前言
在上一篇中隊虛幻5引擎的Lumen全局光照粗讀進展到了
軟件光追和表面緩存的部分,這週會從硬件光追的部分開始。
開頭簡單談談從讀這些資料我個人簡單總結出的UE引擎的“高精度間接光照魔法”的一些因素:
- 首先,通過一些手段來合併渲染調用,例如虛擬紋理(及類似結構),例如網格LOD整體化(Nanite框架)——最大限度避免機器渲染指令的切換與綁定帶來的影響
- 其次,設計細節上充分利用GPU連續處理與並行處理方面的優勢,例如在一切需要對數據作壓縮的地方作壓縮,以保證連續性;在追蹤步驟時還能通過前綴和(prefix sum)來兼顧並行與順序
- 最後,對極值情況(例如抖動的樹葉)作一些取捨,必要時用一些trick來避免破壞整體方案
並且,渲染技術方案往往是一個行業內不斷互相優化的過程。文末會附一篇它們的參考引用,其中可以看到究竟集成了多少前人的智慧。
本文還是以翻譯原文PPT頁及解說稿為主,打星號的部分則是我個人的補充。這是兩篇中的下篇,相比上篇來說理論信息的密度會低一些,圖片和數據會更多,可能閱讀負擔就沒有那麼大了。
1 硬件光線追蹤
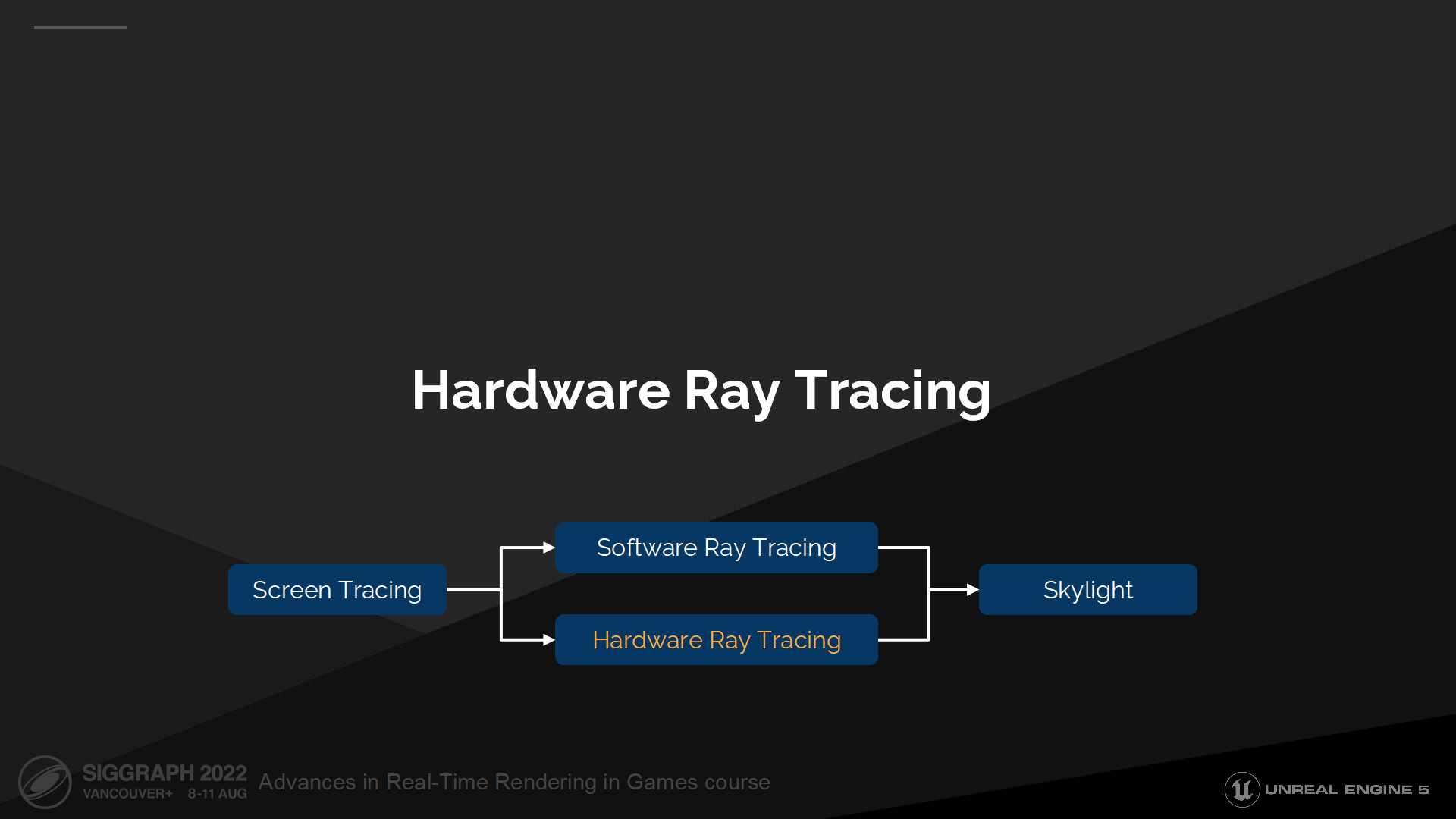

動機
我們在使用硬件光追時主要關注幾方面:
- 可以通過原始三角形數據來精確計算射線與物體的相交
- 這激活了動態的材質和光照公式
- 使得更細緻的(屏幕外物體的)反射成為可行
- 最後,現代主機對於硬件光追的支持能使這項技術得到更廣泛的使用

概述
讓我從列出我們最初的硬件光追和Lumen集成的提綱開始:
- 我會簡要介紹對UE4模型的合併方案,以及其中的缺點
- 之後我會引入一個作為替代的模型,它能最小化運行時的開銷——通過使用表面緩存
- 之後我會演示通過混合兩種模型能帶來怎樣的質量提升
- 最後我會介紹Lumen支持的兩種光照計算模型
我也將介紹一些我們系統中的不透明度描述(representing opacity)的經驗性方案,並討論Lumen的GPU-driven管線如何改變了硬件光線追蹤的調用。
我也將著重介紹在“The Matrix Awakens”案例中遇到的遍歷相關的複雜度(traversal-related complexities)問題,例如整合Nanite的備選網格並將追蹤距離擴展到遠場(far-field)。
最後,我會描述UE5中完整的硬件光追管線以作為總結。(*後續硬件光追部分會縮寫為HWRT)
*其實原文使用traversal一詞的時候是兼顧遍歷與追蹤兩個含義的,但在更接近“調用”與“執行”的地方我還是更多翻譯成遍歷。

嘗試HWRT反射
Lumen的HWRT從對反射的嘗試開始。對於這一任務,看起來最合適的方法使從UE4的光線追蹤反射模型開始。通過集成UE4的光線追蹤反射,產生了一個對於動態材質和光照計算的快速方案——這在最初很明朗,但其中的缺點需要在我們開發整合方案之前被指出。
*這裡沒有UE4的做法的上下文,還是要結合缺點及改進的部分一起看。

嘗試HWRT反射
其中最值得注意的問題是,UE4的反射模型缺少適當的高光剔除(specular occlusion)。圖中的鏡像球清楚展現出了這一情況,其中(不投影的)天空光源使內部結構染上了一抹不自然的藍色。

圖中標出位置也缺乏高光剔除。
表面緩存管線
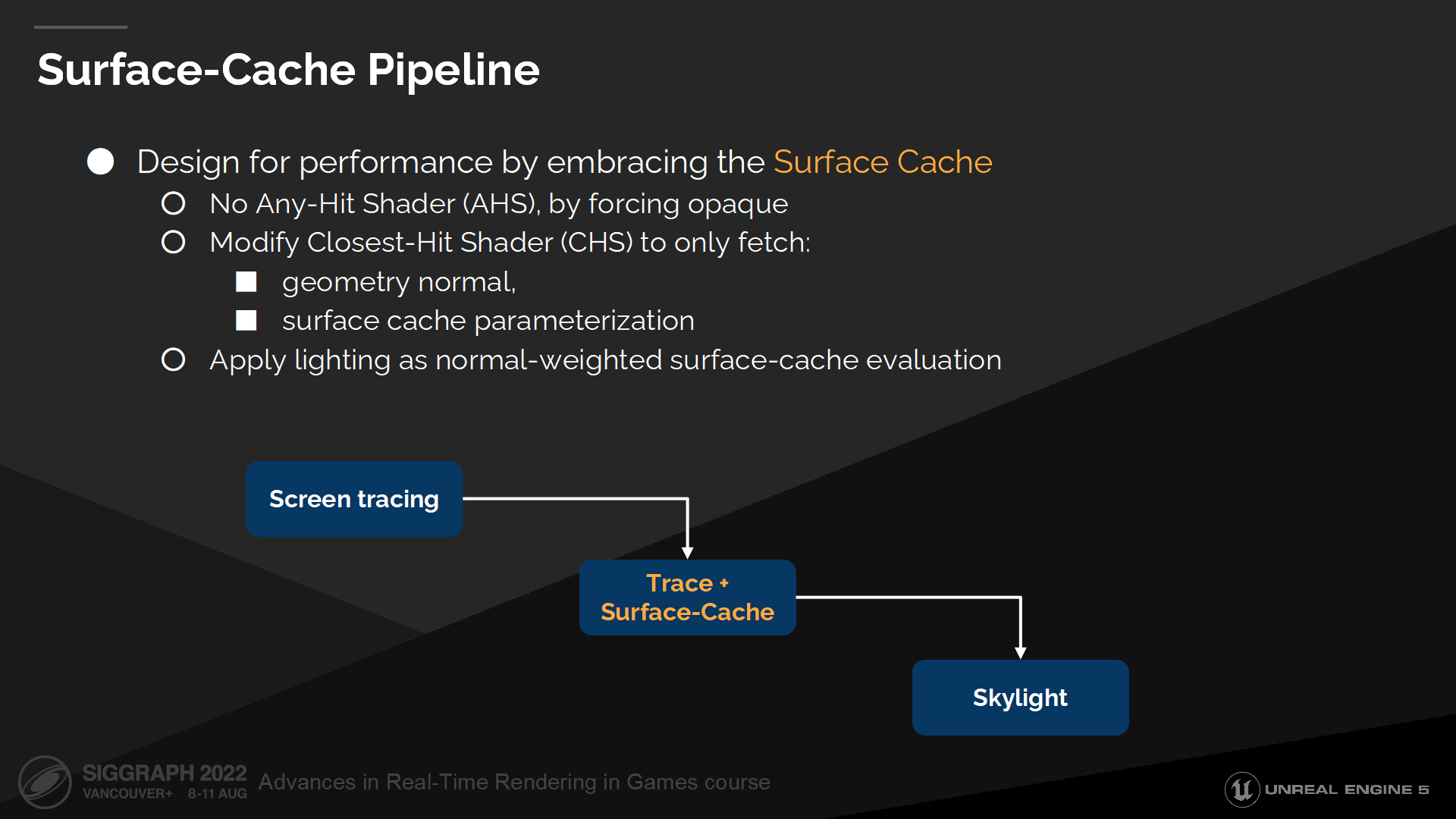
與此同時,我們也意識到完全放棄動態光照計算,並全部依賴表面緩存來計算會是一個好的嘗試。
我們也決定了為管線增加一些額外的限制,並通過強制所有BVH加速結構中的物體都是不透明,來排除any-hit shader的使用。(*這裡應該是避免透明類檢測拖慢硬件光追過程)
For this model, we replaced the set of material-dependent closest-hit shaders with a single closest-hit shader, and this shader only fetches only the data necessary to extract the geometric normal and surface cache parameterization. The ray-generation shader then applies lighting as a normal-weighted surface-cache evaluation.
對於這一模型,我們以單個的closest-hit shader替換了原先是一組的材質相關的closest-hit shader——這個shader只抓取得出幾何體法線和表面緩存參數需要的數據。之後通過射線生成shader提交光照結果,並通過一個法線作為權重的表面緩存計算光照(normal-weighted surface-cache evaluation)。
我們把這一管線稱為表面緩存管線(Surface-Cache Pipeline)。

表面緩存光照(未應用時)

表面緩存光照
利用表面緩存,我們能在一個光照計算過程中得出直接和間接光照。這使我們得以克服之前提到的天空光照問題。(*兩圖前後對比)


也能糾正前面提到的高光剔除問題。(*兩圖前後對比)

表面緩存的有效載荷
With the aggressive optimizations to the Surface-Cache pipeline, we created a new payload structure to minimize bandwidth pressure. The high-quality payload used in the UE4 model requires 64-bytes to store GBuffer-like parameters for dynamic lighting. This includes parameters such as BaseColor, Normal, Roughness, Opacity, Specular, and more. In comparison, the Surface-Cache payload only requires 20-bytes to store the necessary parameters for a Surface-Cache lighting lookup.
通過表面緩存管線中的激進優化方案,我們創建了一個新的有效載荷(payload 後文保持原詞)結果以最小化帶寬壓力。UE4模型中採用的高質量的payload需要64字節以存儲類似GBuffer的參數以用於動態光照——它包含了例如基礎色、法線、粗糙度、不透明度、高光等;相對的,表面緩存的payload只使用20字節來存儲需要的參數,用於表面緩存光照的查找。
表面緩存的payload參數組在圖中下方列出。對於表面緩存管線來說材質ID的字節數指定原本是不需要的,不過後續我會解釋其中的原因。

表面緩存管線
表面緩存管線也簡化了shader綁定表(binding table)的結構。通過這個新模型,綁定循環不再需要獲得與材質有關的數據資源。對於大量的實例來說,這能帶來可觀的GPU時間的節省。
不幸的是,我們無法完全去除整個綁定循環,因為頂點和索引緩衝綁定(index buffer bindings)在DXR中重構表面法線時仍是需要的,而UE5目前也沒有使用無綁定的(Bindless)著色資源。
*關於Bindless,常被和虛擬紋理一起拿來談。簡單來說Bindless是一種新的提交資源描述符的方式,能帶來渲染時更靈活的內存結構組織方式。
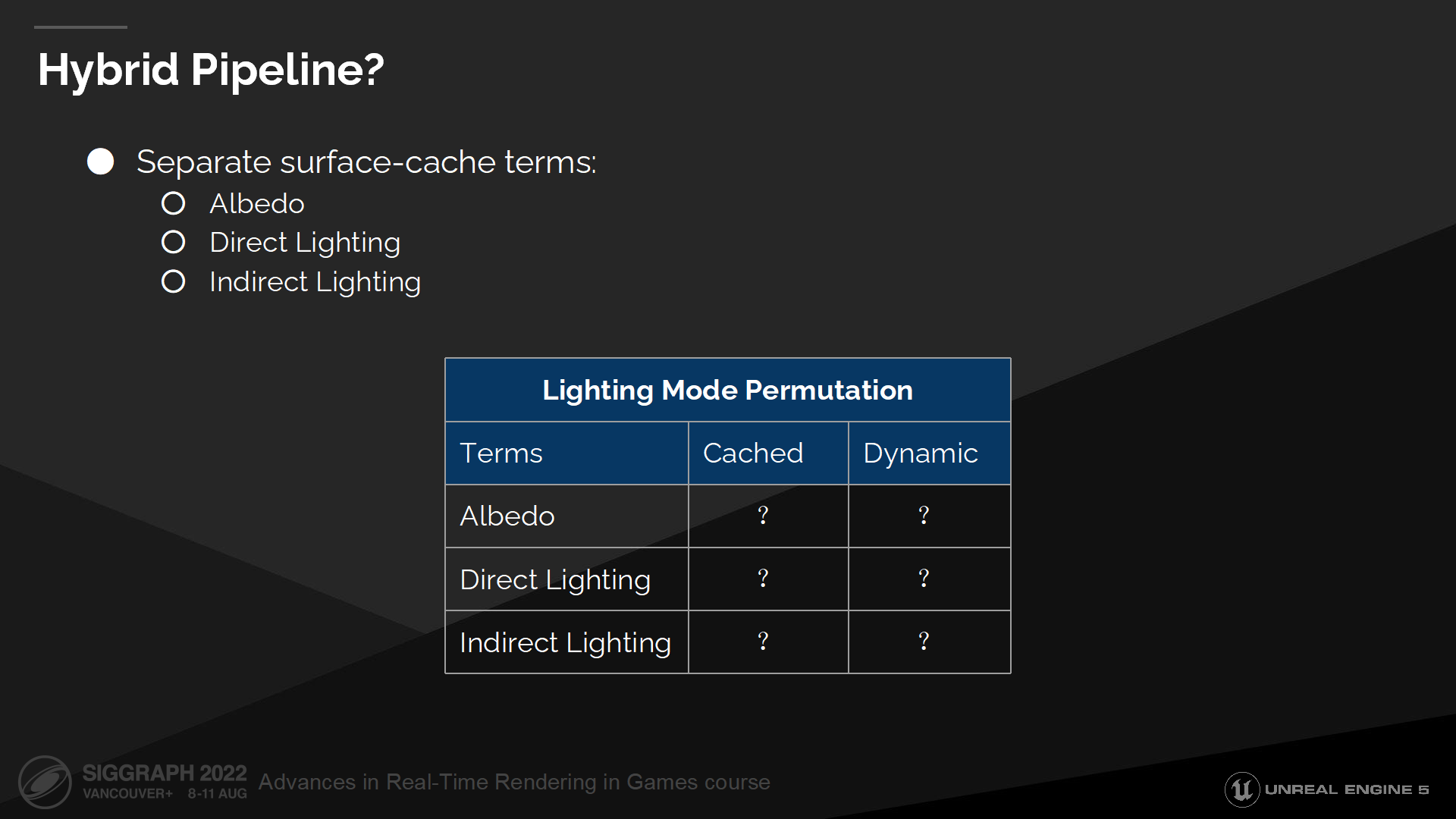
混合管線?
After constructing the two models, we anticipated that mixing the two strategies could provide a natural scaling control to govern the performance vs quality tradeoff. We accomplished this by conditionally separating surface-cache terms, such as albedo, direct lighting, and indirect lighting depending upon the desired level of dynamic evaluation. This also presented a mechanism to incorporate the surface-cache indirect lighting with the dynamic evaluation of UE4 model, eliminating a fundamental problem with unshadowed SkyLight.
在構造了兩套光照模型後,我們預期中混合這兩種策略可以提供一種自然的規模縮放,以平衡性能和質量的tradeoff。我們通過有條件地拆分表面緩存的表達式來實現這一點,例如漫反射係數、直接光照、以及基於設計好的層級來計算的間接光照。這也提出了一種機制,以合併表面緩存的間接光照與UE4的模型,並消除了無陰影的天空光源方面的基本問題。
儘管我們能分別控制是否需要動態計算材質或光照,我們發現局部動態計算的開銷和全部動態計算一樣高。

