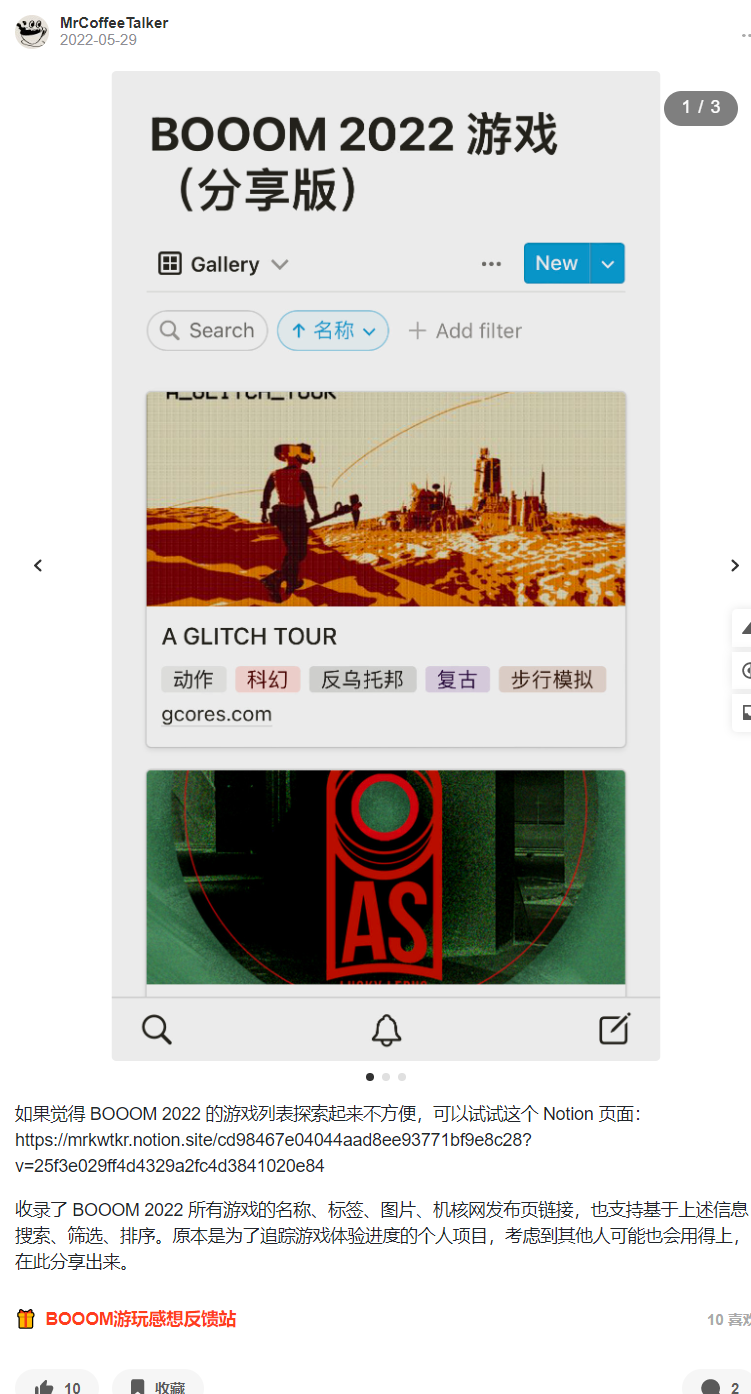
5 月底的那天,我发了一条动态「定一个小目标:体验完这次 BOOOM 2022 参赛的 113 个作品,为每一款游戏写评价、发布对应的游玩视频。」
同一天稍晚,我陷入了疑惑:「这个点赞的西蒙是谁啊?名字好像有点眼熟。」
后来去搜了下,才发现是「那个西蒙」。
之所具体到 113 个作品,并非是我看过官方公开的详细数目,又或是我一个个的数过,而是因为我在更早前,将这些作品的信息收集了下来,放在了一个 游戏库 中。如果说自己为什么会这么做,我想到的是去年年底的那次核聚变。
早前做的游戏库,收录了这届 BOOOM 所有作品的信息
那是我第一次参加线下的游戏展会,刚好有朋友做过核聚变的志愿者,推荐之下了解到这个活动。兴致冲冲的我预订了两天的门票,前一天晚上在书店研究出展的游戏信息到几近通宵,只为提前规划、以便两天内能更多的了解感兴趣的游戏。尽管第一天在找入口时废了不少时间,但两天游览下来,可以说是充满了难忘的回忆。
核聚变前一天,我在书店熬夜整理了参展游戏信息,提前标注了感兴趣的游戏
也是在这一次展会中,我第一次了解到了 BOOOM。
依稀记得那个黄黑色的展区,在场地中格外显眼。在好奇心的驱使下,我去围观了一番,当时玩了一个有关时间神庙的解谜游戏,和现场的开发者交流了游玩体验。之后看到隔壁配套 DIY 手柄的解谜游戏,被一群人围得水泄不通,也在心中下定决心,想着第二天一定要去上手玩玩看。
我也还记得第一天找入口找了半天,没有箭头指引,哪里是“前”?
然而我终归是低估了大家的热情,第二天那个摊位附近依然围满了人,眼看着就剩下不到一天的游览时间,我便和同行的朋友转去刷了一下午的抽奖任务,抽完奖后,刚好在隔壁买了一个机组成员的背包,当时好像是要先线上下单、再线下取货,便由此下载了机核的 app。
虽然刷完了抽奖任务,游览了不少游戏摊位,但心里总感觉像是缺了一块什么。
时光辗转,半年过去,我正因兴趣研究着游戏的宣传片制作,积累了一些想要分享的知识,便开始评估自己已知的几个平台。最终我选择了机核,因为看上去社区讨论氛围最好、图文也比较符合自己的创作偏好,准备先发一篇有关如何制作宣传片的综述性译介(就是后来的 这篇 )。当我打开 APP 想摸索如何投稿时,偶然刷到了 BOOOM 的推送,也想起了上一次线下试玩的遗憾。
我突然有了一个想法,「体验完这届 BOOOM 的所有游戏」,但要体验所有的 BOOOM 作品,首先我得知道最终征集到了多少个作品。经过随后的一系列折腾,我成功在当天内搭建好了一个游戏库,收录完了 BOOOM 2022 的所有游戏信息。
在这篇文章中,我将回顾自己搭建这个游戏库的历程,如果你对数据收集、效率提升或信息管理感兴趣,或许也能为你解锁一些新知识。
评估实现方案
在机核已经提供了 BOOOM 游戏列表 的情况下,数据的来源可以说是很明确了,直接从官方的页面中获取就可以。摆在开头的问题是:如何收集这些数据?收集后又要如何储存和呈现?
