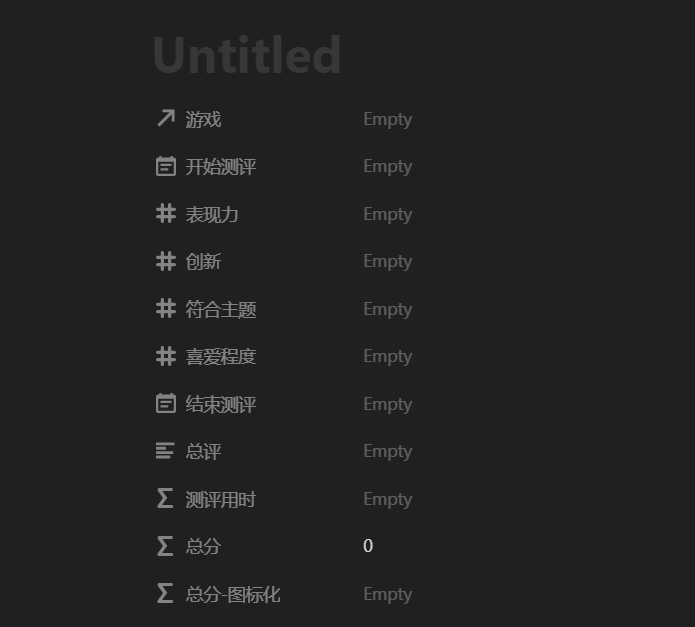
於是我又新建了一個「測評記錄」數據庫,根據試玩需要設計了數據模型:
遊戲 :關係,綁定到另一個數據庫中對應的遊戲,可以通過關係互相查表
表現力 :數值,打分用
創新 :數值,打分用
符合主題 :數值,打分用
喜愛程度 :數值,打分用
開始測評 :時間,記錄用
結束測評 :時間,記錄用
總評 :文本,概括玩法+優缺點評價+總結
測評用時 :公式輸出數值,用開始和結束時間計算遊玩了多少分鐘
總分 :公式輸出數值,綜合上面的幾項打分計算總分,各項權重暫定均等
總分-圖標化 :公式輸出文本,將總分轉為 N 顆⭐的文本
一條測評記錄會包含的數據/屬性
再回到遊戲的數據庫,參考前面羅列的使用案例,通過組合 Notion 中的視圖、篩選、排序、可見屬性,我最終創建了 4 個不同的數據視圖:
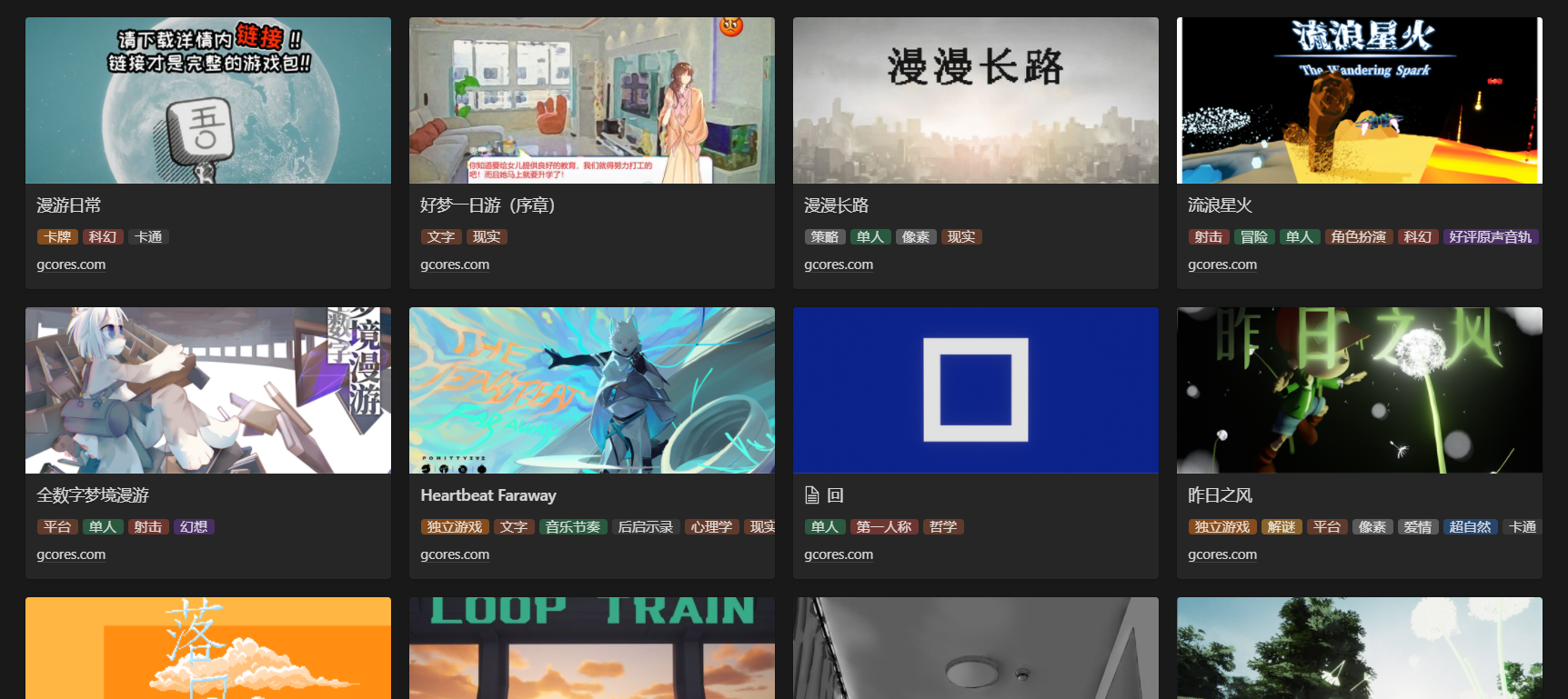
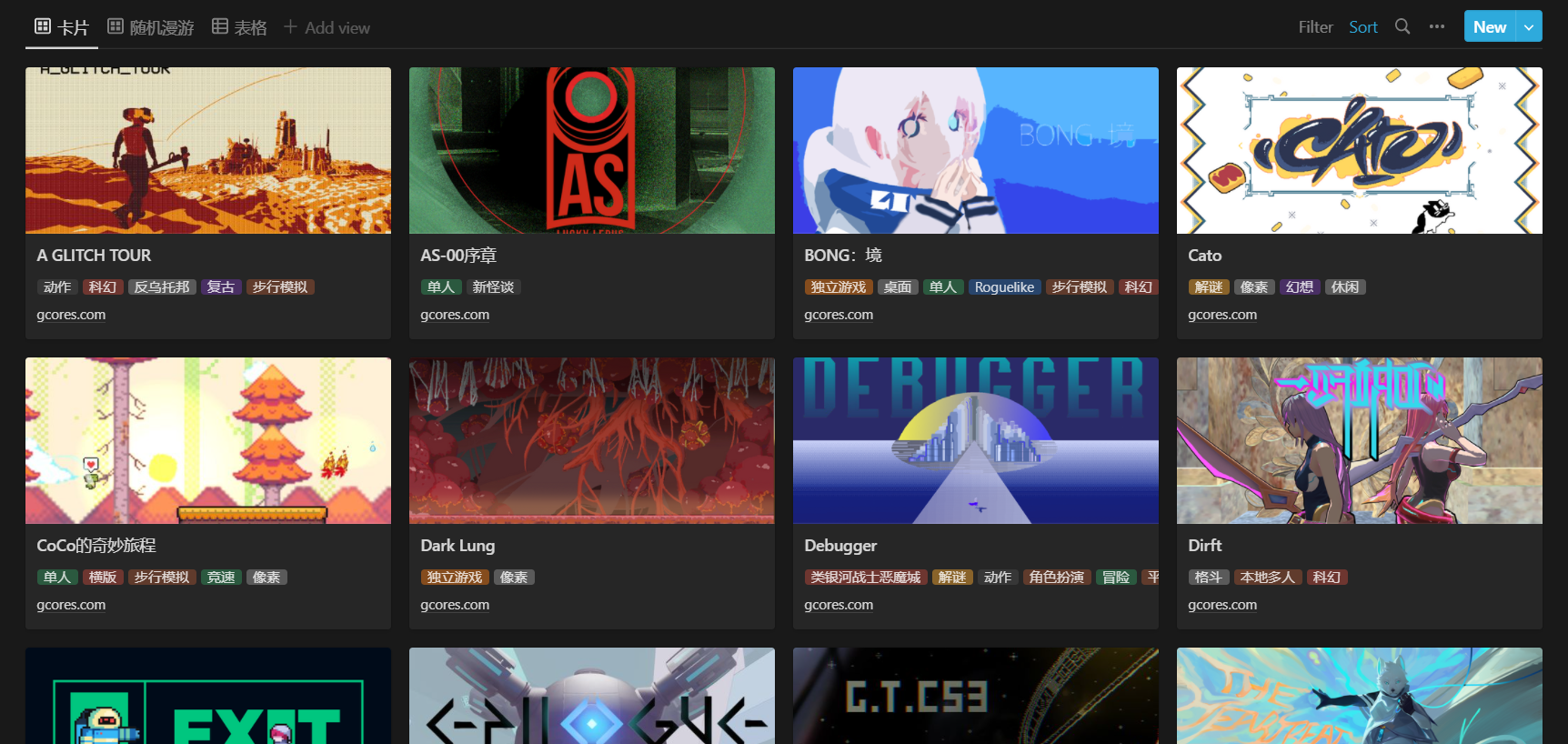
隨機漫步 :滿足「隨機瀏覽作品、找找靈感」的需求,以卡片呈現,顯示封面、標題、標籤、鏈接,偽隨機排序(每分鐘更新)
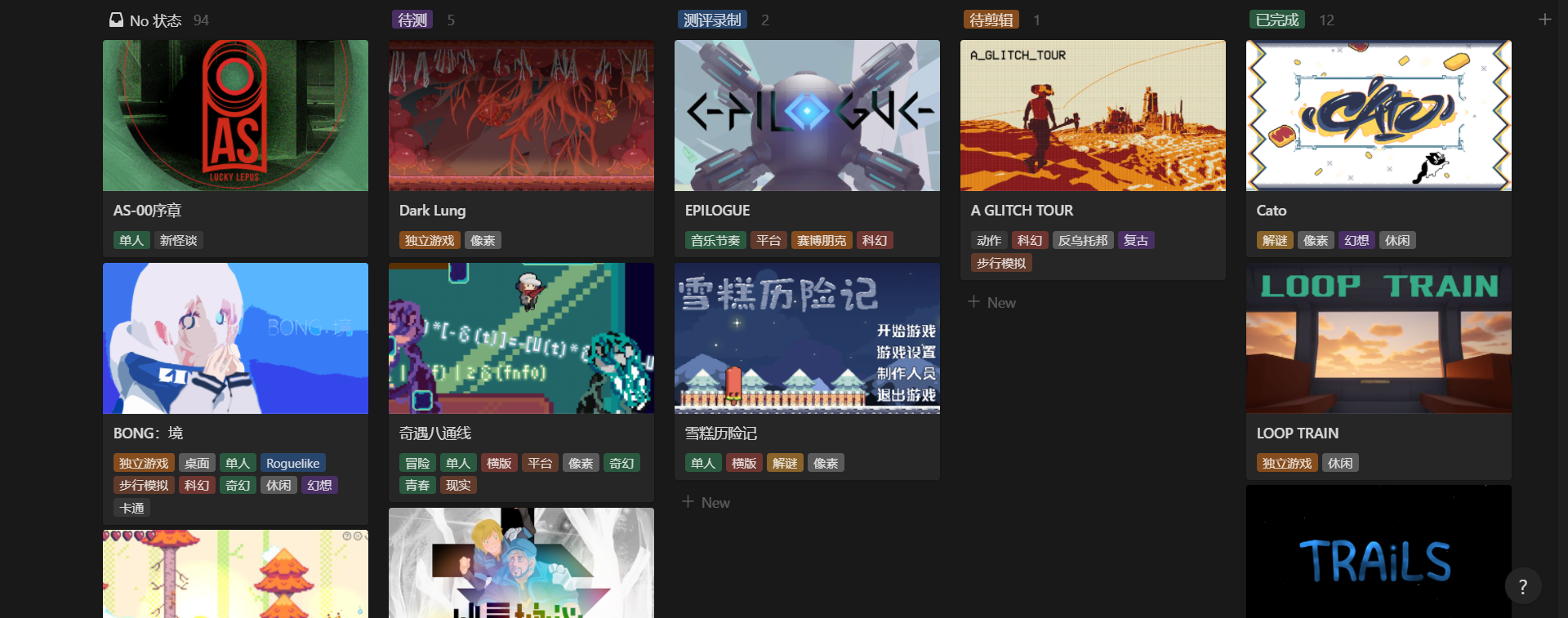
測評看板 :滿足「圍繞體驗進度跟蹤作品」的需求,看板按進度分組,顯示封面、標題、標籤
已完成 :滿足「查看已體驗作品的評分」的需求,以表格呈現,篩選已完成的、評分降序,顯示所有屬性
總表 :臨時搜索用,以表格呈現,顯示所有屬性
BOOOM 遊戲庫的各個視圖
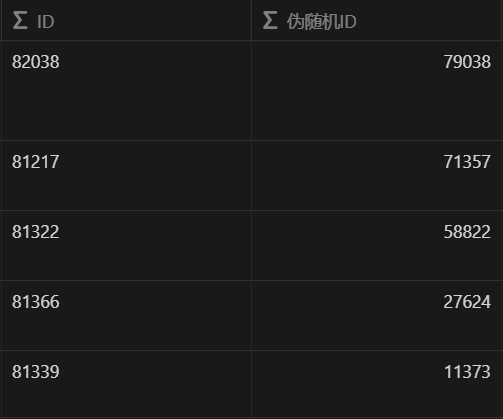