光線追蹤模型
基於這一發現,我們只為藝術家提供了兩種光照選項——表面緩存模型完全按前文所述的方式來實現,而Hit-Lighting模型代表整合了表面緩存間接光照的UE4模型。同時,我們也只開放Hit-Lighting模型用於反射。
需要著重指出的是,Hit-Lighting模型實現了之前發佈過的Sorted-Deferred追蹤管線的修改版。由於這項優化需要導出材質ID,因此這是為什麼表面緩存的payload需要它的原因。
*Sorted-Deferred tracing pipeline原始方案,網上找到的資料源自《RAY TRACING IN FORTNITE》這篇文章——後來被收錄進了《Ray tracing gems》書中。文末會附一篇PDF地址。
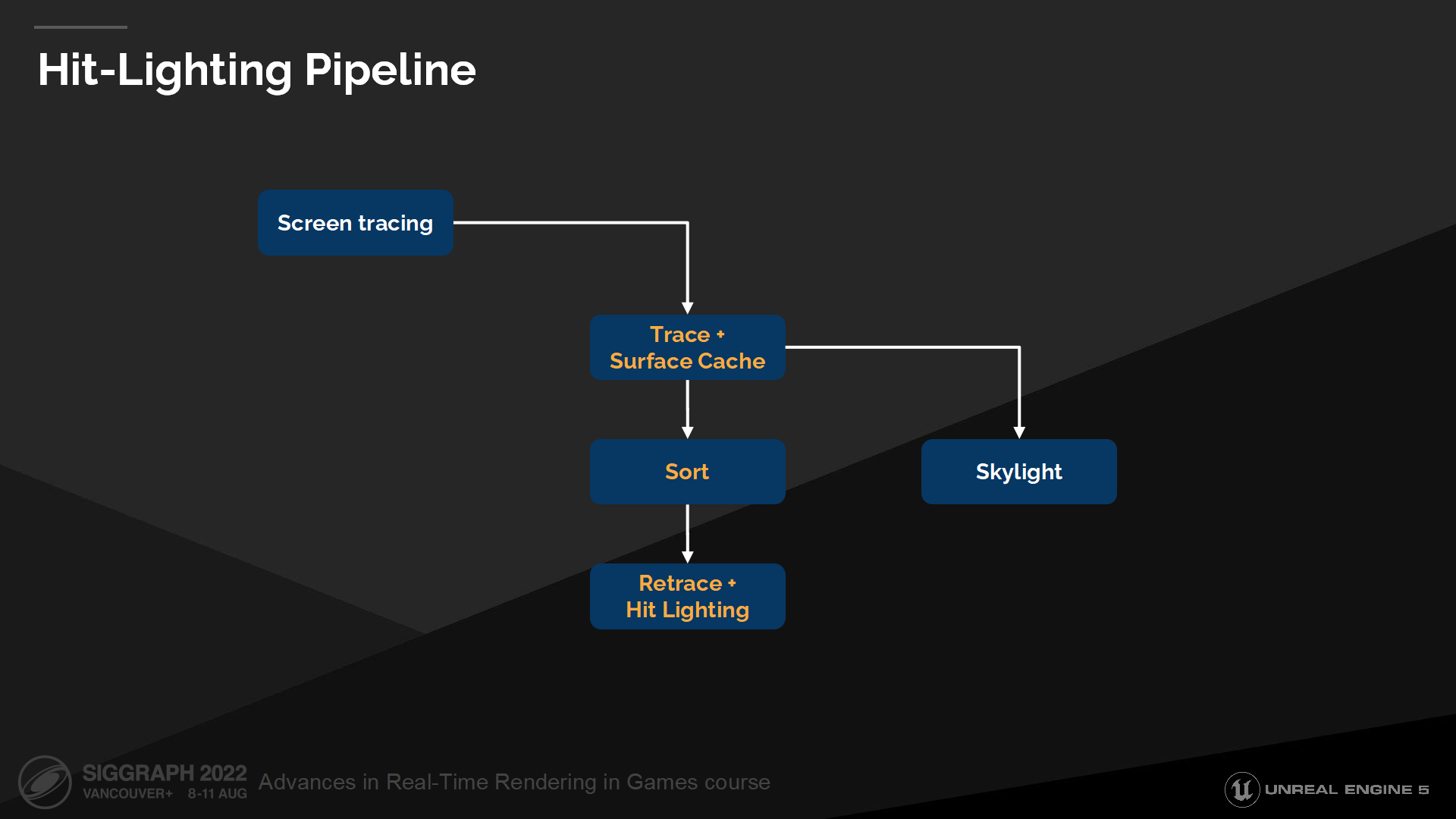
Hit-Lighting管線
This allows us to repurpose the Surface-Cache tracing stage as the prerequisite to the Hit-Lighting pipeline. It also grants us the flexibility to optionally invoke dynamic evaluation on a per-ray basis. For instance, we have experimented with this idea to optionally invoke Hit-Lighting on meshes which have no Surface Cache parameterization.
這允許我們重新調整表面緩存階段的用途,使它成為Hit-Lighting管線的先決條件(prerequisite)。這也為我們提供了有選擇地調用逐射線動態光照計算的靈活度。例如,我們已經嘗試了有選擇地在沒有表面緩存參數數據時,在網格上調用Hit-Lighting。
圖中展示的就是完整的Hit-Lighting管線,並添加了初次執行表面緩存追蹤pass後的排序和重新追蹤的步驟。

在(源自UE4模型的)Lyra的例子中,我們可以看到Hit-Lighting為鏡像球上的骨骼化(skeletal meshes)的網格提供了直接光照反射。由於骨骼化的網格沒有表面緩存參數,這一效果只能通過Hit-Lighting模型來實現。
*之前也介紹過表面緩存幾乎無法精確處理動態物體。這裡的skeletal meshes說的比較繞,其實就是可動的角色。

整合不透明度
表面緩存管線在處理局部透明的幾何體時提出了額外的挑戰。如前所述,當採用表面緩存模型時,我們嚴格地把BVH中的所有幾何體都視為完全不透明——這樣做的原因是調用any-hit著色會導致客觀的運行時開銷。(*原文用了penalty 這個詞,直譯是懲罰)
一種嘗試克服這一問題的方向是不透明遍歷(opaque traversal),我們啟用了兩個材質相關的策略。對於透光(translucent)材質,我們選擇完全跳過這類網格;對於alpha遮罩(alpha-masked)材質,我們計算表面緩存的不透明度並跳過值在50%以下的網格。(*注意這裡是跳過網格而不是丟棄像素)
Since we chose to omit an any-hit shader, we must iteratively traverse through the scene in the ray-generation shader whenever we encounter a partially opaque surface. This iteration count is governed by a MaxTranslucentSkipCount shader parameter.
由於我們選擇省略了any-hit shader,我們必須在射線生成shader中迭代地遍歷整個場景——在遇到任何一個局部透明表面時。迭代次數受MaxTranslucentSkipCount參數控制。

MaxTranslucentSkipCount參數
圖中的例子展示了MaxTranslucentSkipCount參數的應用——當處理一個局部是部分透明的幾何體時。(*圖中左側是Lumen Reflection管線,右側是光柵化管線)

Alpha遮罩
圖中的例子展示了計算表面緩存中的不透明度,並在遍歷時重構幾何體的alpha mask的例子。

派遣調度
Lumen的GPU-driven管線需要額外加入UE4中不具備的派遣控制。相比於直接操作屏幕空間像素,Lumen的pass的計算基於探針(probe)、表面緩存紋素(texel)、屏幕塊(tile)。在許多實例中,硬件光追是作為第二級的追蹤類型——以備選技術的規格來運行。基於這些原因,本質上就是我們在支持的各處都利用間接派遣。因此,Lumen在PC上更傾向於DXR 1.1的語法。(semantics,直譯是語義學)
We should also point out another useful feature in DXR 1.1: Inline ray tracing. The RayQuery interface avoids the complexity of the shader binding table and this allows for the hardware traversal in standard compute and pixel shaders. Utilizing ray queries also offers the compiler significant opportunity to optimize. In the ray-generation case, it is strongly recommended to minimize the amount of "live state" spanning a TraceRay() call. With Inline ray tracing, the compiler can minimize this without developer intervention.
我們也需要指出DXR 1.1中的另一個有用的特性,串聯射線追蹤(Inline ray tracing)。其中的RayQuery接口避免了shader binding table的複雜度,並支持標準計算中的硬件遍歷以及像素shader。利用射線查詢也為編譯器帶來了重要的優化機會:在射線生成時,最小化一個TraceRay() 調用所貫穿的"live state"數量是被強烈建議的;而通過inline ray tracing,編譯器可以在不需要開發者干預的情況下最小化這個值。
Except for the need to supply mesh-varying vertex and index buffer data to hit-group shaders, the Surface-Cache pipeline could use inline ray tracing. This auxiliary buffers are only a requirement for PC; however, as console ray tracing intrinsics already provide access to the geometric normal as part of the ray-tracing Hit structure. Because of this, we actually do leverage inline ray tracing on consoles and benefit from a noticeable speedup on certain platforms. To learn more about this console specialization, please see Aleksander and Tiago's talk.
除了需要支持網格變化的頂點和索引緩衝數據(用於hit-group shader)之外,表面緩存管線也可以使用inline ray tracing。這些輔助的緩衝數據只在PC上是需要的;而在主機上內建的光線追蹤架構中,已經提供了對幾何體法線的訪問——作為光追命中結構(Hit structure)的一部分。因此,我們在主機上利用inline ray tracing在多個平臺獲得了客觀的速度提升。對於主機專題優化的部分,可以參照Aleksander和Tiago的講座。(*由於主機開發隔得比較遠,我短期內可能不會讀到這篇講座,有興趣可以按圖中的出處搜索)
2 整合案例——The Matrix Awakens
*雖然這裡拆分了一節,但原文語境中主要還是在說硬件光追。

矩陣覺醒
“The Matrix Awakens”是一個包含了很多高難度挑戰的用以驗證光追模型的UE引擎實驗。開放世界場景對大量的實例數量提出了要求,它可以輕易地超出我們最頂層加速結構的重構建時間。場景中的大量活動的汽車和行人,也需要大量對於底層加速結構的動態改變(refits 改裝)。汽車油漆和玻璃材質也不能離開鏡面反射(以表現其真實性)。
DEMO的目標發佈平臺是Xbox Series X/S和PS5。這些主機有比較不成熟的光追支持,有著相對更低的算力以及更慢的遍歷速度——相對於高端PC來說。然而,主機API提供了極大的光追管線靈活度,使其可以發揮我們的優勢。例如,對靜態網格的加速結構構建可以被預構建和流式加載,顯著地降低每一幀中改變底層加速結構的時間。對於更多主機平臺優化的細節,仍是再次推薦Aleksander和Tiago的講座。
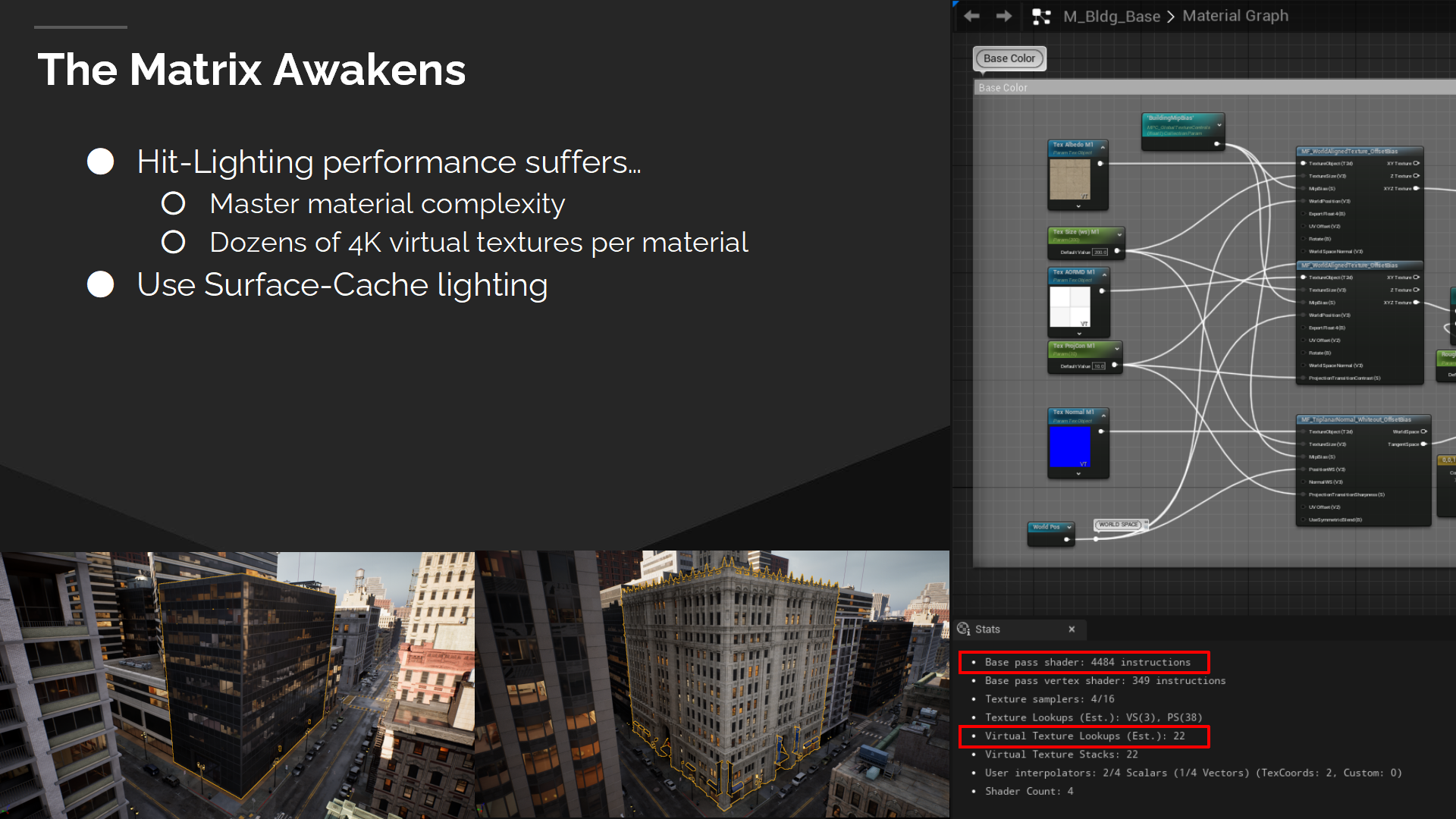
不幸的是,DEMO中的材質複雜度使得對於Hit-Lighting模型的依賴變得不可行。伴隨著高指令數,我們的主要材質調用了數十種虛擬紋理的獲取(fetches)。動態材質和光照計算無法有很好的性能。起初我們對於調用Hit-Lighting來支持動態物體有所期待,但我們輕易地就耗完了性能預算。