BOOOM 官方页面的游戏列表
如果游戏量不多,比如只有十几个,那我还可以考虑人工收集一下,但扫一眼 BOOOM 的页面便知,这次总共征集到了百余款作品。如果人工收集一个游戏要 1 分钟,怎么说也得两小时,而且这是一个高度机械重复的工作,很难保证做到中途会不会丧失动力和兴趣,因而我最好考虑更高效的方案。
恰好我对 Python 爬虫略有了解,便想到用爬虫来收集数据,这样不单单能了解「有多少个作品」,连每个作品相关的名称、类型、链接等信息都能一并收录。但是否能爬、如何爬,取决于目标网页的情况。
为此,我需要从爬虫开发的角度评估 BOOOM 的活动页面,我通常会关注的点包括:
需要哪些数据 :比如文本、链接、图片,这部分会影响到数据提取的方式,以及后续如何储存这些数据
选用哪一种爬虫库 :取决于页面数据的加载方式(静态/动态)、是否需要登录、爬取逻辑的复杂度(加载更多/自动翻页/跳转新页面)等,我通常考虑的库有 scrapy、selenium 和 requests
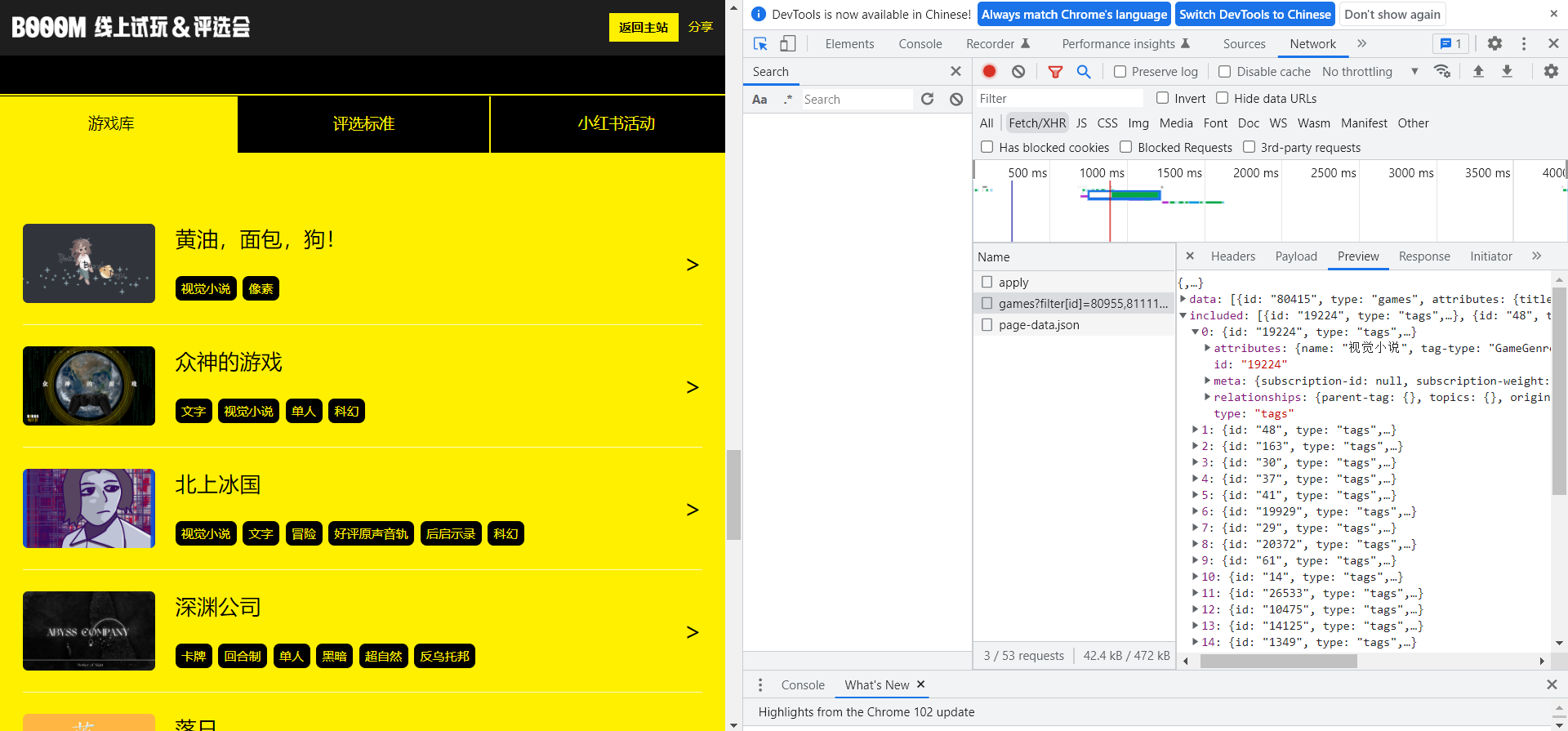
是否有可能不用写爬虫 :比如如果能通过 Chrome Network 调试找到发送数据的请求、又比较方便手动构造是最好的,因为能拿到干净的 json 数据,而且又省事
写爬虫之前,我会先打开 Chrome 浏览器的开发者模式,审查页面元素在 html 中的位置,或是在 Network 分页中定位请求找到原始数据
经过一番观察,我有了初步的认知:
官方的 BOOOM 游戏列表表现为垂直滚动、动态刷新,似乎还带有随机排序
列表刷新是有限的,拖到最底部几次后就完全到底、不会再有新的出来
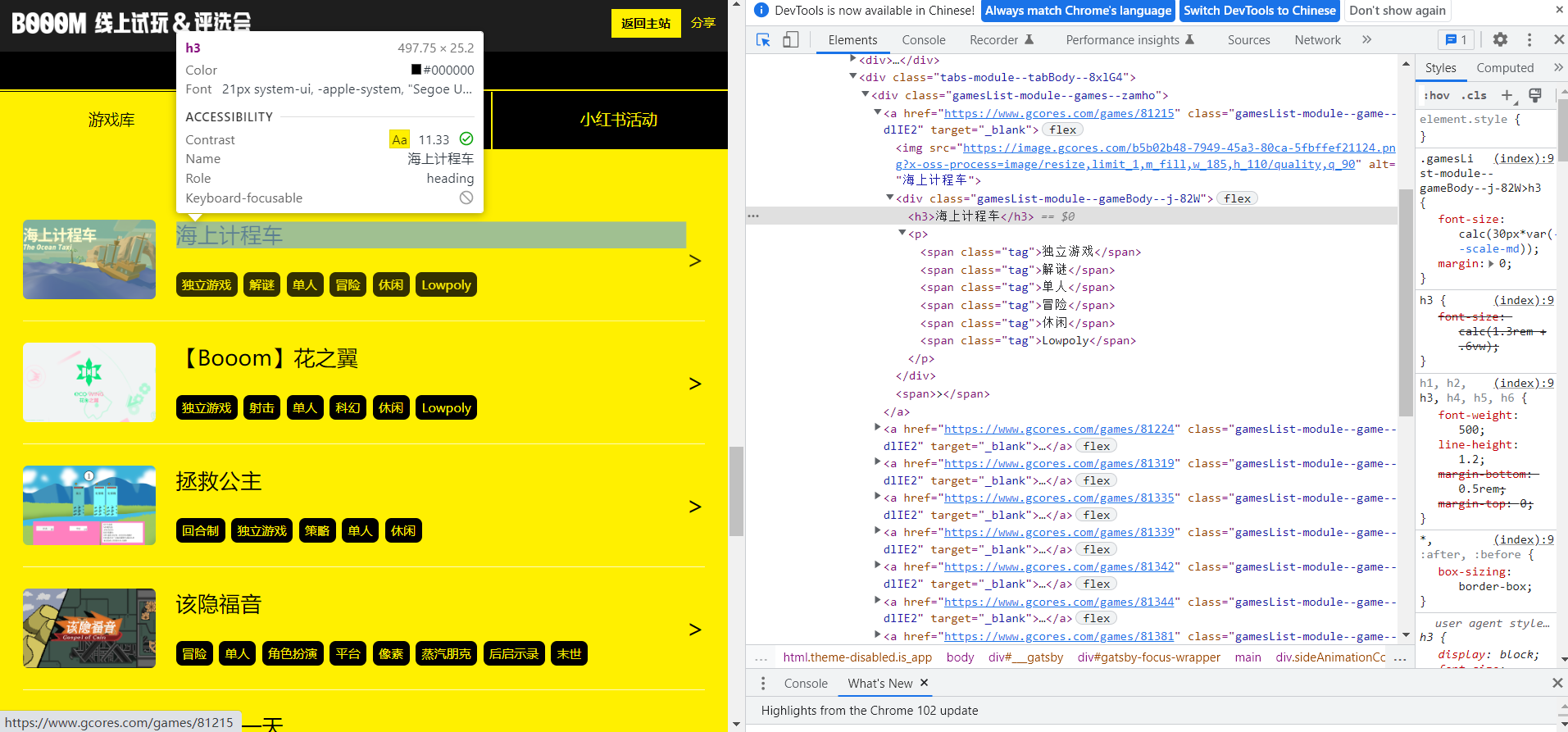
列表中每个游戏的信息,涵盖了标题、封面图(静态/动态)、标签,点击可以跳转游戏详情页
游戏的详情页,包含更多的图片(甚至视频)、文字描述(游戏介绍、下载方式、致谢词)、下载按钮(有的没有)、开发者信息(有的收录不全)