在隨機漫步視圖中,我用到了一套拍腦袋想出來的偽隨機算法,剛好實現了每分鐘重置一次列表排序。原理也很簡單,每個作品的鏈接中有唯一的數字 ID(用正則從中提取),我在公式中代入當前的時間戳(精度是毫秒,但每分鐘更新),用時間戳除 ID 取餘數,最終每個作品就都會有一個每分鐘更新、順序不固定的數字,再用這個值來排序就可以。
分享到社區
到了這一步,我自己試玩所需的數據庫已經算是搭好了,但我還準備額外做一個分享版,因為想起了自己用官方頁面的痛點:
既然我會有這樣的痛點,說不定還有其他人也會有相同的體驗,而這套遊戲庫應該也能幫到他們,發揮更大的價值。
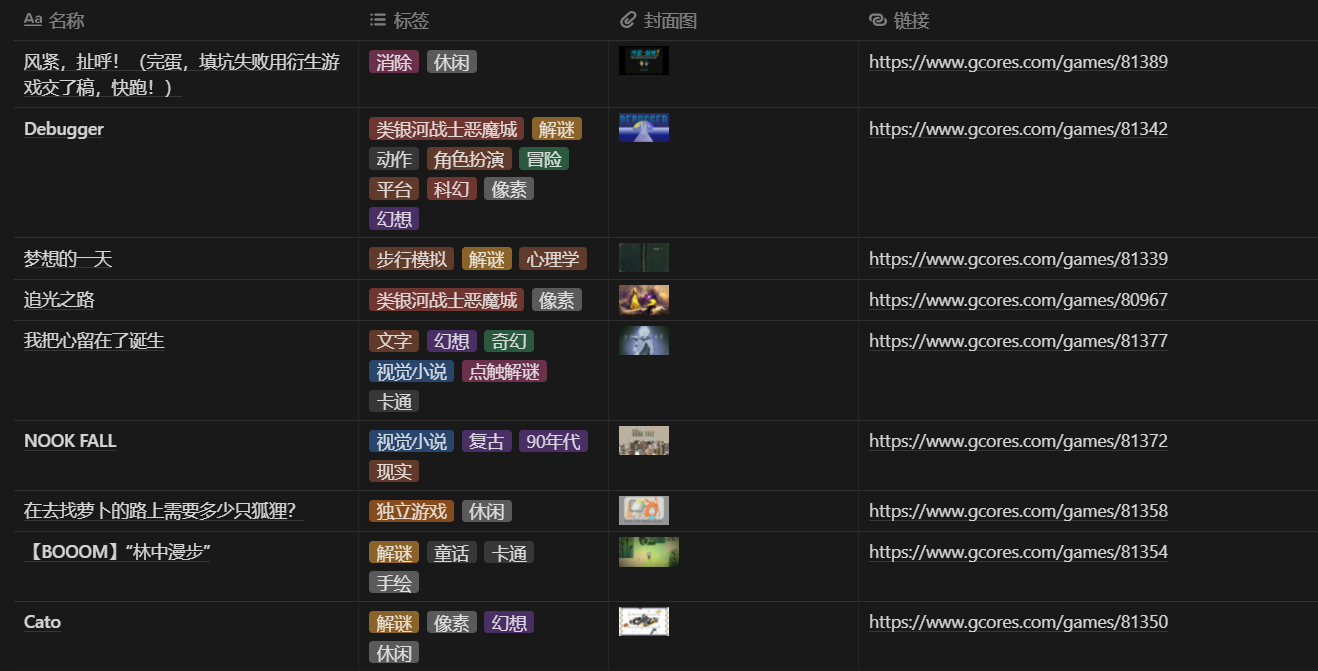
很快,我複製了一份現有的數據庫,重新配置了一套視圖:
分享版遊戲庫的卡片視圖
接著,通過 Notion 的分享功能,我將這個新遊戲庫公開分享到了網絡,開啟了評論、搜索引擎檢索,然後在機核發了條動態帶上分享鏈接,將其分享了出來。