圖中的耗時報告顯示了在PS5上調用Hit-Lighting(計算我們的複雜材質)的驚人的計算開銷。有趣的是,Hit-Lighting也沒有帶來實質上的質量提升(substantial qualitative benefit)。這是由於我們的DEMO中對於天空光源強依賴——而它在兩種管線中都無法從表面緩存中獲益。

通過Nanite進行追蹤
Matrix Awakens中的絕大多數資源是通過Nanite渲染的。這立刻產生了一種基於硬件光追的併發症——因為我們的加速結構沒有能力支持原生的Nanite幾何體精度。這其中有很多理由,我著重列出了其中一部分(圖中展示了,例如:底層加速結構BLAS的存儲太大,頂點和索引緩衝的提交問題等)。不過最簡單的回答是,高質量的Nanite光追支持還是一個實際的研究區域(未完成工業化)。
Instead, we must make some concessions with approximate geometric representations. We use Nanite fallback meshes as simplified representations of the rasterized geometry and store them in bottom-level acceleration structures. These fallback meshes bring their own set of challenges, as they do not provide any topological guarantee with the base mesh.
相對的,我們必須採用近似的幾何描述來做出一些讓步。我們使用Nanite的後備網格作為簡化的柵格化的幾何體的描述形式,並將它們保存在底層加速結構中。這些後備網格也帶來了其自身的挑戰,因為它們並不能提供基本網格能保證的拓撲關係。
直接從GBuffer追蹤提出了一些明顯的挑戰——當與Nanite後備網格共同運作時。採用近似形體產生了潛在的自相交問題,無法被傳統的射線偏移量(bias)輕易克服。

避免自相交
圖中展示了DEMO中渲染車輛時常見的一種自相交故障。我必須手動關閉屏幕空間追蹤,以展示僅依賴光線追蹤場景時帶來的故障現象。(*圖中就展示了應該有反射卻沒能正確追蹤射線的情況)

避免自相交
圖中展示了疊加到LumenScene(場景編輯模式)的截圖,以提供一個待解決的幾何體錯配問題的參照。
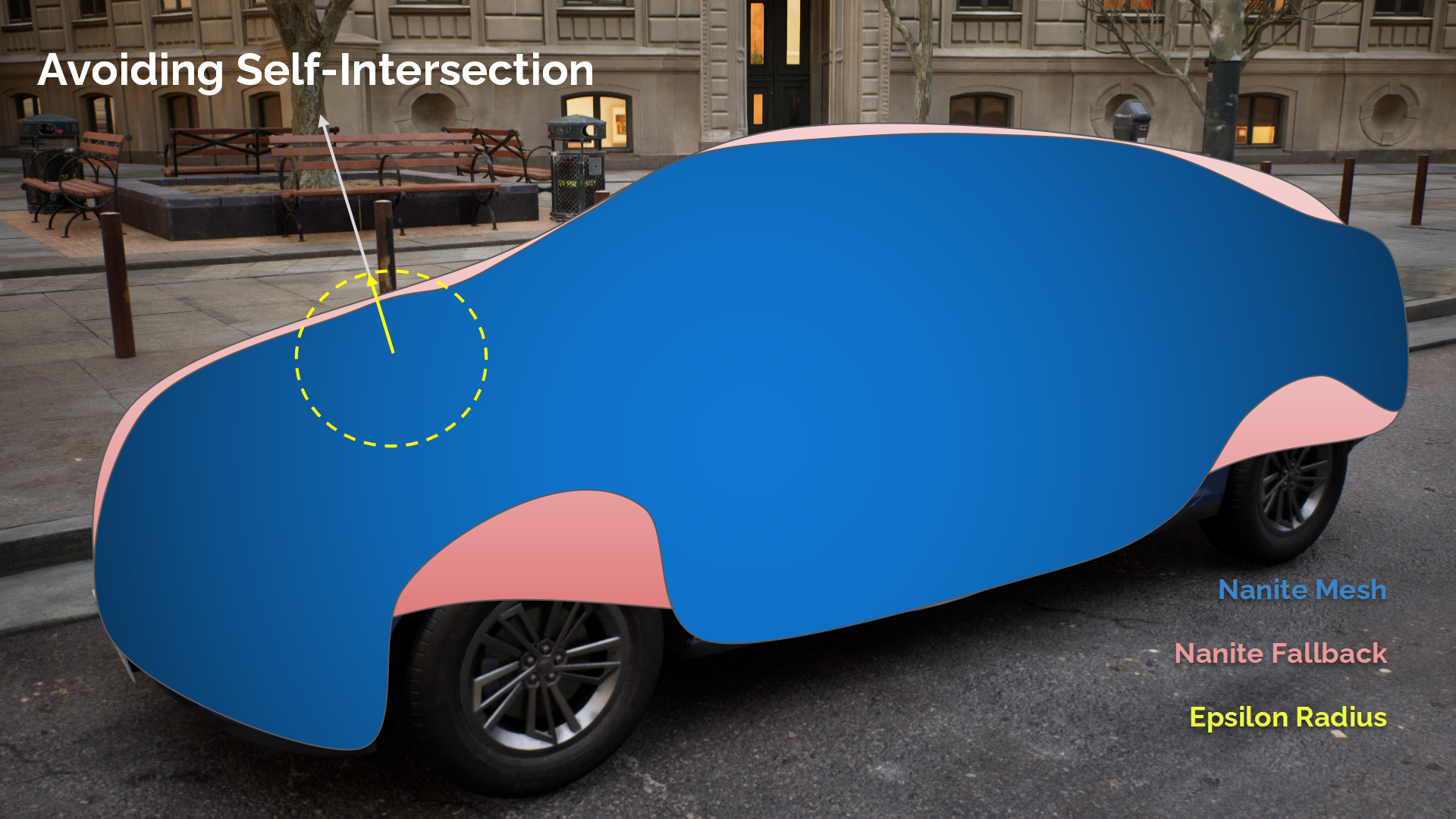
避免自相交
Ray tracing against multiple geometric levels-of-detail is not a new problem, however. Tabellion and Lamorlette presented a solution for this issue back in 2004 [Tabellion et al 2004]. Unfortunately, a proper implementation was too expensive for our budget. Instead, we modified our traversal algorithm to first cast a short ray, to some defined epsilon-distance, ignoring back faces. Only after successfully traversing this distance did we cast a long ray, without any sidedness properties. This figure illustrates the process.
然而,對於不同幾何體LOD層級的光線追蹤不是一個問題。Tabellion和Lamorlette在2004年就提出了一個解決方案。不幸的是,一個正確的實現對於我們的性能預算太說太昂貴了。因而,我們修改了遍歷算法以在最初發出一個短射線,以某些預定義的epsilon距離(作為最大距離),並忽略網格背面。僅在成功通過這段距離後,我們再射出一個長射線——不需要任何偏移型的參數。圖中展示了這一過程。(*常有的跳過初始自相交區間的trick)

避免自相交
應用這項技術移除了之前提出的自相交問題。

屏幕空間追蹤
Screen traces also overcome self-intersection artifacts, by providing hardware traversal with a starting t-value that aligns with the bounding view frustum.
屏幕空間追蹤也能克服自相交故障——通過為硬件遍歷提供一個初始的與視錐軸對齊的T值。

屏幕空間追蹤
但視錐固有的邊緣使這項技術在圖像的邊緣處變得失效。

屏幕空間追蹤+重新追蹤
所以最終我們採用了兩項技術整合的方案。

處理實例和幾何體複雜度
如之前提到的,DEMO中動態實例的大數量對硬件光追模型帶來了可觀的壓力。我們的系統重構了頂層加速架構,並且早期的實驗表明我們的模型需要限制100K的實例數量上限。在實驗的最後,內容尋址數接近了500K的動態實例——以接近1M為目標。每幀重構建的開銷不是唯一的問題,射線遍歷也變得開銷巨大——由於巨量的三角形數。
顯然我們需要控制最大的可追蹤距離以達成性能指標。通過將最大追蹤距離與射線追蹤網格的剔除距離相對齊,我們可以限制(原文是throttle,掐死)這個系統規模以符合我們最初的需求。我們法線追蹤要實現這一需求,追蹤最大距離要限制在200米。
However, limiting trace distance had a profoundly negative impact on the overall look. Car reflections no longer showed the skyline in the distance. But more importantly, accurate sky occlusion from the global illumination solver was completely gone.
然而,限制追蹤距離在整體看來也會產生深刻的負面影響——車輛的反射不再出現在地平線處遠距離的汽車上。更重要的是,源自全局光照解決方案的精確天空遮擋也完全失去了。
我們需要為這些問題提出一些補償方案。

處理實例和幾何體複雜度
我們選擇利用世界座標系統以及它的HLOD描述方式以完成這個目標。在HLOD系統中,網格是簡化並被合併的,生成了一個遠距離合並後的幾何體。
In the typical case, HLOD representations are direct replacements for rasterized geometry; however, due to limitations with performant trace distance, we needed to incorporate the HLOD representation before the rasterizer would typically need this substitution. Because of this, we were often presented with two different mesh representations occupying the same space in our top-level acceleration structure.
在典型的情況中,HLOD描述方式被直接替換柵格化的幾何體;然而,由於追蹤距離上的性能限制,我們需要在光柵化真正需要這一替換前都將其合併入HLOD的描述方式中。因此,我們通常在頂層加速結構中為佔據同一空間的網格準備了兩套不同的描述方式。
要克服其中的不一致問題,我們接受了(同時存在)兩種描述方式,但在射線遍歷過程中強制使其互斥——通過一個ray-mask。我們標記出其中屬於“遠場”的HLOD網格。(*這主要是說不允許同一個位置的網格既採用柵格化網格又採用HLOD,需要在追蹤時人為將其規避掉)
*representation單獨翻成描述方式(或表達式)沒有問題,但結合到上下文會使閱讀彆扭。其實只需要理解任何3D物體都是以一定的方式存儲數據的,這種描述方式代表的是內存中的數據——如三角形、SDF、體積公式等。

遠場追蹤
射線遍歷現在包括了對“近場”和“遠場”幾何體遍歷操作的集合。對於有序遍歷,我們首先在一定距離內對近場幾何體做追蹤——基於我們的網格剔除距離值。在近場未命中的射線會被重新排序並對遠場做追蹤。
對於陰影射線我們翻轉了操作順序,因為我們不需要保證遍歷的順序了。之所以這麼選擇的原因是,遠場的描述方式包含(比近場)相對更少的實例和更少的幾何體,這使得遠場遍歷的速度會更快。
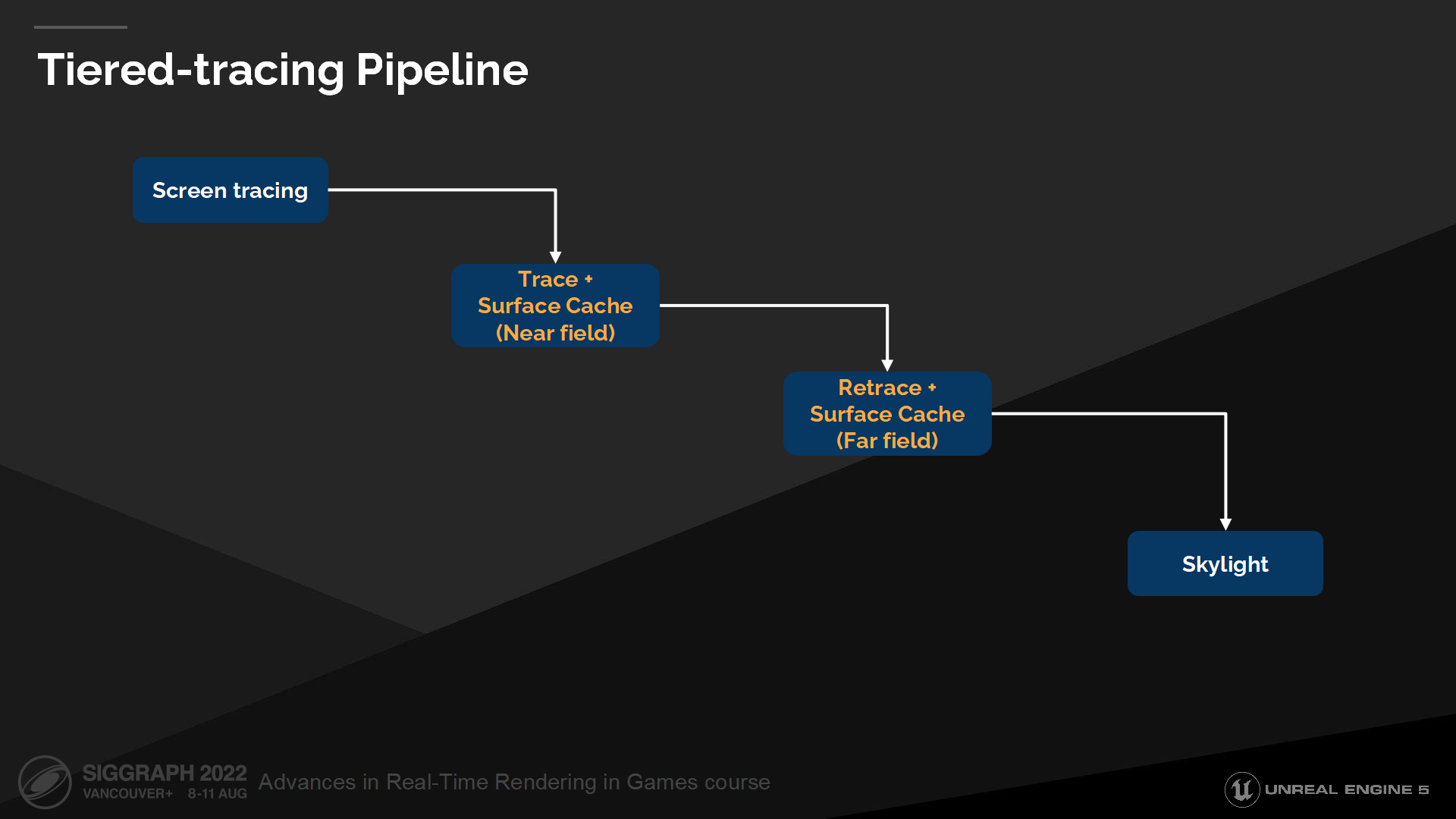
分級的追蹤管線
Incorporation of far-field traces into ordered traversal places a new set of stages into our original hardware traversal pipeline. We add an intermediary compaction step, collating near-field misses into new ray-tiles, and then a subsequent indirect dispatch to trace the ray-tiles against the far-field representation.
將遠場追蹤整合到順序遍歷的流程,產生了一組新的階段,插入原本硬件追蹤管線中。我們加入了一箇中間的壓縮步驟,收集近場未命中的射線放入新的射線塊(ray-tiles)中;在隨後的步驟,對遠場物體的描述方式(通過ray-tiles)做間接派遣的追蹤。
到目前為止,我暫時的把Hit-Lighting從我們的管線中移除了。

遠場可視化
圖中的可視化展示了進場和遠場幾何體之間的界限。不包含表面緩存的幾何體也被高亮顯示了。
*注意不是圖中斜向的線是界限,而是右邊不同顏色代表幾何體之間的界限——棕色的部分則是沒有表面緩存的區域。

Submitting both near-field and far-field representations to the same top-level acceleration structure is NOT ideal. Doing so creates needless geometric overlap. While the ray-mask removes unnecessary traversal, the damage to the top-level acceleration structure build is substantial. Our early experiments with overlaying the far-field representation revealed a show-stopping 44% penalty to all near-field traversal costs.
在同一層級的頂層加速結構中同時提交近場和遠場的描述方式是不合適的——這樣會產生不需要的幾何體的重疊。儘管ray-mask可以移除不必要的射線遍歷過程,但對頂層加速結構構建的傷害還是很大。在我們早期的實驗中,重疊遠場描述方式對所有近場追蹤產生了44%的額外開銷。
A proper solution would be to support multiple top-level acceleration structures, which would also avoid the need to use the ray-mask mentioned previously. We were hesitant to take on this architectural change mid-production under the already aggressive development schedule, but we needed to do something.
一個合適的解決方案是支持多種不同的頂層加速結構——這也能同時規避之前需要使用ray-mask來過濾射線的問題。在已經很激進的開發計劃的產品中期做這項技術調整,其實我們也很猶豫,不過我們確實需要做一些改變才行。
*這段其實不復雜但是我留了原文,可以看到措辭明顯是帶情緒了的——既體現了好的架構師的個人追求,也解釋了為什麼有更好的方案但是卻改不動的情況。(做過項目內開發的人應該都能理解,無論是不是遊戲項目)