结论来说,可以爬,不过得想办法让爬虫模拟人滚动列表的操作,因为这部分的数据是动态加载、每次滚到最下面才会刷新。(具体做法见会在下面展开讲)
我也明确了要爬的信息,以及预想的用途:
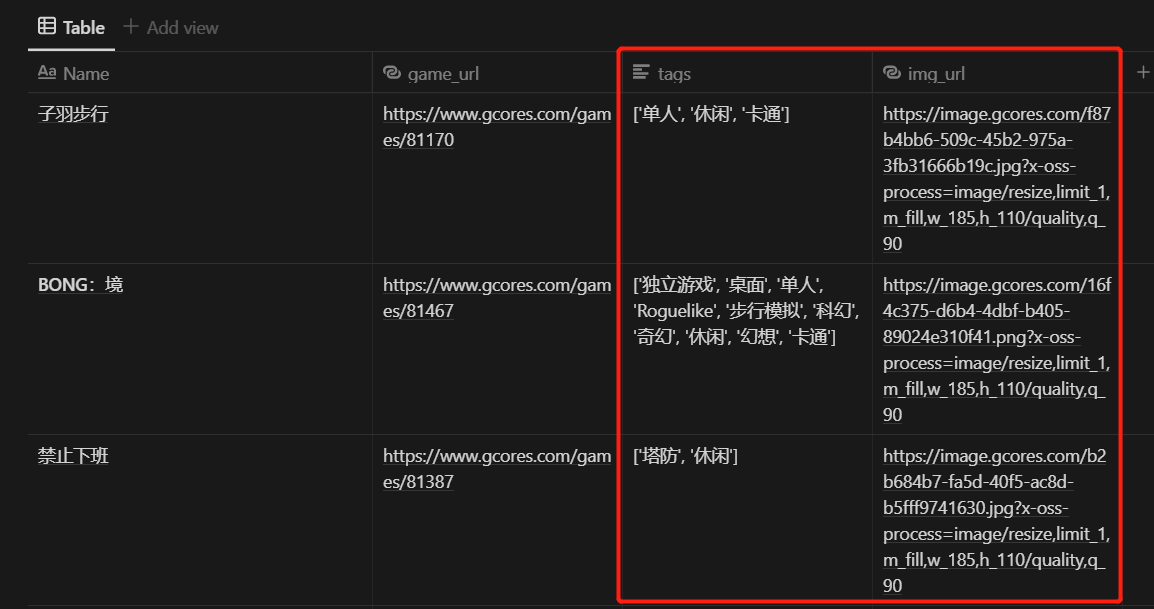
需要收集的信息,基本就是每个游戏卡片中的这些
收集数据是可以交给爬虫了,但数据存在哪里?怎么查看和使用?
我很快想到了自己常用的 Notion ,一款瑞士军刀般的笔记软件,集写作、计划、管理于一体,其中的数据库功能,提供了丰富的数据类型和视图预设,也支持筛选、排序、搜索,几乎完美匹配我对 BOOOM 游戏信息的管理需求。
Notion 官方的自我介绍:不止于一个文档或工作台,如何使用 Notion 由你来定
从社区的教程主题来看,Notion 也已经被发掘了广泛的用途,写笔记、做计划、任务管理、习惯打卡不在话下
定好了数据收集和储存的方案,我也列出了接下来要做的事:
编写爬虫收集数据
将数据导入 Notion
在 Notion 中管理数据
编写爬虫收集数据
前面我也提到过,因为官方的游戏列表是每次滚到最下面才会刷新的,我得想办法让爬虫模拟人滚动列表的操作,这样才能确保收集到全部的游戏数据。
BOOOM 官方的游戏列表是动态刷新的
我因此而选择了 selenium 库,一个常用于模拟人为操作、测试网页的库,用它来爬取动态页面简直不能更合适。
明确了技术方案后,我没有直接开始写代码,而是先自上而下拆解了任务,就像项目管理中的工作拆解结构(Work Breakdown Structure,WBS),我从一个脚本的目的起步,拆解出了每一步要解决的问题:
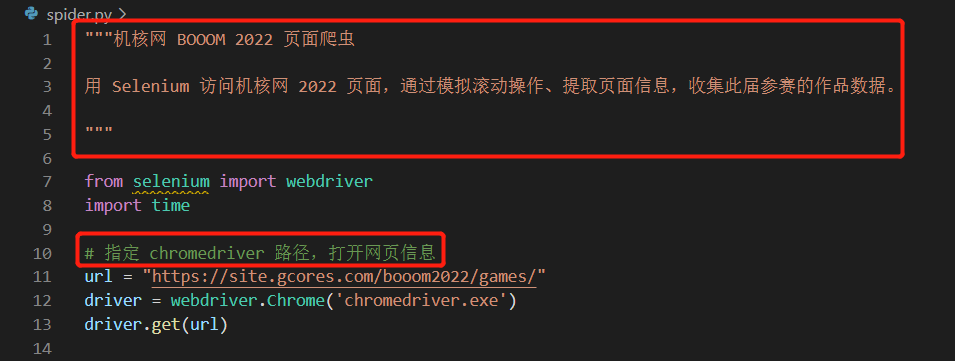
打开 BOOOM 网页
模拟滚动页面,加载完所有数据
遍历列表,提取所需的信息
将数据存入本地文件