當時分享遊戲庫的機核動態
總結
在發完那條動態後,我也有了一些意料之外的收穫。
我收到了來自這屆 BOOOM 開發者的點贊,《Cato》的開發者 Blasin-Ree 在動態下評論,說這套遊戲庫比官方的方便,讓我著實高興了好一會。
來自《Cato》開發者的點贊
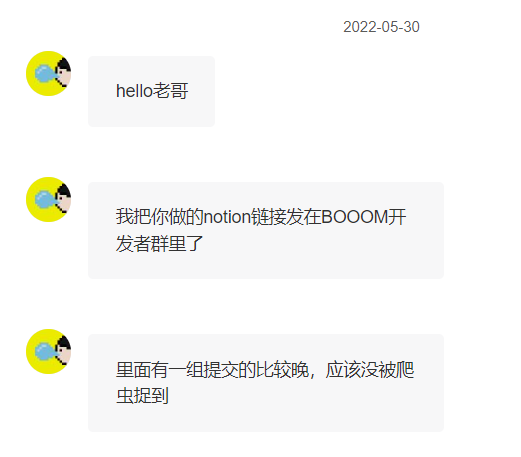
之後,《TRAiLS》的開發者 SleepyJeff 也找到了我,他幫我把這套遊戲庫的鏈接轉發到了 BOOOM 開發者的群裡,但發現有一個作品被漏掉了,可能是這組提交的比較晚、導致沒被爬蟲收集到。
熱心的 SleepyJeff 幫忙反饋了被漏掉的作品
我瞭解後,也去排查了一波,確認當時的官方列表裡依然沒收錄到這個作品,於是幫忙手動補錄了信息。這個作品是 《斯巴拉西》 ,我之後試玩到發現美術很棒、完成度也很高的一個音遊作品,希望這波補錄有幫到他們。
推薦去玩一玩《斯巴拉西》,很有趣的一個音遊作品
還有一個意外收穫,就是開頭提到的被一個叫西蒙的人關注了,我後來才知道他是誰。
回顧這次的 BOOOM 遊戲庫搭建,我學到了這些:
爬蟲收集的數據若需要持續訪問、使用,量級不大時可以考慮導入 Notion
在代碼註釋中點明目的,比點明做了什麼更有助於幫助回顧
將圍繞某個使用場景的常用函數打包,能讓後續的開發更省事
涉及到重複操作 Notion 數據庫時,可以考慮用 Notion API 做自動化
個人項目的產物可能也對他人有所幫助,多考慮分享
最後,我想感謝 Blasin-Ree 的點贊、SleepyJeff 的熱心聯繫,還有西蒙的關注。
如果你對這個遊戲庫感興趣,可以點擊 這裡 訪問。
什麼,你想問我這一百多款遊戲體驗得怎麼樣了?
……
……
……
在玩了,我這就去繼續玩。