按照早期的假設,有人建議:也許對遠場幾何體應用一個全局的平移偏移(translational offset)能緩解性能上的負擔。所以我們嘗試了一下這個方案。最終,我們仍承受了在同一個加速結構中整合兩類幾何體的負擔,但偏移值確實顯著緩解了性能上的開銷。
*遇事不決轉trick,性能搞不定轉offset。這不是揶揄,而是實時渲染領域很多時候就是如此來提升性能——以犧牲絕對意義上的正確性為前提。

近場

近場+遠場
前兩張圖展示了Lumen的pass中遠場追蹤應用的過程。由於反射剔除有最重要的視覺影響,你可以看到這對遠距離全局光照產生的效果。

圖中是另一處展示出遠場效果對整體質量提升的對比。

分級的追蹤管線
到這裡為止,我已經介紹了我們最終的分級追蹤管線所包含的必要模塊。
這裡提供一個簡要回顧:
- 我們為藝術家提供了兩種著色模型——更快速的表面緩存模型,以及高質量的Hit-Lighting模型。
- 我們也提供了一種機制以優雅地(gracefully)將一個高質量的近場幾何描述方式,與低質量但更高性能的遠場幾何描述方式做串聯整合(cascade)。
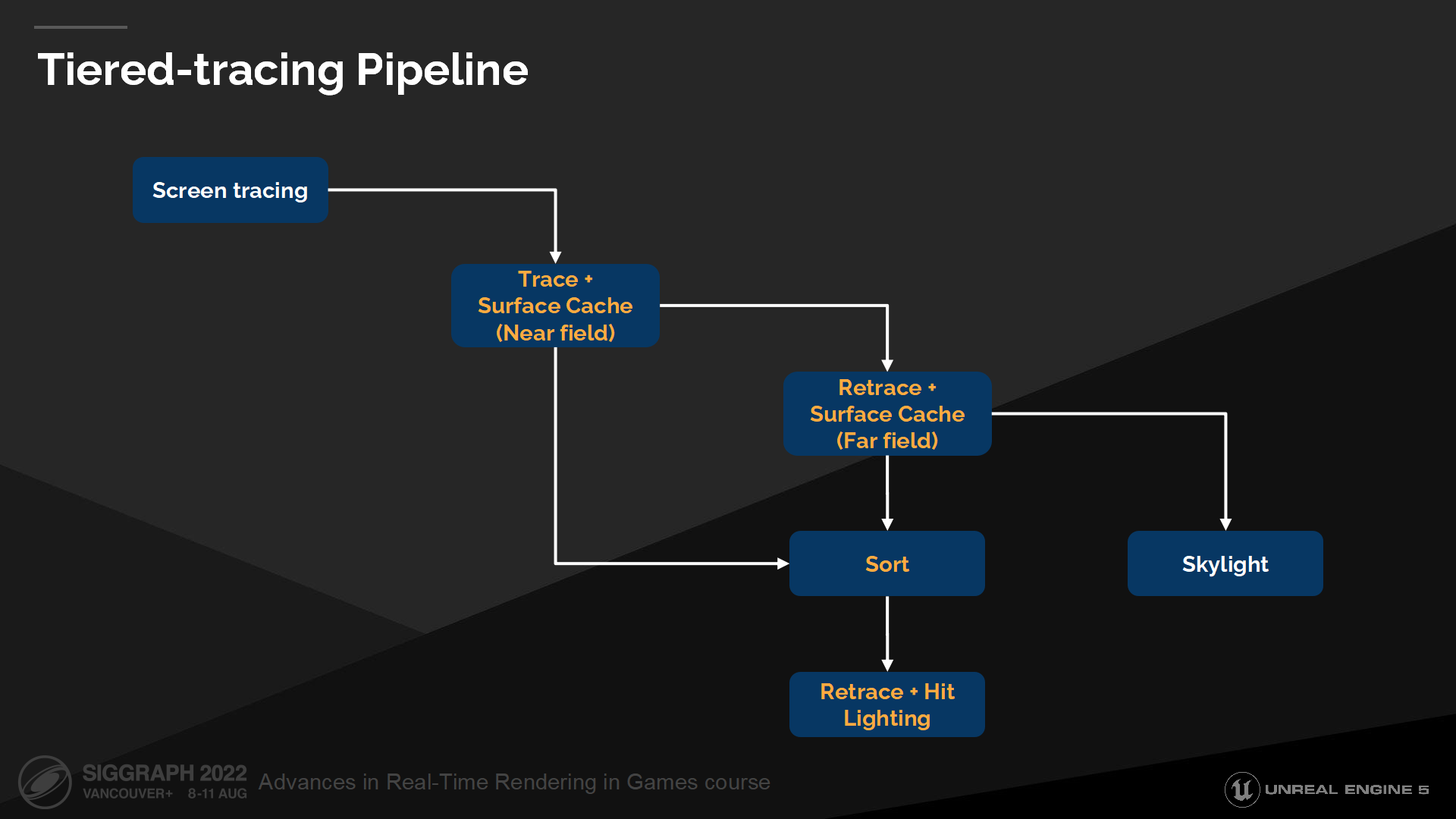
分級的追蹤管線
With some reordering of stages, we can minimize the dispatch costs by first resolving all Surface-Cache stages before optionally requeuing results for Hit-Lighting. We do this by cascading through both geometric representations. Hits are then compacted and optionally requeued for Hit-Lighting, while misses cascade to apply SkyLight evaluation.
通過某種對渲染階段的重排,我們可以最小化派遣的開銷——通過首先處理所有表面緩存階段,之後(可選地)將備選隊列重排序以用於Hit-Lighting。我們通過串聯兩種幾何體描述方式來實現這一過程;命中結果之後會被壓縮並有選擇地重排以用於Hit-Lighting,然後未命中的射線會被串行提交至天空光照計算。

總結
我們的硬件光追模型在UE4模型的基礎上改變相當多:
- 通過表面緩存,我們可以構建一個極簡的遍歷方案以實現性能目標。
- 添加一個遠場幾何體描述方式使我們克服了超量的幾何體實例複雜度問題,同時也允許我們顯著地增加射線追蹤的距離。
- 我們也展示瞭如何處理與Nanite網格資源集成時,由於內在幾何體LOD錯配導致的問題。
3 光追性能
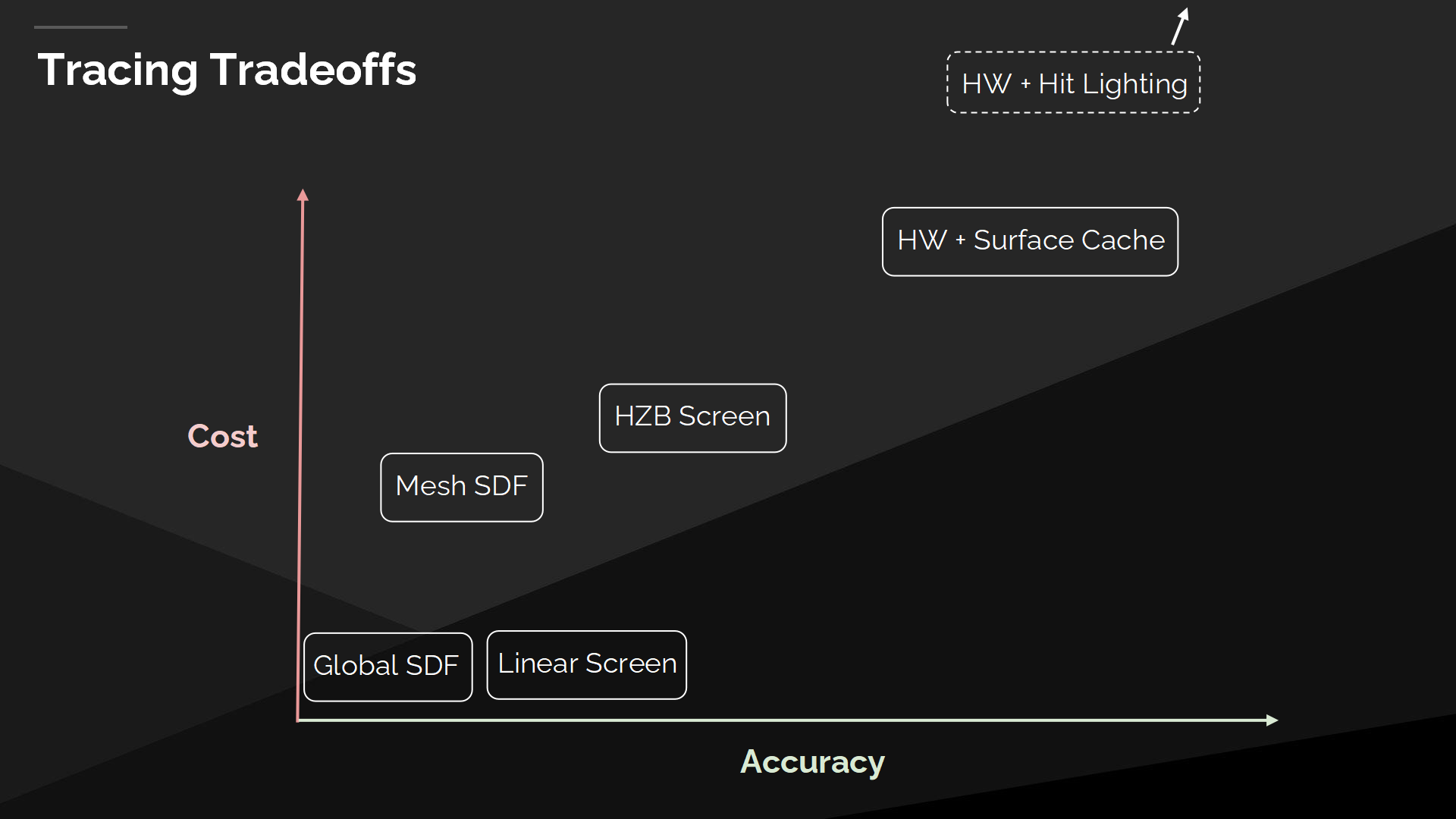
追蹤的trade off
如果我們按開銷和精度來繪製圖標,我們可以看到全局距離場追蹤(Global Distance Field tracing)是最快的,但也是最不精確的,因此它需要一個更精確的方案作為補充——例如屏幕空間追蹤,或是網格距離場(Mesh Distance Field)追蹤。
硬件光線追蹤是非常精確的,但也很昂貴,並且也並不真的有方法來降低規模(與開銷)。使用Hit-lighting的硬件光追方案甚至超出了圖標軸的範圍。
*其實這一頁比後面的很多純數據顯得更精華。

決定性的因素
使用Lumen的工程必須選擇一種追蹤方式。軟件光追適合需要絕對快速的追蹤的項目,它能在(當時的)次世代主機上以60幀運行。使用了kitbashing產生了大量重疊的網格結構的工程也應使用軟件光追(這裡kitbashing是一款3D工具軟件),正如官方例子“Lumen in the land of Nanite”與“Valley of the Ancients”之中那樣。
硬件光追適合需要絕對高質量的項目,例如建築視覺(Architectural Visualization)。以下類型的項目也應使用硬件光追:需要鏡面反射的項目,例如“The Matrix Awakens”;或是蒙皮網格需要明顯反映到間接光照中的項目(可動角色的反射之類)。

讓我們看看兩種追蹤方式在不同場景的性能表現——從“Lumen in the land of Nanite”開始,它包含了巨量的重疊網格。這是一個為Nanite壓力測試而製作的內容,洞穴中表面上的每個點都可能包含上百個重疊網格。使用硬件光追時,射線必須遍歷每一個重疊的網格,而軟件光追則有一個更快的融合版本。在這個內容上硬件光追的開銷是我們無法承受的。

在“Lyra”——UE5的樣本遊戲中,則是完全不同的情況。這裡的幾何體基本沒有重疊,因此硬件光追的表現非常好。兩種追蹤方式的開銷差距不大,質量差距也不大。因而兩種方式都是可取的,最終取決於硬件是否支持。