明确了每一步的任务后,启动 Visual Studio Code(用来写代码的软件),新建了一个 python 文件,然后用注释写明了脚本的目的、每一步要解决的问题。这部分参考了 Google 的 Python 代码注释规范 ,经过个人的实践,发现确实能避免不少回顾代码时的一脸懵逼。
在脚本开头用文档注释写明整个脚本的用途,其余部分分块注释写明局部代码的用途
有了这样大致的框架,接着就要逐个解决每步的问题了,具体的技术细节这里略过,基本是面向搜索引擎编程,考虑到可能有人会感兴趣,这里概括一下最终是如何实现的:
打开 BOOOM 网页 :用 selenium 启动一个 Chrome 浏览器,打开 BOOOM 的活动页
模拟滚动页面,加载完所有数据 :用 selenium 执行 JavaScript 脚本,获取网页滚动高度并模拟滚动,直至滚动高度不再增加
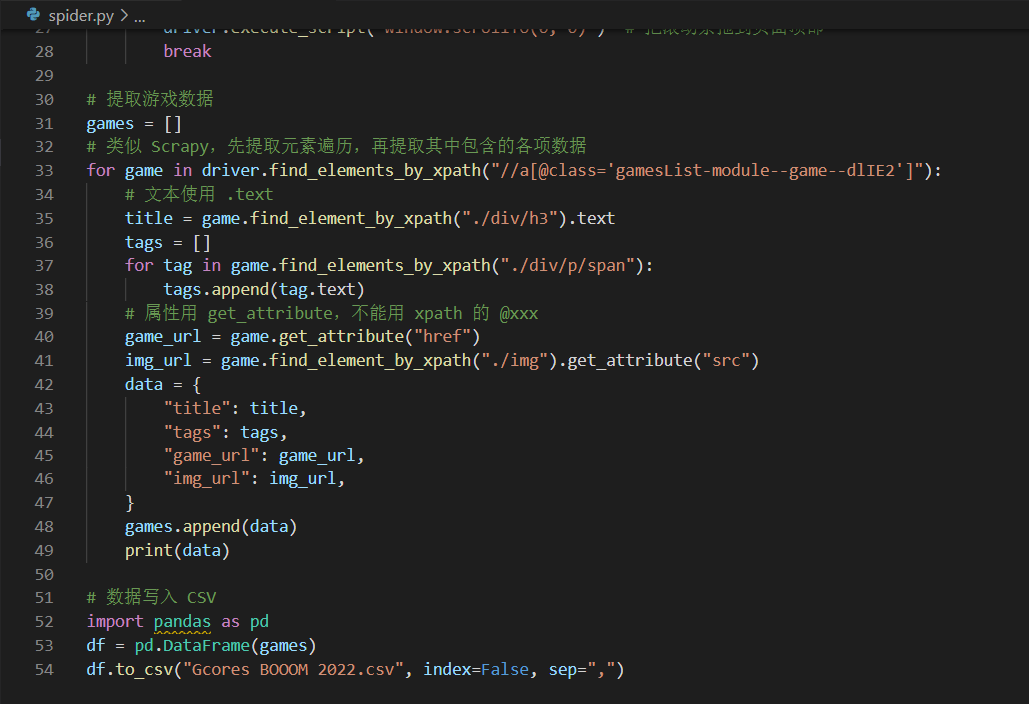
遍历列表,提取所需的信息 :用 Xpath 表达式(一种用于在 XML 树状结构中定位节点的语言)定位网页中的每一个信息块,逐个遍历并继续用 Xpath 提取文本、链接等信息,存入列表套字典的结构里
将数据存入本地文件 :用 pandas (一个常用于数据处理的库)将数据导出至 CSV 文件
最终写了 50 多行的爬虫代码(其中有不少是注释和排版用的空行),运行后便收集完了此次 BOOOM 所有游戏的数据。
爬虫代码可能并没有你想象得那么复杂,一般几十行就能搞定了
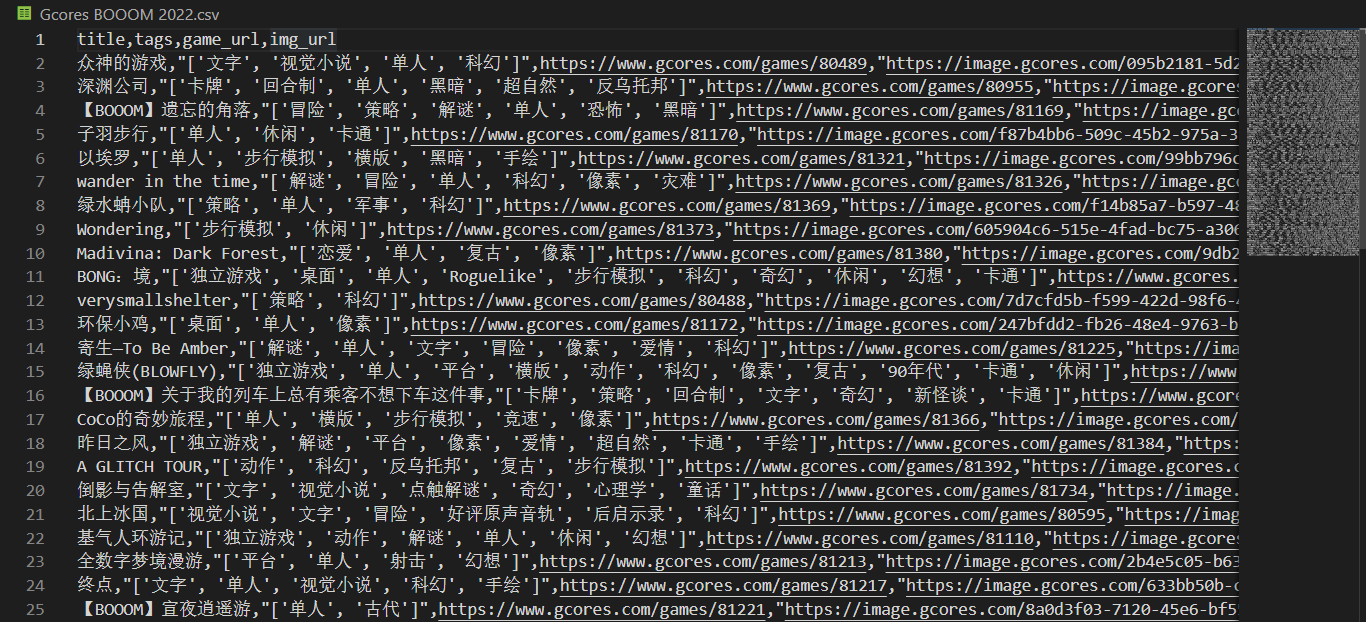
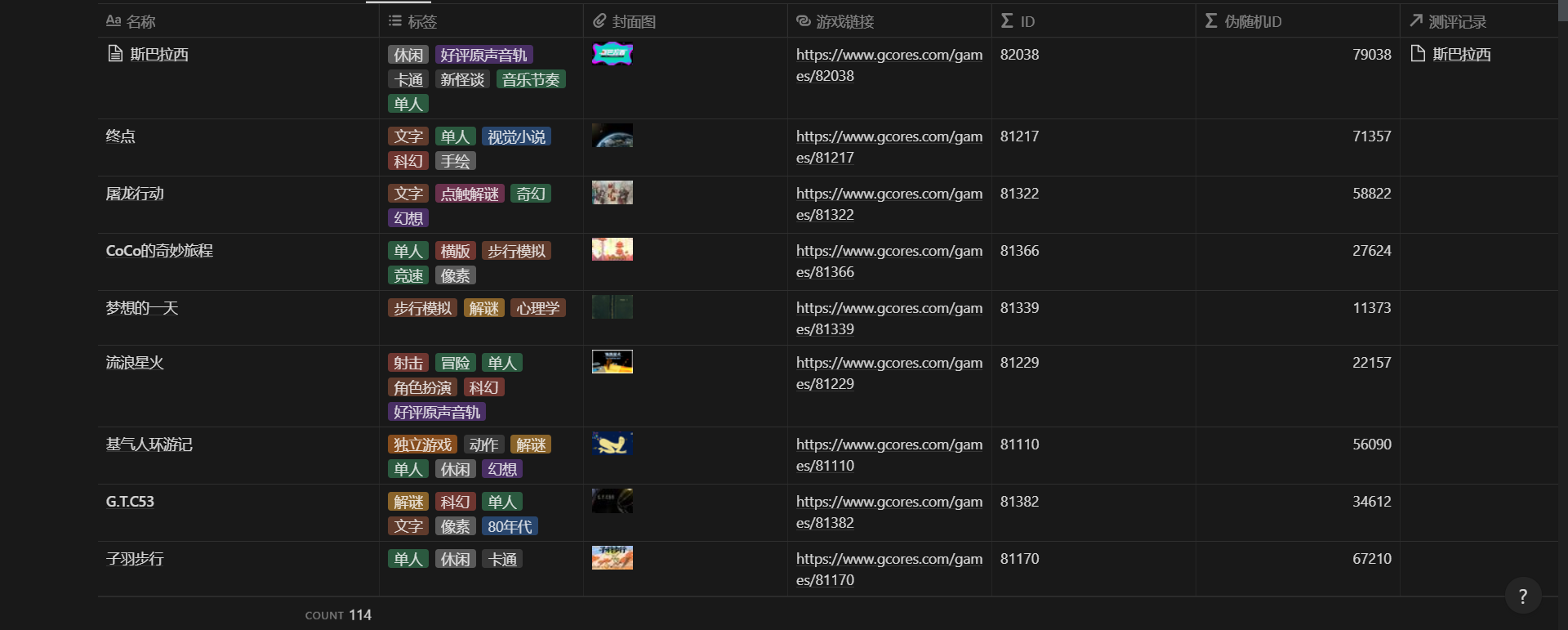
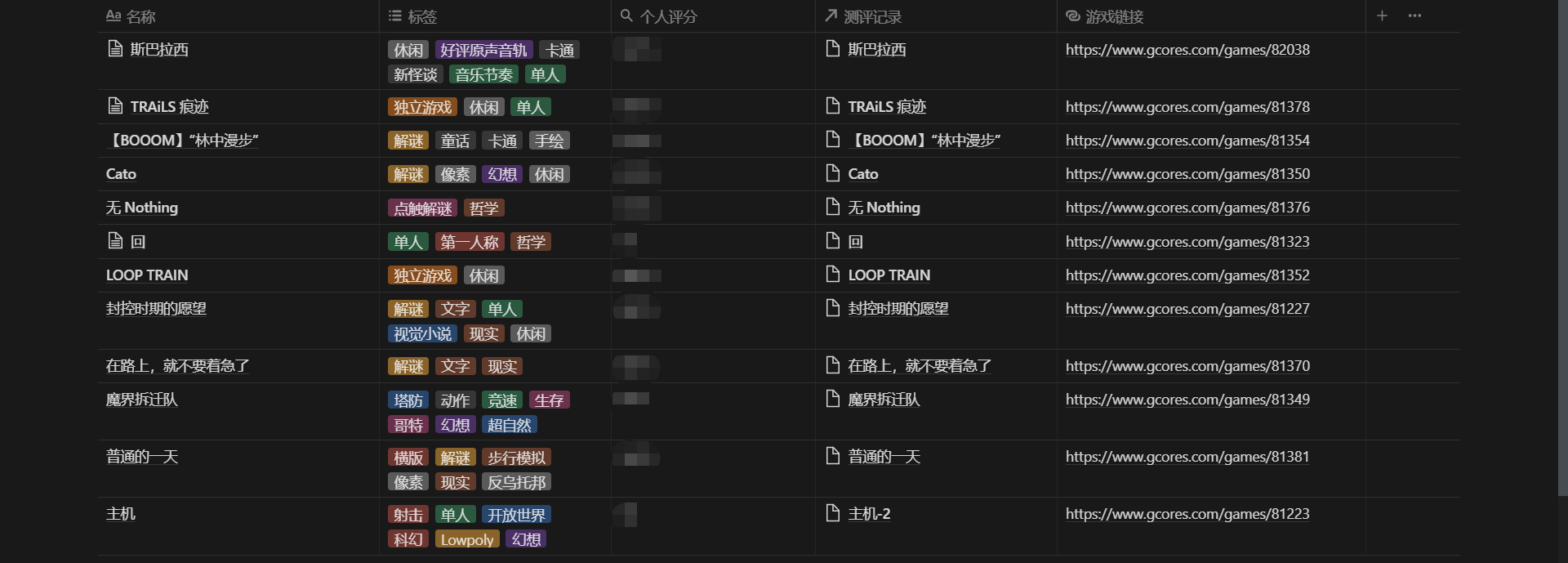
爬到的数据导出到了本地的 CSV 文件,包含了 113 个游戏的这些数据:
title :文本,游戏名称
tags :列表,游戏打上所有标签
game_url :文本,游戏详情页的链接