在“The Matrix Awakens”的DEMO中,兩種追蹤方式的開銷也幾乎一樣。硬件光追能提供高質量的反射,並支持遠距離的GI,因此是更好的選擇。
*就像沒有大一統的“全局光照”一樣,目前也完全還弄不出來大一統的“光線追蹤”——應用光追也還需要一事一議。
4 Final Gather
*這一節的大部分內容都涉及光照緩存
,在之前已經讀過這個方案的細節分享了,有些頁內容都是一樣的。不過考慮到本篇閱讀的完整性,以及部分內容確實有了迭代,因此每頁還是會提供翻譯和解釋。
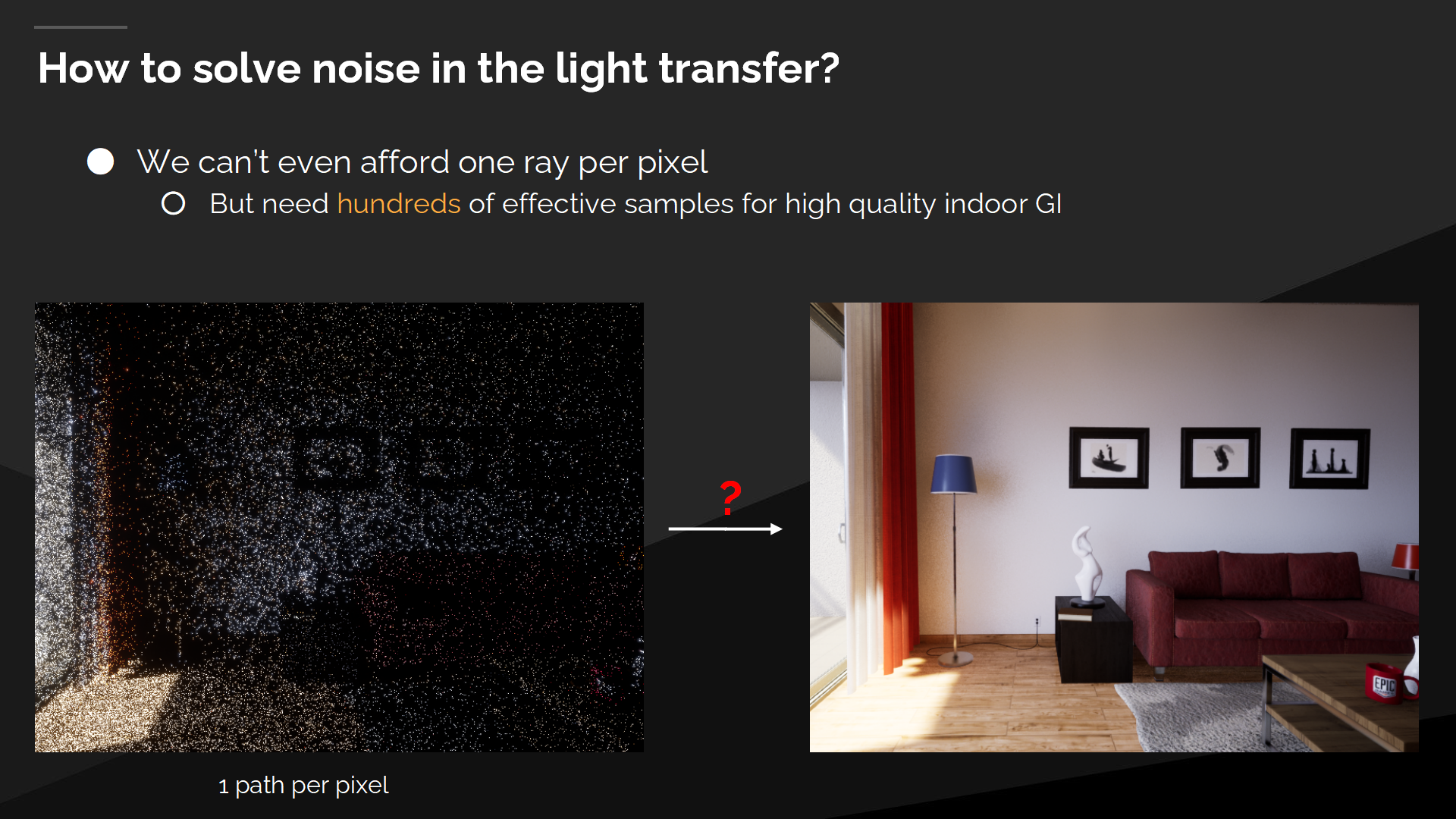
如果解決光傳播計算的噪聲問題?
第三個在實時間接光照中需要解決的基礎問題是——光傳播計算中的噪聲問題。
我們甚至無法負擔每幀每像素一射線。圖中左側展示了每像素一根射線會是什麼結果,而高質量的室內GI需要上百個高效的採樣。
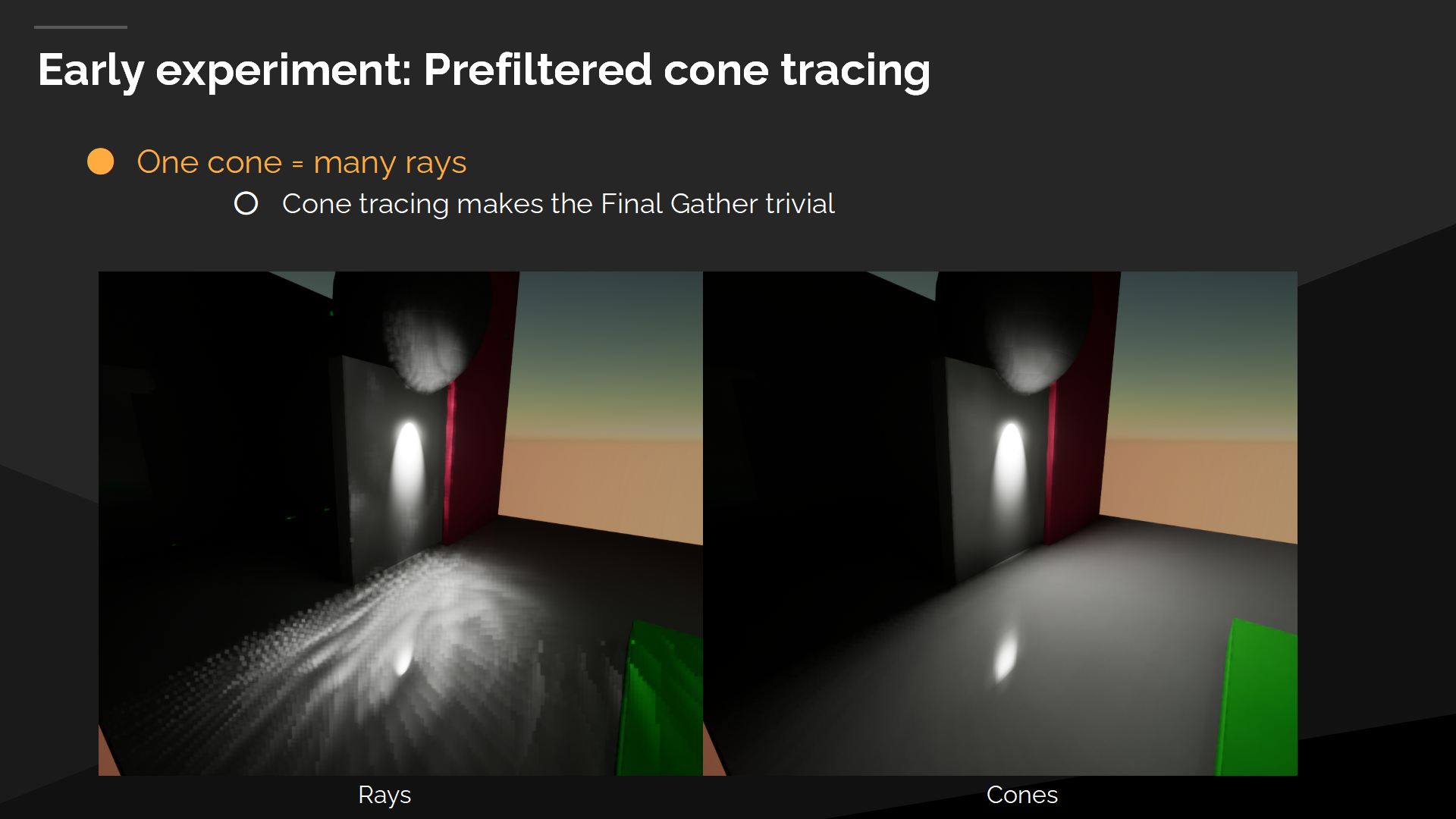
早期實驗:預過濾的錐體追蹤
One of our early experiments was prefiltered cone tracing. It’s very difficult to implement, but if you can pull it off, tracing a single cone gives you the results of many rays. Cones can be very effective at solving noise and they essentially make the Final Gather trivial.
我們的一個早期實驗是預過濾的錐體追蹤。這很難實現,不過如果能完美地完成它,那麼追蹤一個錐體就能提供追蹤很多射線的效果。錐體追蹤可以使噪聲處理變得高效,也就使Final Gather過程變得不重要了。

網格SDF錐體追蹤
We implemented cone tracing against Mesh Signed Distance Fields. Whenever the cone intersects a surface, we calculate the mip of the surface cache to sample using the size of the cone intersection, giving prefiltered lighting for cones that intersect.
我們實現了針對網格距離場(Mesh Signed Distance Fields)的錐體追蹤。但錐體與一個表面相交時,我們使用錐體相交的尺寸來計算表面緩存的mip,為這一相交提供預過濾光照。
When the cone has a near miss with the surface, it’s only partially occluded so this becomes a transparency problem. We can approximate how much the cone was occluded using the distance from the cone axis to the surface, which we can get from the distance field.
當錐體在近處表面追蹤失敗時,它只被部分剔除並帶來了一個半透明顯示的問題。我們可以基於錐體軸到表面的距離來估算錐體被閉塞的程度——這個值可以從距離場中得出。(*這裡說的是使用距離場方案可能導致無法正確處理障礙遮擋關係)
這使我們需要合併不同網格的多個局部命中——以無序的方式。我們選擇混合權重的順序無關半透明渲染(Weighted Blended OIT,Order Independent Transparency )策略,這在初始射線經過遠距離時會有顯著的漏光問題,但在近距離的漫反射間接射線上會有較少的漏光。
從圖中右側可以看出錐體追蹤是有效的,因為它不會產生明顯的(會產生噪聲的)硬邊緣。

錐體追蹤很適合處理噪聲問題,但
錐體追蹤在處理噪聲問題上是很高效的,但直到最後我們都無法處理全部情況下的漏光問題。我們只能在漏光和過度剔除之間做選擇,並且也無法在一個小的距離窗口上解決光照問題。
而且它也只能在軟件光追中生效。

蒙特卡洛積分而不是預過濾的追蹤
作為替代我們選擇使用蒙特卡洛積分方式(Monte Carlo integration,一種用採樣策略近似積分的方案)。這使得質量能提到最高的同時,也支持所有類型的光追(硬件、軟件),不過這把所有降噪問題留給了Final Gather來處理。

之前的實時方案:輻照度場
*之前的文章也提到過,Irradiance和Radiance這組概念翻譯一次後我就儘量保持原文了。
The most popular approach for solving diffuse light transfer is the Irradiance Field. Irradiance Fields trace from probes placed in a volume, then pre-integrate irradiance at the probe position, and then interpolate that to the pixels on your screen.
之前最流行的解決漫反射光傳播的方案是輻照度場(Irradiance Field)。輻照度場追蹤放置在一個體積(volume)中的探針,在探針的位置對irradiance做預積分,並通過插值得到最終屏幕位置的值。
這項技術的最大問題是irradiance是在探針上計算的,而不是像素上。這會導致漏光或過度剔除的問題,使得探針的放置變得很困難。
並且這也是一項體積描述方式,因此只能承受很低的空間精度,使得GI看起來很“平”。(*例如之前提到的球諧光照SH的低頻,或是低精度的cubemap之類)
之前的方案:從像素追蹤+屏幕空間降噪
在這個問題譜系(spectrum)的另一端,我們可以從具體的屏幕像素進行追蹤,並嘗試通過一個屏幕空間的降噪器來解決噪聲問題。
這也有其自身的一些問題。降噪器需要一組不相關的射線以得到全面的半球覆蓋,這意味著它們是不連續的,並且追蹤會很慢。
這使得降噪操作變得非常昂貴——因為它運行在屏幕空間上,並且沒有將採樣過濾(downsampled filtering)的機會。降噪器也有解除遮擋(disocclusion)時的問題,因為在新顯示的區域往往沒有足夠的樣本數量。(*這裡基本是逐像素分時降噪方案的常見問題)
需要找到介於兩者之間的方案
我們需要找到介於兩者之間的方案。我們希望有追蹤屏幕像素的精確性——例如間接陰影,但也要能顯著的降低開銷。

我們的方案:屏幕空間光照緩存
*到這裡就和之前一個系列聯動上了。
我們的方案是屏幕空間光照緩存( Screen Space Radiance Caching)。我們通過放置在屏幕空間像素的探針進行追蹤——這被我們稱為屏幕探針。
這是有效的自適應降採樣過程。圖中左側的探針是統一化放置的(uniformly 按固定距離),但在有更多細節的幾何體處,我們放置了更多探針。
在放置探針並進行追蹤後,我們對其radiance做插值,並得出同一平面上其它像素的radiance——這也能限制同一平面上像素插值的漏光問題,雖然本身就很難注意到。
我們會分幀“抖動”放置探針的邏輯格子(grid 這類概念都不翻譯成網格,避免混淆),並分幀積累以得到好的覆蓋率。

去年(2021)介紹的用深度表達的不透明Final Gather
在去年的講座中我介紹了Lumen的不透明Final Gather,不過之後我們在“The Matrix Awakens”的技術DEMO中進行了壓力測試。它成為了我們其它領域的原型,例如Volumetric Final Gather和紋理空間收集(texture space gather),因此我想分享一些那之後我們的洞察。
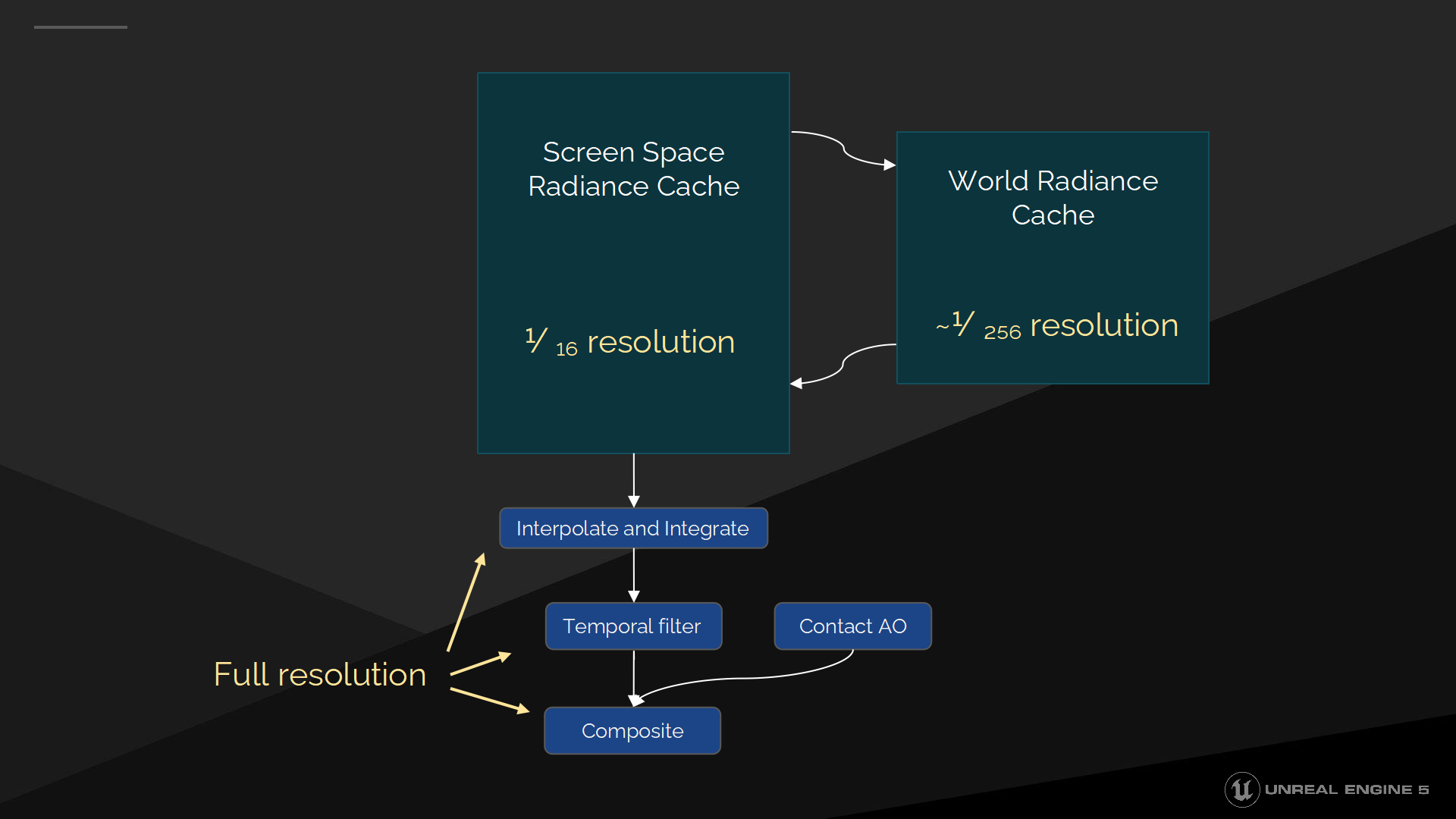
The opaque Final Gather has three main parts, first there’s the Screen Space Radiance Cache which is operating at 1/16th resolution in each dimension. It’s backed up by the World Space Radiance Cache, which is handling distant lighting at a much lower resolution. At full resolution there’s the interpolation, integration, the temporal filter and Contact AO.
不透明的Final Gather有3個主要部分,首先是屏幕空間光照緩存——在每個維度上以1/16的分辨率來操作;作為它的後備的是世界空間光照緩存(World Space Radiance Cache),以較低的分辨率處理遠距離的光照問題。在全分辨率上計算的有:插值、整合(積分)、分時過濾器和鄰接AO。
*resolution很多時候也兼具分辨率和精度的意思,前者更多是一個顯示規模概念,後者更多是一個存儲計算位數概念,雖然翻譯時只能用一個詞。

天空光照
圖中場景展示了一個在使用Final Gather時,從最遠到最近應用光照的例子。這裡從天空光照開始。

世界空間光照緩存
之後我們添加世界空間光照緩存,用以處理2米外的光照——圖中只有左側牆壁的部分(用到了)。
*雖然原文稿如此,但配圖中顯示其它部分例如床和地面也應用了光緩存效果,只是不那麼精確。

世界空間光照緩存
讓我們看看其中的探針。可以看到牆邊的探針非常精確地處理了窗戶位置,但右側的探針(採樣)卻透過了牆壁。

屏幕空間光照緩存
之後添加屏幕空間光照緩存,它負責抓取所有近處的光照,因此我們能得到間接陰影——但是在降採樣的空間中。

鄰接AO
最後是加上鄰接AO的樣子,用來補充我們在屏幕空間光照緩存中因為降採樣而丟失的一些陰影細節。
讓我們詳細看看屏幕空間光照緩存。
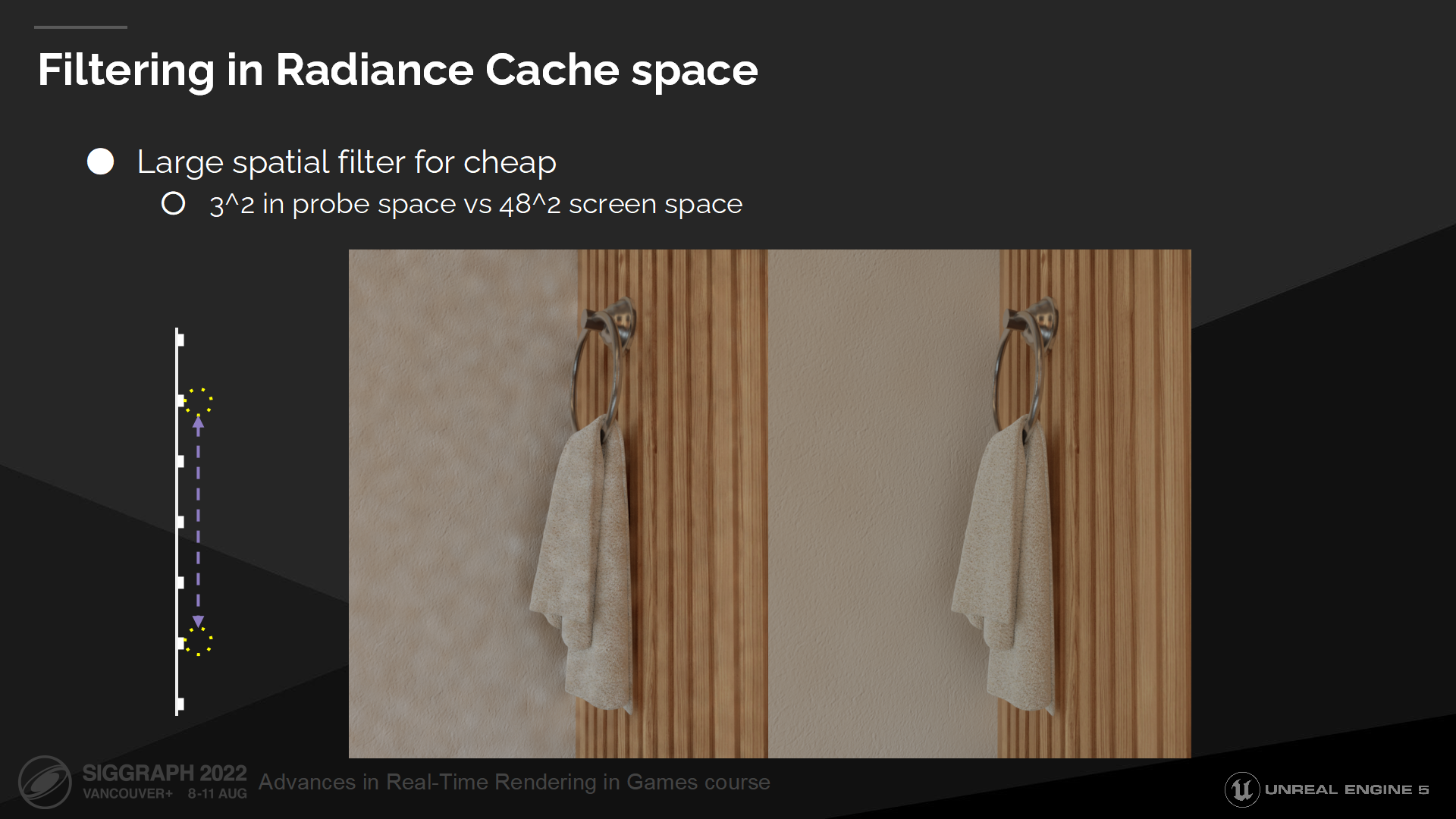
光照緩存空間過濾
因為我們在光照緩存空間而不是屏幕空間進行過濾,這使大空間的過濾開銷很低。探針空間中一個很小的3x3過濾核能帶來屏幕空間過濾48x48的核等同的效果。我們只需要加載探針的位置,而不是所有像素的位置和法線——以計算誤差權重。
*之前一個系列也提到過,廣義的“過濾”(filtering)可以理解為輸入一些東西,並按一定規則輸出一些東西。

對入射光的重要性採樣
We importance sample the incoming lighting. Importance sampling is only as good as the importance estimate, and we have a very accurate estimate of the incoming lighting from last frame’s Screen Space Radiance Cache, reprojected into the current frame. We can very efficiently find all of last frames’ rays because they’re indexed by direction as well as position in the radiance cache. Where the reprojection fails, like the edges of the screen, we fall back to the World Space Radiance Cache and still have effective importance sampling.
我們對入射光做重要性採樣。重要性採樣和重要性估計類似,並且我們基於上一幀的屏幕空間光照緩存能對入射光有一個精確的估計——通過重投射(位置)到上一幀的方式。我們可以高效地找到上一幀的所有射線,因為它們是按方向加光照緩存空間的位置組合作為索引。當重投影失敗時——例如屏幕邊緣處,我們以世界空間光照緩存作為備選,並且仍然能有高效的重要性採樣。
*這裡不如上個系列介紹的詳細,重要性採樣主要是解決射線預算有限時的權重問題——基於上一幀對目標入射光位置的定位。

乘積重要性採樣
We’re operating in a downsampled space, so we can afford to launch a whole threadgroup per probe to do better sampling. Product Importance Sampling is normally only possible in offline rendering, but we can do it in real-time.
我們在一個降採樣的空間中操作,因而我們可以負擔為每個探針分配一個線程組以得到更好的採樣效果。乘積重要性採樣通常只在離線渲染中可用,不過這裡我們可以實時執行。
乘積重要性採樣比起只對BRDF或光照(方向)做重要性採樣更好,比起多重重要性採樣(Multiple Importance Sampling)也更好——它能更快丟棄(其它方式中還需要計算的)低權重的追蹤方向。
(圖中)左側我們有牆上一個探針的BRDF,使得我們把方向限定在一個有效半球;在中間位置的圖中我們知道了基於上一幀的入射光信息,使我們得知了入射光主要來自兩個方向。我們將無用的射線重分配到(BRDF和光照的)乘積得出的更重要的方向上。(*結合圖可以看出,重分配射線就以超採樣的方式,把更高精度存儲到緩存中)

圖中的白線展示了我們為更重要的方向生成的超採樣射線。我們通過在這些方向追蹤4倍的射線以提升畫面質量,並且不實際產生更多射線。
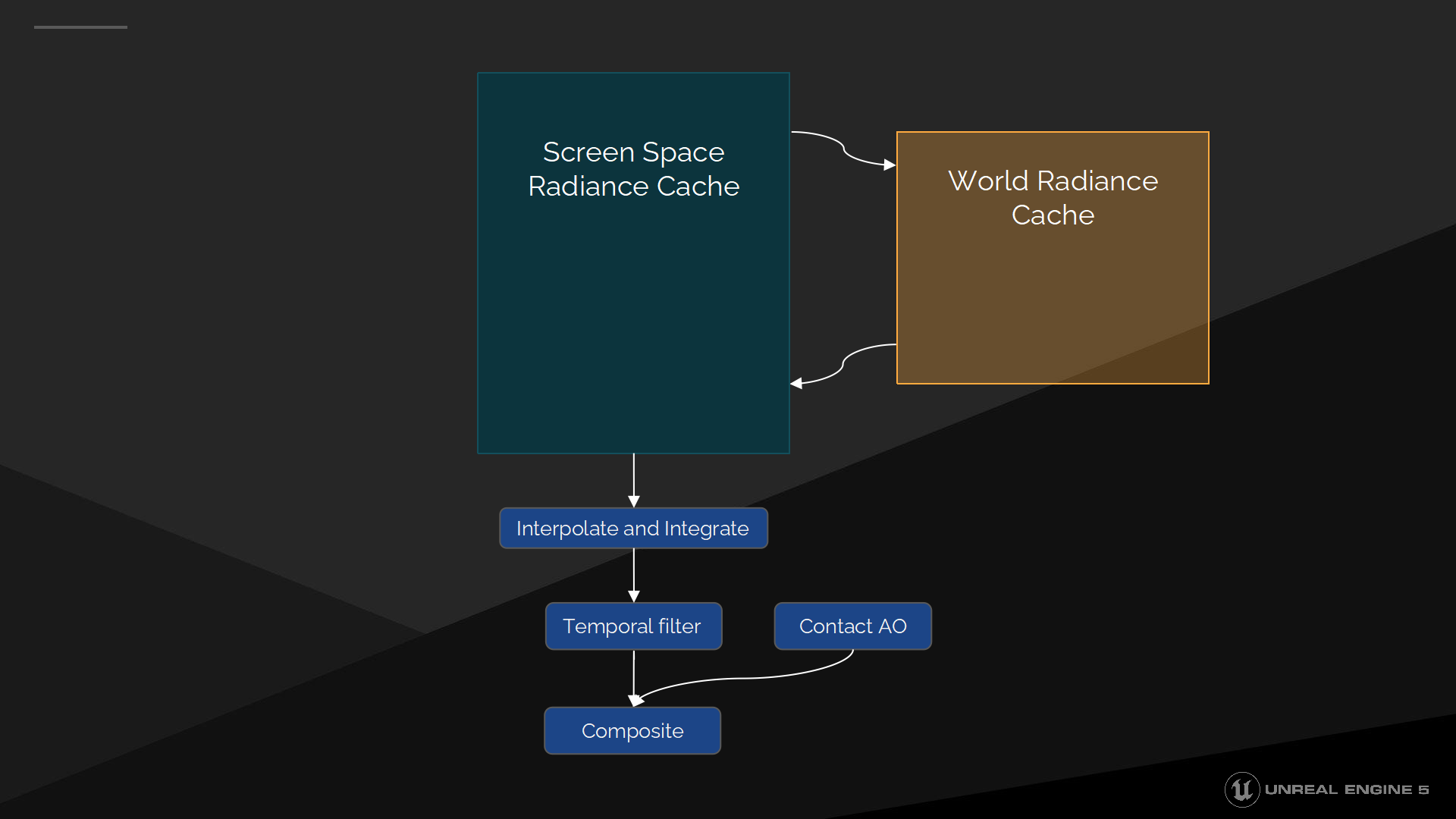
之後我們看看世界空間光照緩存的細節。
世界空間光照緩存
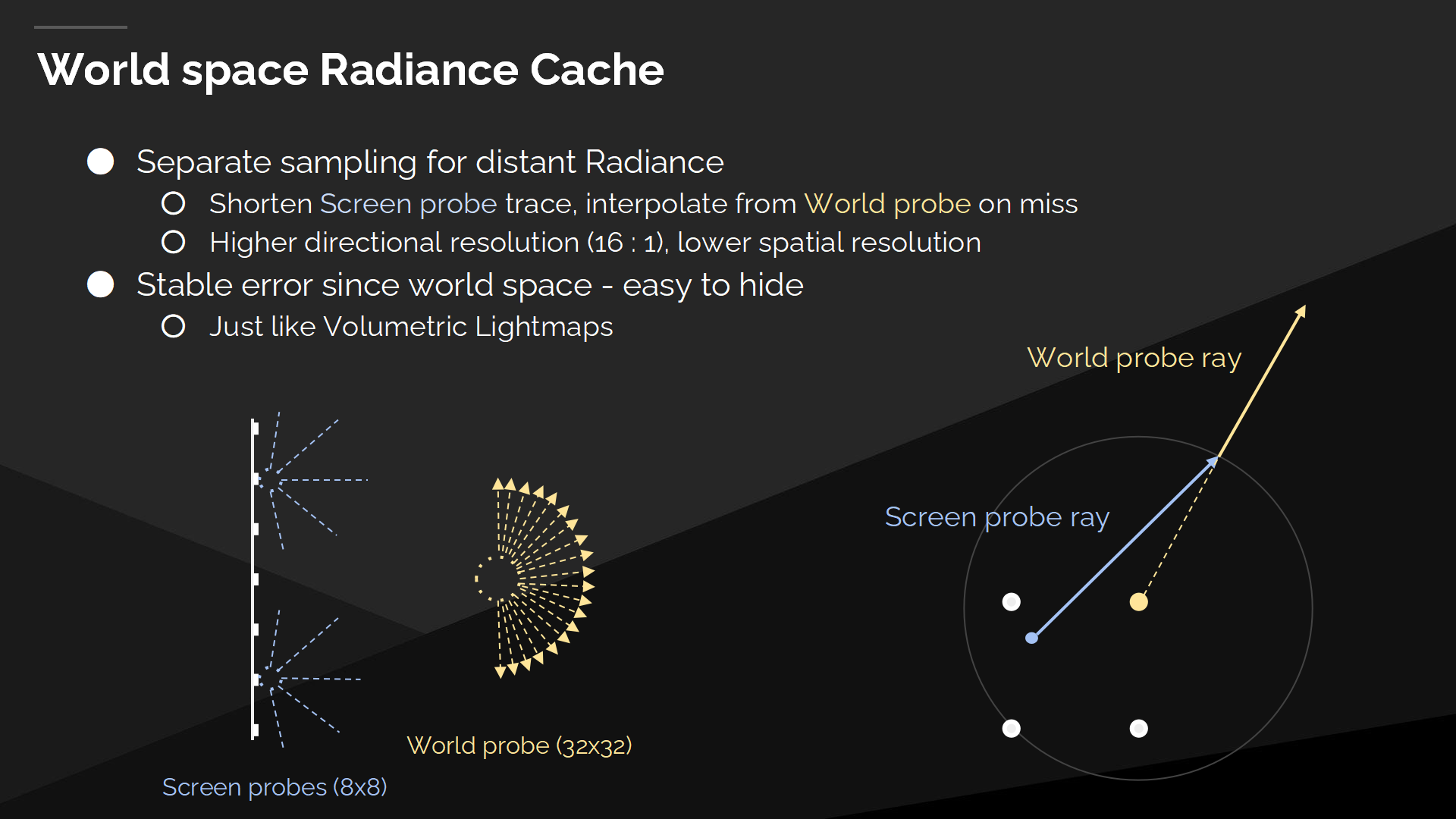
世界空間光照緩存是處理遠距離光照的,它有著更高的方向精度和更低的空間精度。它能解決例如房間的光照都來源自一個小的遠距離窗口,但會被較少的射線數錯過的問題。我們集成了兩種光照緩存方式——通過減短屏幕探針射線的長度,並在未命中的位置重世界空間光照緩存中插值。
世界空間光照緩存有著穩定的誤差——基於探針的位置是穩定的,因而(這種誤差)是容易被遮蔽的。

稀疏覆蓋
The World Space Radiance Cache has sparse coverage, and we use a clipmap distribution to maintain a bounded screen distance between the probes, to make sure that we don’t over-sample, or under-sample.
世界空間光照緩存有著稀疏的覆蓋,因而我們使用一個裁剪紋理(clipmap)分佈來維護探針之間的一個有邊界的屏幕距離,來確保不過度採樣或減少採樣。
探針數據使用了持存的(內存)分配,因而它們可以跨幀存在。

緩存
我們將上一幀中仍需要用到的探針傳遞到新的一幀中。之後我們對攝像機移動或場景移動產生的新探針位置進行追蹤。
我們也在整個世界空間重新追蹤一個子集以傳播光照變化。相比於上一年,我們已經通過一個GPU優先隊列來進行了改進,以選擇一組需要更新的探針——這帶給我們在更新整個緩存時也可控的固定開銷——即使緩存在被多個輸入來源操作。