img_url :文本,游戏封面图的链接
爬虫导出到 CSV 的数据
爬完了数据,按前面的计划,下一步就是把这些数据导入 Notion 了。
将数据导入 Notion
用过 Notion 的朋友可能会知道,Notion 的数据库功能是支持直接导入 CSV 的,导入后会自动补全不存在的列、设定好匹配的数据类型,但可惜的是我不能用这个功能。
问题就在于我收集的数据格式,有些是无法被 Notion 识别的,比如标签和图片链接。图片链接直接导入 Notion 会被识别为链接(URL 属性),而不是我希望看到的图片(Files & media 属性),这也意味着我之后要手动设置 100 多次图片数据,而不巧我是一个极度厌倦重复劳动的人。
CSV 直接导入 Notion,标签会变成文本、图片链接也没法显示对应的图片
于是新的问题摆在了面前,如何避免重复劳动将这批数据导入 Notion。我很快想到了 Notion API ,这是一套 Notion 官方为了方便开发者编程将 Notion 与第三方工具打通、实现自动化而公开提供的接口。这时的我已经积累了一些使用经验、也打包了常用的函数,新写一个导入数据的脚本并不是什么难事。
Notion 官方对其 API 的介绍:打通 Notion 页面、数据库与你日常使用的工具,创建强大的工作流
类似写爬虫,我也拆解了这一环节的步骤,将数据导入 Notion 需要经历两步:
从本地文件读取数据
逐条遍历数据,在指定 Notion 数据库中新建页面
之后,针对每个步骤写代码实现:
这里面比较头疼的是数据格式的转换,读取到的原始数据是一个个单独的变量,但为了让 Notion API 能正常使用这些数据,必须严格按照官方要求、重新包装成字典/列表层层嵌套的格式。
代码里包装后的数据格式,明显多出了很多层层嵌套、看得人眼花缭乱
好在 Notion 为使用 API 的开发者提供了相对完善的文档,比如 这篇文档 就全面列举了各种数据类型的格式范例,让我了解了如何通过 Files 属性在 Notion 数据库中插入图片。