The Matrix Awakens夜晚模式
“The Matrix Awakens”中有一個實驗性的夜晚模式,它是完全被自發光網格照亮的。場景的大部分燈光來自小而亮的電燈泡,因此處理它們的直接光照對我們的GI方法來說絕對是一次性能測試,因為我們不是明確地(explicitly)從光源進行採樣(*而是通過探針,但要算的光源很多)。世界空間光照緩存能更精確地解決直接光照問題——基於它在方向上的高精度,以及分時穩定性。
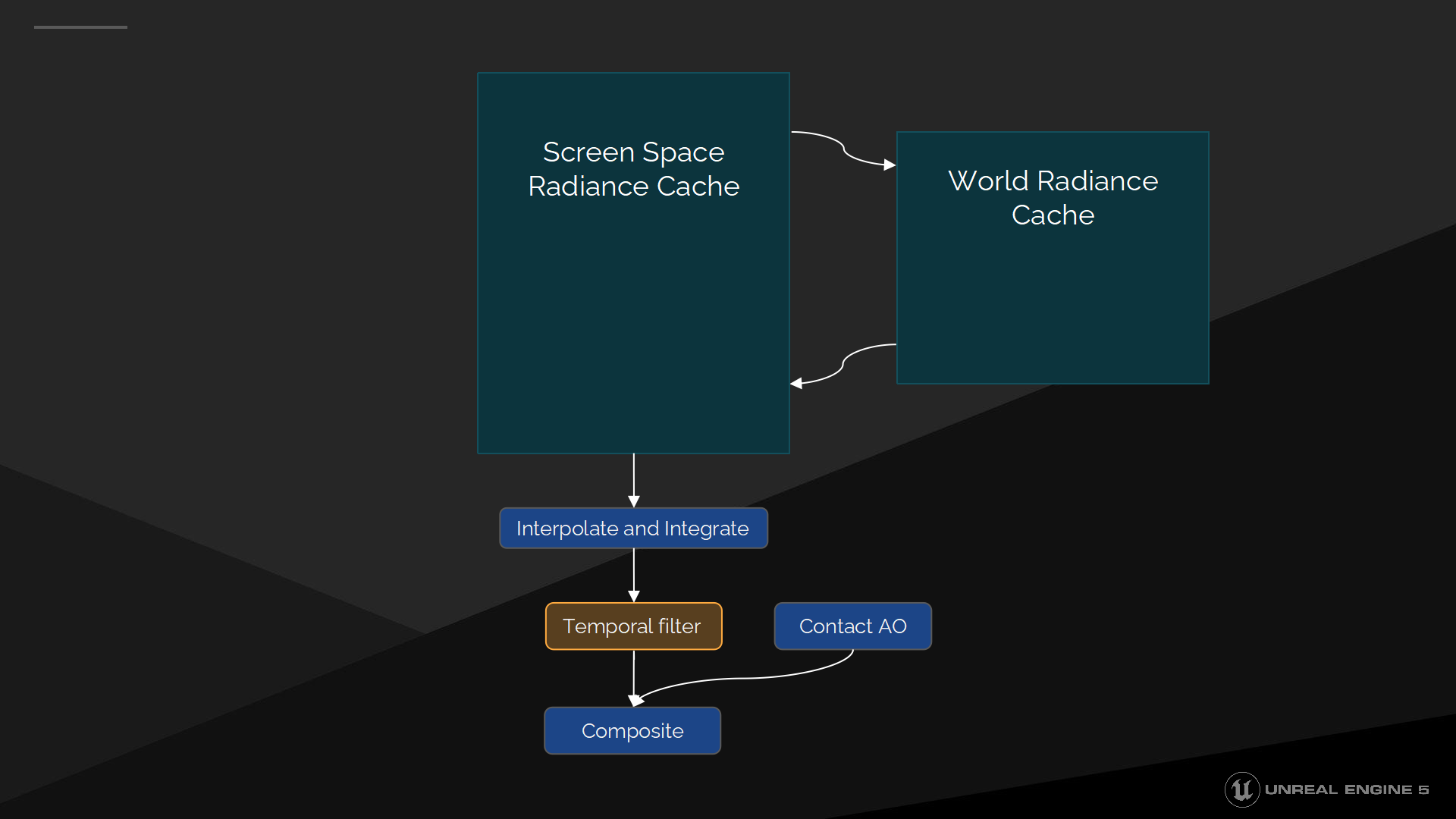
然後我們推進到全分辨率的分時過濾器。

分時過濾器
分時過濾器是用於覆蓋我們探針位置和方向上的抖動。我們需要一個穩定的分時過濾,因此我們不能使用鄰接對齊(clamp),作為替代我們基於深度與法線的差異來對歷史幀的數據做排除。
這帶來了穩定的結果,不過也導致了光照緩存更新緩慢的問題——圖中就展示了運動物體的鬼影問題。

改進
我們通過探測出“追蹤命中了快速移動的物體”以進行改進,並加快更新快速移動物體入射光源相關像素的分時過濾器。
我們也在分時過濾之後應用了最近範圍剔除(shortest range occlusion),因此這不會有任何延遲。
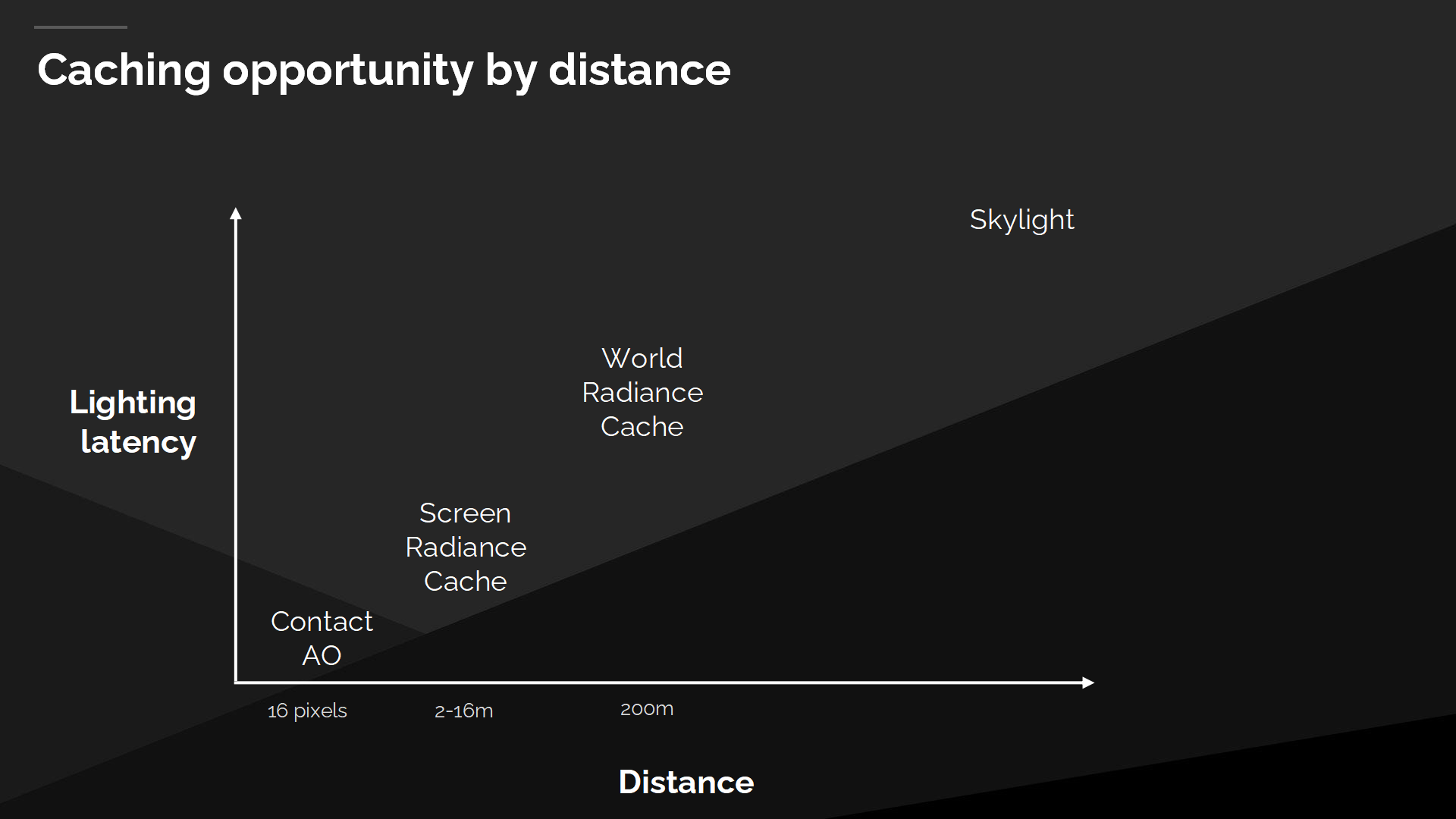
不同距離的緩存時機
在大部分場景的動態變化中,我們可以在遠距離的光傳播上允許更多的延遲。近距離的間接光照不能承受任何延遲,而天空光照的變化可以有很大的延遲。有趣的是我們已經設置併發揮了不同緩存時機中的優勢,在我們的Final Gather中已經將radiance劃分到不同距離的不同技術中。
*原文的“時機”更好的理解是“適合的場合與情境”——在上面的圖表中就是距離。
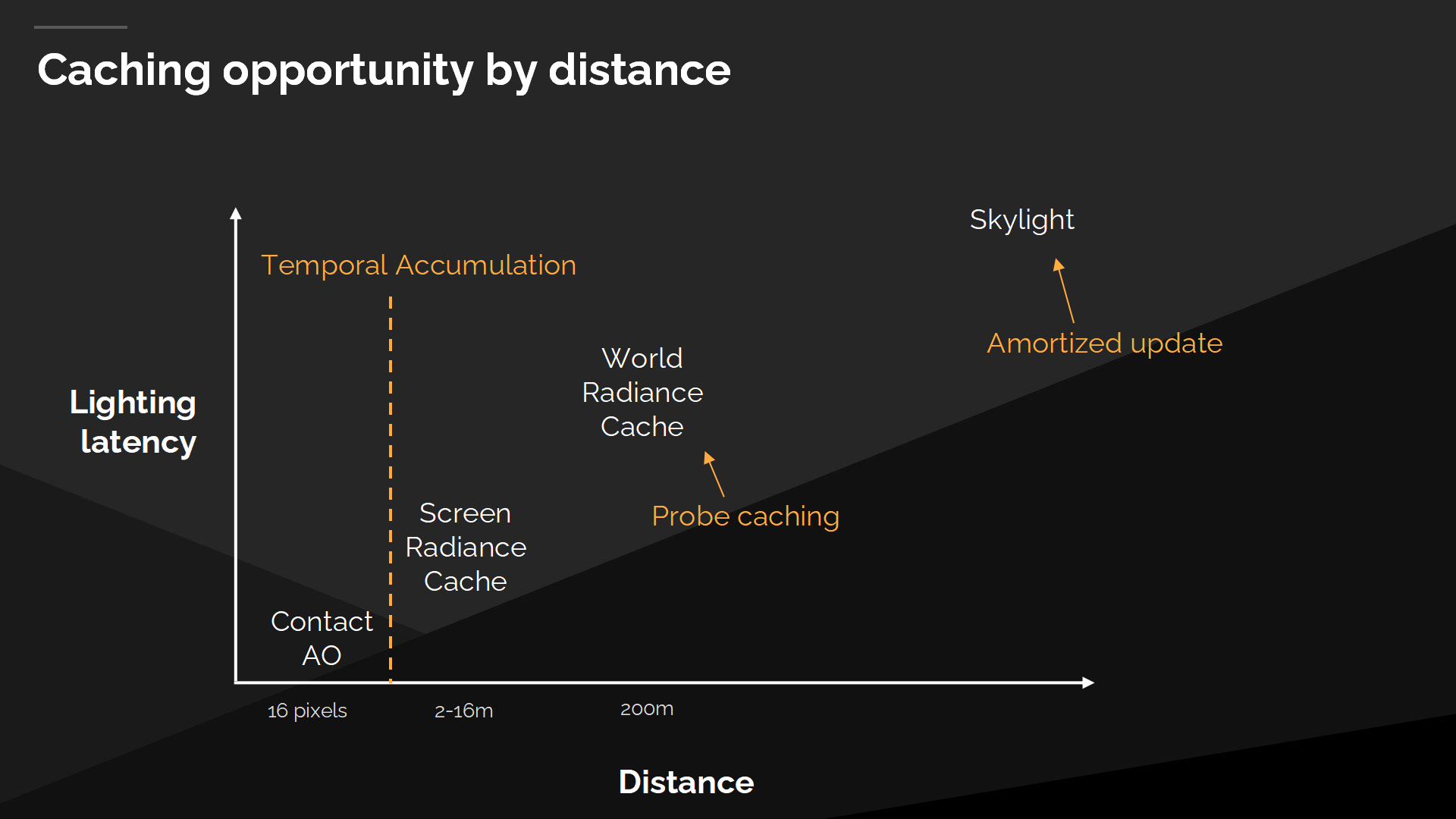
不同距離的緩存時機
我們可以利用屏幕空間光照緩存中可允許的延遲,對其進行分時累積;而對於世界空間光照緩存,探針可以從前一幀複用,而天空光照可以在很多幀之後再緩慢更新。

透射和霧的GI挑戰
*之前也提到過,Translucency更多指玉石、煙塵之類的物體,是不適合直接翻譯成“半透明”的。
下面推進到透射物體和霧的GI。對於透射物體我們需要支持任意數量的層,你可以看到如果不從天空光照投影時圖中的煙塵粒子是什麼樣的。(*亮度明顯不對)
對於霧我們需要在可見的深度範圍的任何位置都計算GI,我們需要在整個入射球體上計算,而不是基於法線的半球。
同時我們也只有1/8的不透明Final Gather的性能預算,因此我們需要一個非常快的方案。

體積Final Gather
Our Volumetric Final Gather covers the view frustum with a probe volume, which is a froxel grid. We trace octahedral probes and skip invisible probes determined with an HZB test.
我們的體積Final Gather通過一個探針體積覆蓋了視錐體,被稱為一個
視錐柵格(froxel grid)。我們追蹤八面體的探針並通過HZB檢測跳過不可見的探針。(*之前也說過froxel,是frustum和voxel的合成生造詞)
在追蹤並查找Radiance後,我們對空間上的radiance做過濾並進行分時累積,以降低因追蹤數較少而帶來的噪聲。
We then pre-integrate into Spherical Harmonic Irradiance and the forward translucency pass, or the volumetric fog pass, interpolates the irradiance.
然後我們將其預積分至球諧函數(Spherical Harmonic)描述的Irradiance,以及前向渲染的透射pass(或體積霧pass)中,並對irradiance做插值。

即使4X4的追蹤對於遠距離光照也不夠
即使通過很大數量的追蹤數,我們也無法解決遠距離光照的噪聲——例如圖中完全被天空光照從一個小洞口照亮的洞穴。
我們啟用了另一個世界空間光照緩存以用於遠距離光照,這能帶來高質量的方向精度以及穩定的遠距離光照。

透射的世界空間光照緩存細節
要把數據輸入這個世界空間光照緩存,我們需要在可見視錐柵格的各處放置探針。之後我們從探針處追蹤並預過濾radiance的值到mipmap中。
我們降低從froxel追蹤的距離,並且當其未命中時我們從世界空間探針中插值。追蹤世界空間探針的射線是從froxel追蹤的16倍,以降低走樣情況。
We overlap this new translucency Radiance Cache with the Opaque World Radiance Cache, so that it’s many dispatches fit in the gaps and it’s almost free.
我們將這一新的投射光照緩存與不透明世界空間光照緩存重疊,因此其中的很多派遣填充了線程上的縫隙,使其幾乎是無開銷的。
*基本上要對透射物體做高精度,都需要定製化的開發,泛用方案只能保證光照不穿幫——為之分配的性能預算太少了。例如要疊加複雜水體,那麼本身不透明場景的渲染精度可能就要相應調低,不然就會拖慢整體的性能。
5 反射
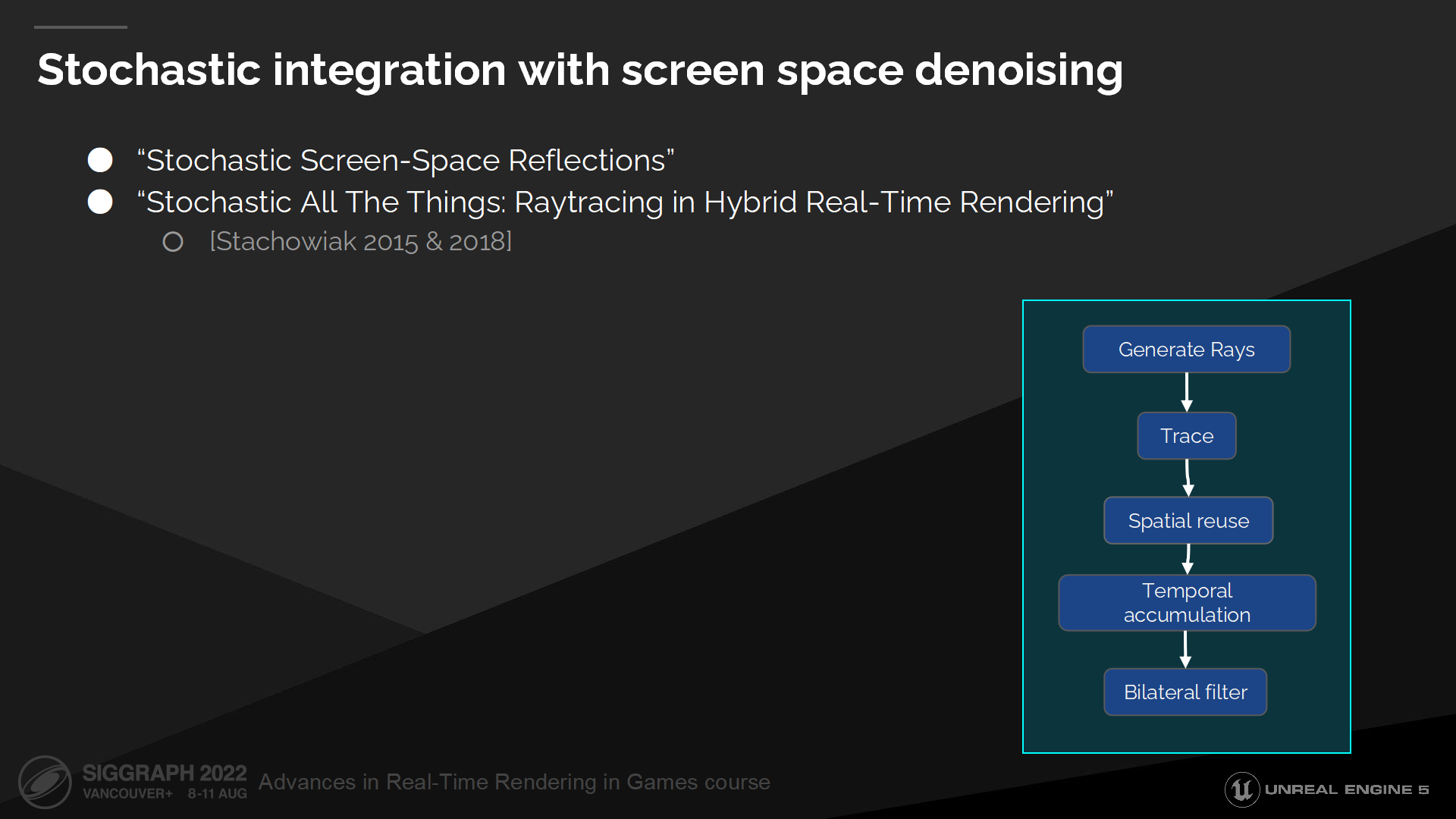
屏幕空間降噪的隨機積分
對於反射我們採用經過屏幕空間降噪的隨機積分,基於Tomasz Stachowiak講座中的內容。
Looking at our pipeline at a high level, first we generate rays by importance sampling the visible GGX lobe, then we trace the rays using our ray tracing pipeline. Then we run our spatial reuse pass, which looks at screen space neighbors and reweights them based on their BRDF. Then we do a temporal accumulation, and finally a bilateral filter to clean up any remaining noise.
從高層級來看我們的管線,首先我們通過對可見的GGX波瓣做重要性採樣來生成射線,之後我們通過光線追蹤管線來追蹤射線。再之後我們執行空間重用的pass,它能查找屏幕空間位置與相鄰位置,並基於它們的BRDF重新分配權重。然後我們執行分時累加,並最終用一個雙邊過濾器來清理殘留的噪聲。
*隨機積分(stochastic integration)是一個深刻的複雜話題,它的目標不復雜,但是計算理論對我來說太複雜了。
*GGX是一種微表面模型(microfacet models),是以函數模型的方式,通過一組係數描述微表面接收光照後的出射角度範圍與能量;波瓣則是以圖形來描述這種分佈的一種方式。更多信息可以去看看Games101,有講微表面模型的部分。