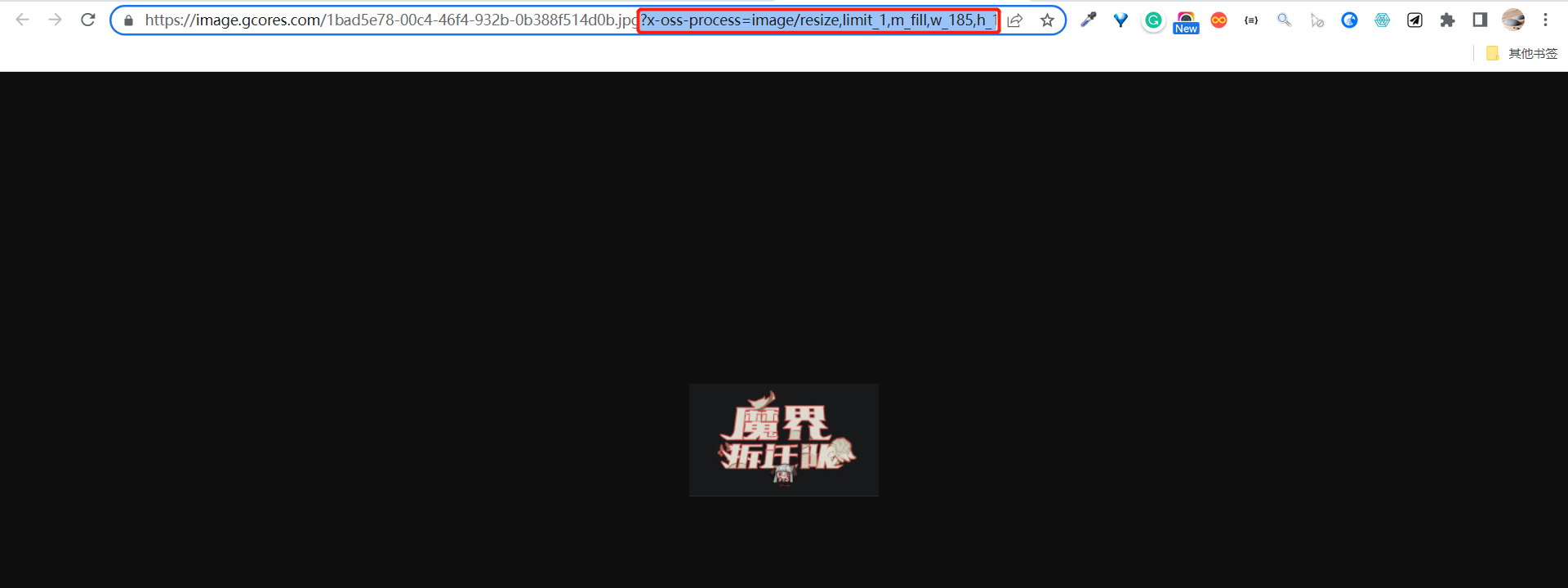
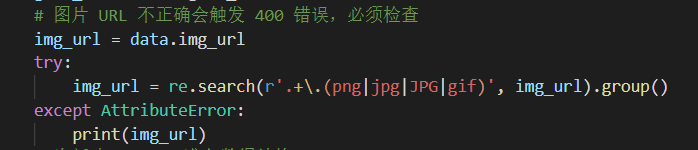
但写代码哪有一次就能跑通的,我也在插入图片这步踩了坑,的确是参考官方文档写的,但一个页面都没有添加成功,最后排查下来发现是图片链接有问题,Notion API 那边无法使用带后缀的图片链接,于是我又加了一步正则匹配处理,才得以解决。
爬到的封面图链接跟着一串后缀,看上去是用来裁剪缩放原始图片的
正则提取到图片文件名的后缀为止,图片链接就可以被 Notion API 识别了
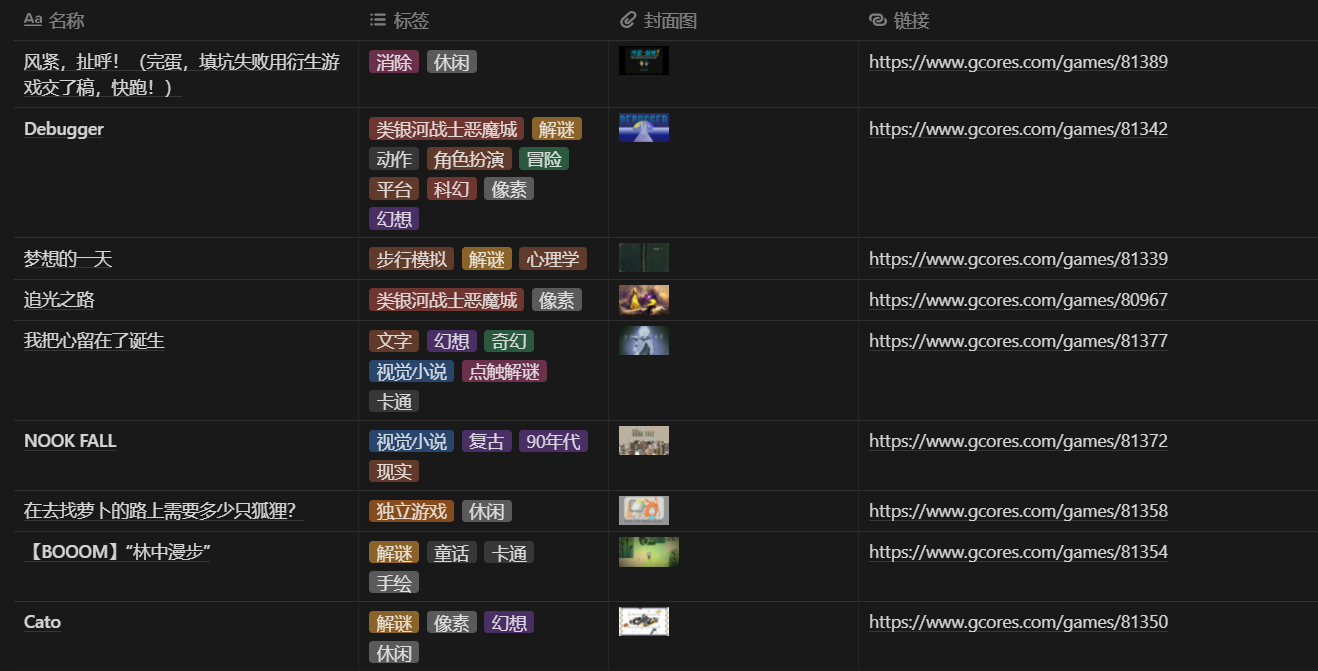
在多次测试、修复完各种大小问题后,最终成功将数据导入了 Notion。
导入 Notion 的游戏数据
在 Notion 中管理数据
至此,Notion 的数据库中已经保存了这些信息:
尽管游戏库所需的数据都已经导入,但实际用起来还是会有不同的使用案例,因而还要从不同需求出发、设计对应的数据视图。
我从「体验完这届 BOOOM 所有游戏」的目标出发,列出了这些使用案例:
围绕体验进度跟踪作品
随机浏览作品、找找灵感
查看已体验作品的评分
列完后,我发现还需要建新的数据库,因为使用案例 1 和 3 都涉及到个人试玩作品的评分,而现有数据库管理的对象是游戏作品,不是评分,如果硬要将评分数据存在这边的数据库,会使得信息管理起来过于臃肿。
于是我又新建了一个「测评记录」数据库,根据试玩需要设计了数据模型:
游戏 :关系,绑定到另一个数据库中对应的游戏,可以通过关系互相查表
表现力 :数值,打分用
创新 :数值,打分用
符合主题 :数值,打分用
喜爱程度 :数值,打分用
开始测评 :时间,记录用
结束测评 :时间,记录用
总评 :文本,概括玩法+优缺点评价+总结
测评用时 :公式输出数值,用开始和结束时间计算游玩了多少分钟
总分 :公式输出数值,综合上面的几项打分计算总分,各项权重暂定均等
总分-图标化 :公式输出文本,将总分转为 N 颗⭐的文本
一条测评记录会包含的数据/属性
再回到游戏的数据库,参考前面罗列的使用案例,通过组合 Notion 中的视图、筛选、排序、可见属性,我最终创建了 4 个不同的数据视图:
随机漫步 :满足「随机浏览作品、找找灵感」的需求,以卡片呈现,显示封面、标题、标签、链接,伪随机排序(每分钟更新)
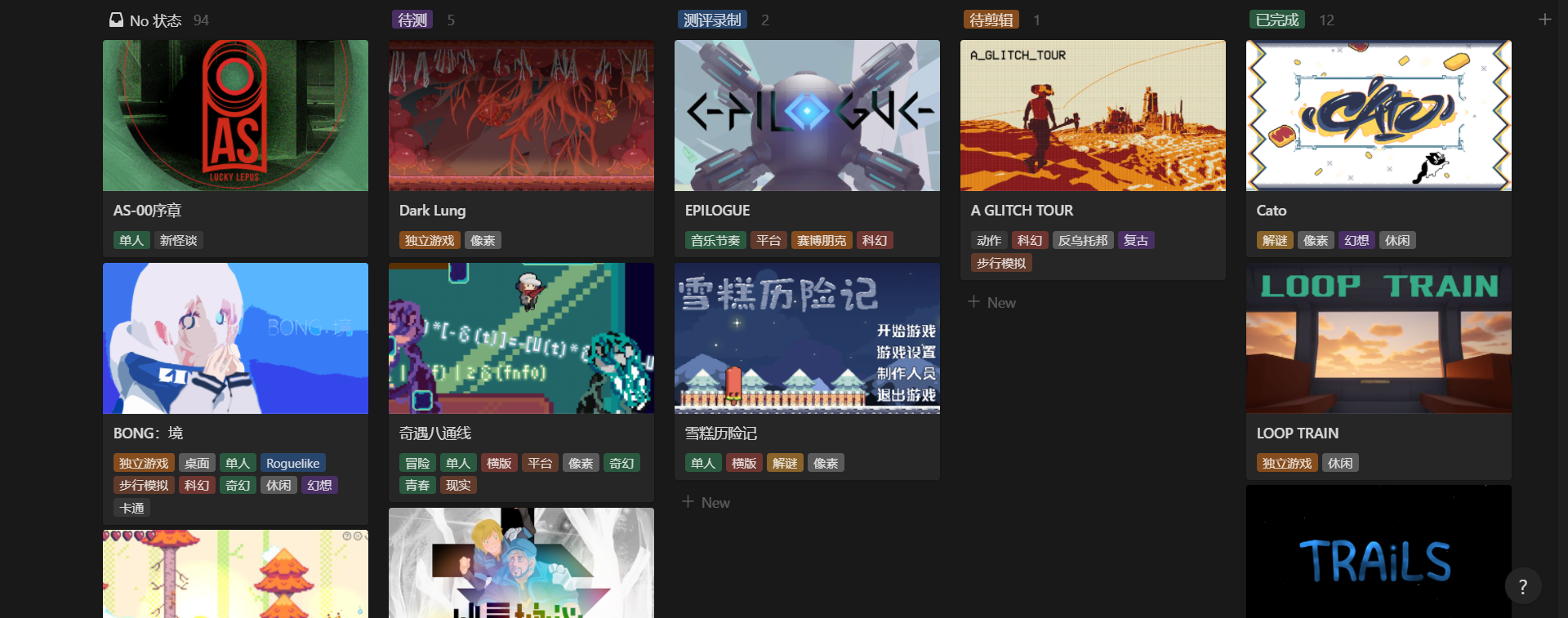
测评看板 :满足「围绕体验进度跟踪作品」的需求,看板按进度分组,显示封面、标题、标签
已完成 :满足「查看已体验作品的评分」的需求,以表格呈现,筛选已完成的、评分降序,显示所有属性
总表 :临时搜索用,以表格呈现,显示所有属性
BOOOM 游戏库的各个视图
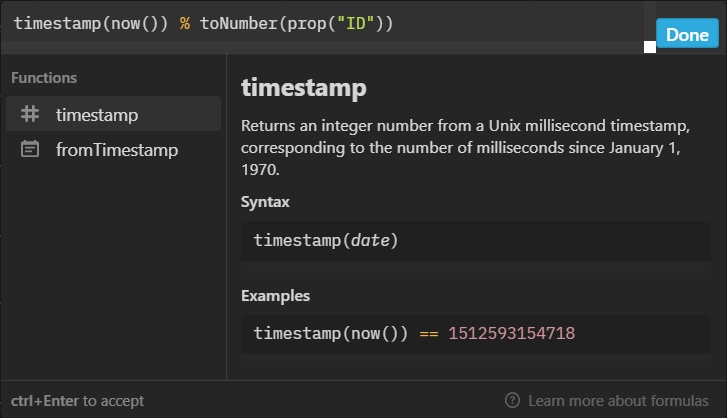
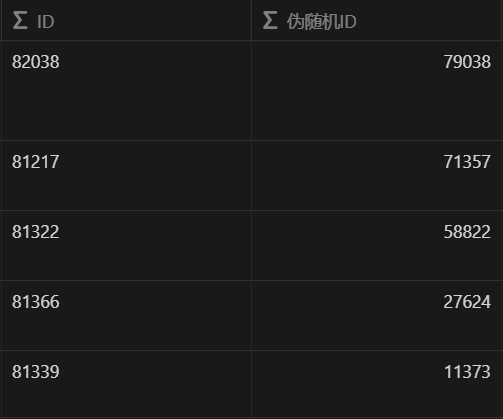
在随机漫步视图中,我用到了一套拍脑袋想出来的伪随机算法,刚好实现了每分钟重置一次列表排序。原理也很简单,每个作品的链接中有唯一的数字 ID(用正则从中提取),我在公式中代入当前的时间戳(精度是毫秒,但每分钟更新),用时间戳除 ID 取余数,最终每个作品就都会有一个每分钟更新、顺序不固定的数字,再用这个值来排序就可以。
分享到社区
到了这一步,我自己试玩所需的数据库已经算是搭好了,但我还准备额外做一个分享版,因为想起了自己用官方页面的痛点:
既然我会有这样的痛点,说不定还有其他人也会有相同的体验,而这套游戏库应该也能帮到他们,发挥更大的价值。
很快,我复制了一份现有的数据库,重新配置了一套视图:
分享版游戏库的卡片视图
接着,通过 Notion 的分享功能,我将这个新游戏库公开分享到了网络,开启了评论、搜索引擎检索,然后在机核发了条动态带上分享链接,将其分享了出来。
当时分享游戏库的机核动态
总结
在发完那条动态后,我也有了一些意料之外的收获。
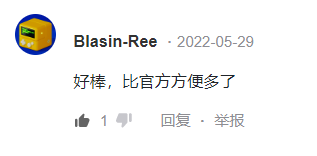
我收到了来自这届 BOOOM 开发者的点赞,《Cato》的开发者 Blasin-Ree 在动态下评论,说这套游戏库比官方的方便,让我着实高兴了好一会。
来自《Cato》开发者的点赞
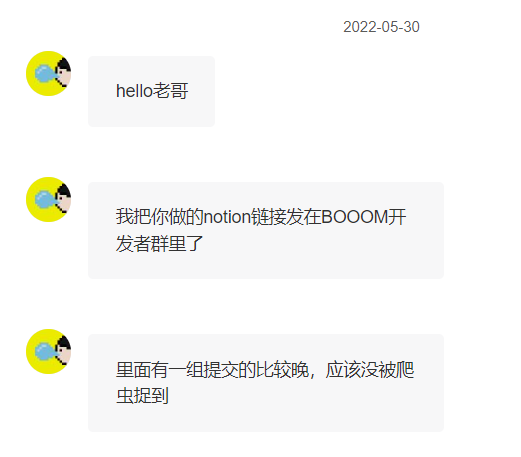
之后,《TRAiLS》的开发者 SleepyJeff 也找到了我,他帮我把这套游戏库的链接转发到了 BOOOM 开发者的群里,但发现有一个作品被漏掉了,可能是这组提交的比较晚、导致没被爬虫收集到。
热心的 SleepyJeff 帮忙反馈了被漏掉的作品
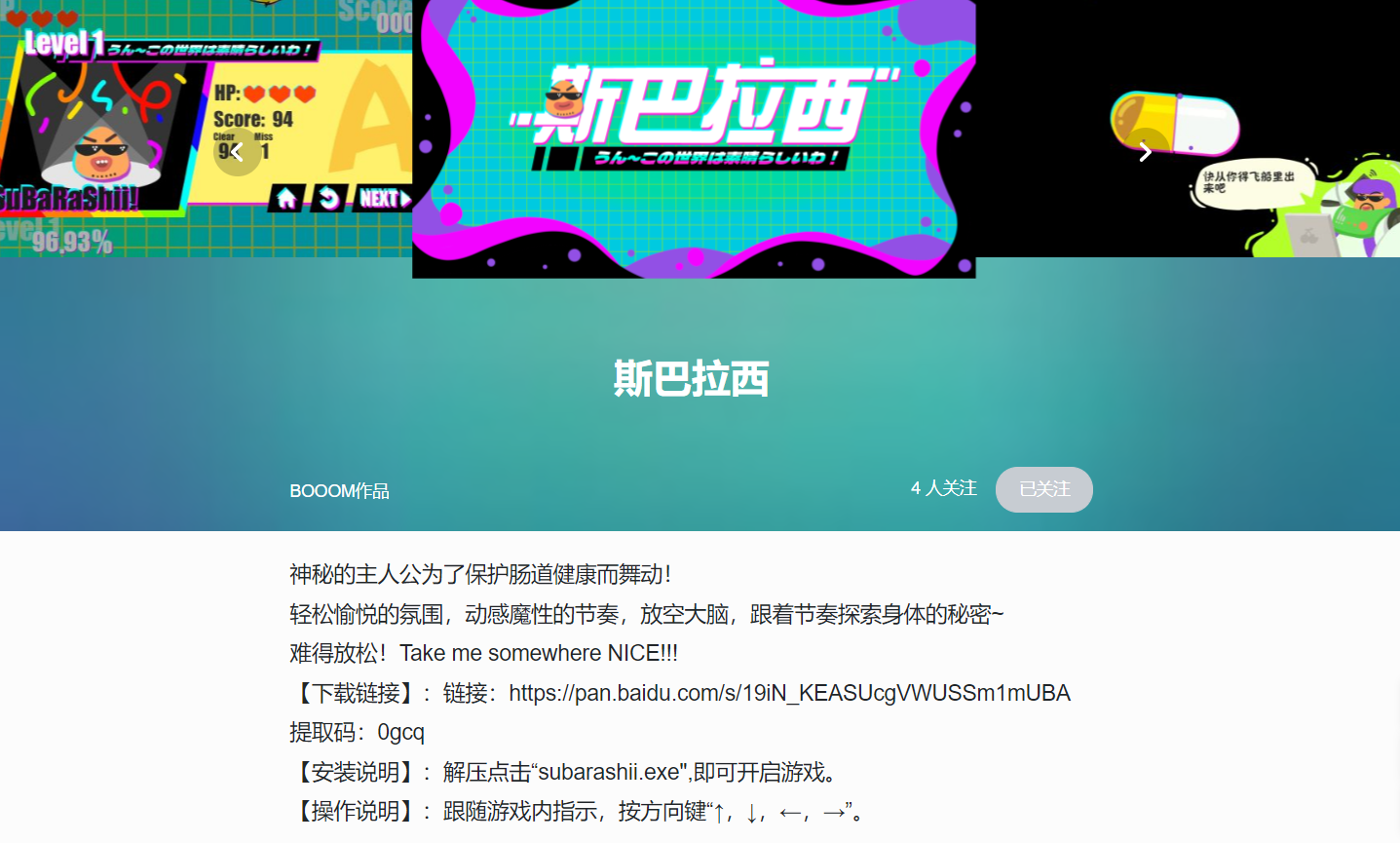
我了解后,也去排查了一波,确认当时的官方列表里依然没收录到这个作品,于是帮忙手动补录了信息。这个作品是 《斯巴拉西》 ,我之后试玩到发现美术很棒、完成度也很高的一个音游作品,希望这波补录有帮到他们。
推荐去玩一玩《斯巴拉西》,很有趣的一个音游作品
还有一个意外收获,就是开头提到的被一个叫西蒙的人关注了,我后来才知道他是谁。
回顾这次的 BOOOM 游戏库搭建,我学到了这些:
爬虫收集的数据若需要持续访问、使用,量级不大时可以考虑导入 Notion
在代码注释中点明目的,比点明做了什么更有助于帮助回顾
将围绕某个使用场景的常用函数打包,能让后续的开发更省事
涉及到重复操作 Notion 数据库时,可以考虑用 Notion API 做自动化
个人项目的产物可能也对他人有所帮助,多考虑分享
最后,我想感谢 Blasin-Ree 的点赞、SleepyJeff 的热心联系,还有西蒙的关注。
如果你对这个游戏库感兴趣,可以点击 这里 访问。
什么,你想问我这一百多款游戏体验得怎么样了?
……
……
……
在玩了,我这就去继续玩。