原始追蹤
從“The Matrix Awakens”中看看這些步驟,我們從原始的射線追蹤結果開始——這包含了很多噪聲。

空間重用
之後通過空間重用降低了一些噪聲,但仍然是可見的。

分時累積
之後我們應用分時累積,圖中的亮點被顯著地減少了,但在非常亮的區域仍然有一些噪聲。

雙邊過濾
我們通過雙邊過濾消除這部分噪聲。

分時抗鋸齒(反走樣)
*越高清的情況下,Anti Aliasing越不適合翻譯成抗鋸齒了,因為處理的就不全是鋸齒問題。
通過分時反走樣,我們進一步消除了噪聲。
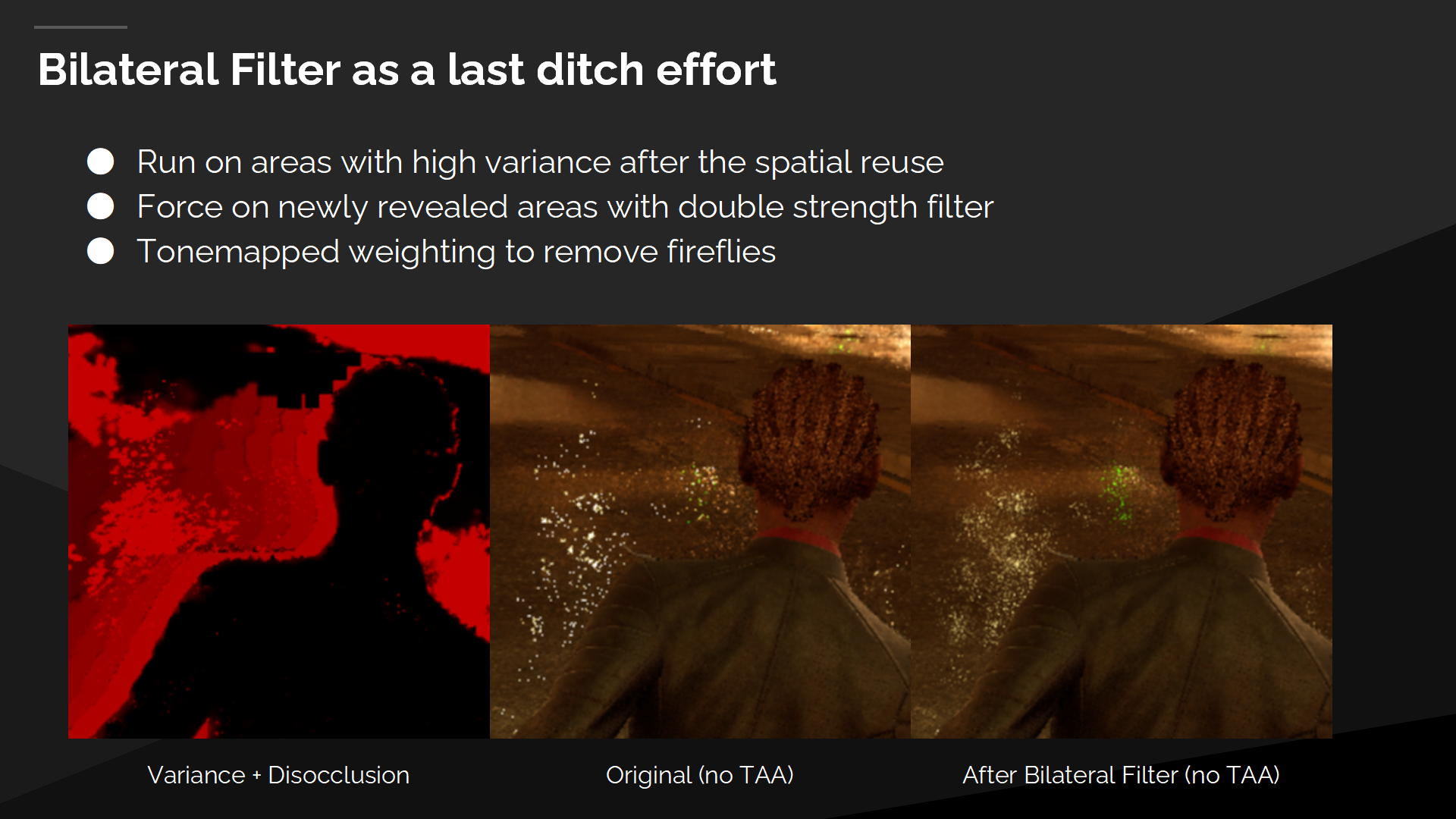
雙邊過濾作為最終的努力
The Bilateral Filter is our last ditch effort for when the physically based reuse isn’t enough. We run it on areas that had high variance after the spatial reuse pass, and we force it on at double strength in areas that were newly revealed by disocclusion, which don’t have any temporal history. We use tonemapped weighting in the Bilateral Filter to remove fireflies, which would crush our highlights if used in the spatial reuse pass, but works perfectly here.
雙邊過濾是我們在基於物理的重用還不夠時的最終努力。我們在空間重用後有較大差異的區域執行它,並強制在剛解除遮擋的區域以加倍的強度來執行——因為這些區域沒有歷史幀數據。我們在雙邊過濾中應用色調映射(tonemapped)權重分配以消除噪點,如果在空間重用pass中執行這一步可能會破壞高光的點,但在這一步(雙邊過濾)就能完美生效。
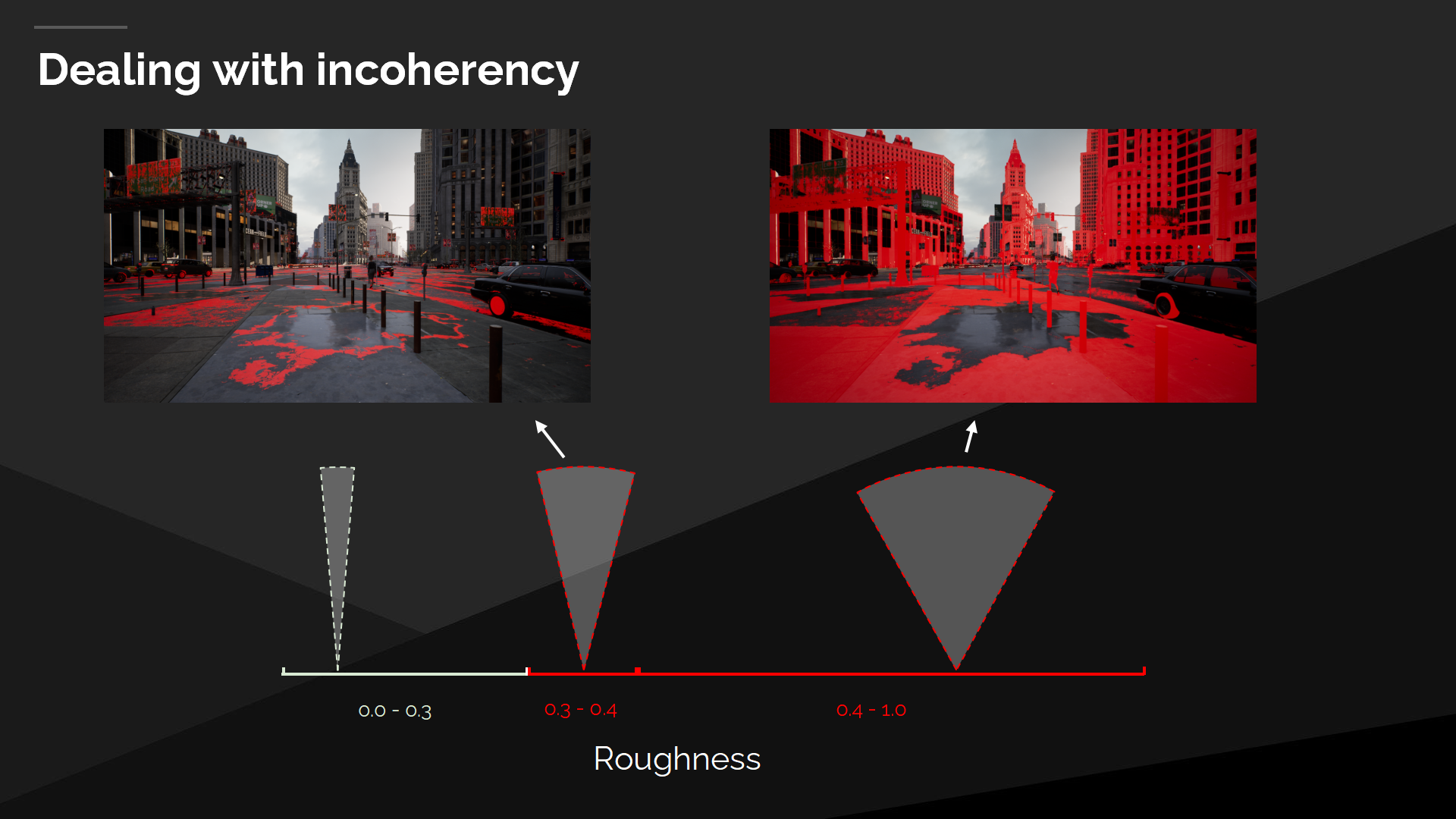
處理不連續情況
在處理反射時其中的一個問題是不連續的射線追蹤較慢。當材質的粗糙度達到1時,GGX波瓣變為了漫反射,我們的射線則變得非常不連續。
The roughest reflections from .4 to 1 often cover half the screen and they are a significant optimization opportunity. Then there are the glossy reflections from .3 to .4 which require more directionality but are also quite slow to trace.
對粗糙度在0.4到1之間的反射通常會覆蓋半個屏幕,它們是一個明顯的優化機會。對於在0.3到0.4之間的光滑表面,由於需要追蹤更多方向因而追蹤也很慢。
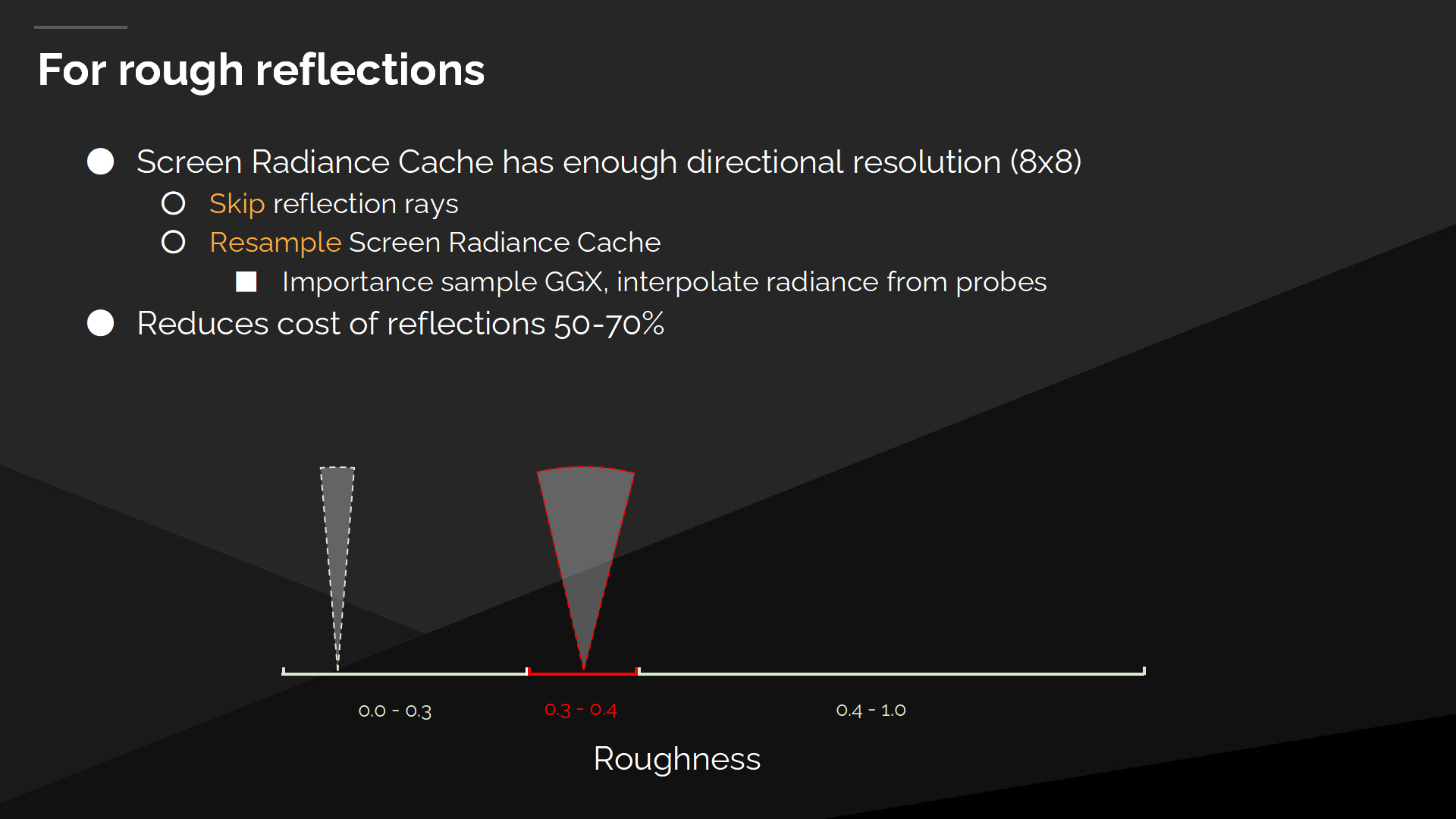
對於粗糙反射
We can solve the incoherency in the roughest reflections by just reusing the work that we did for Diffuse GI. The Screen Space Radiance Cache has enough directional resolution for a wide specular lobe, and we can just resample it, by importance sampling the GGX lobe to get a direction, and then interpolating radiance from the screen probes.
我們可以通過重用在漫反射GI中的那些工作來處理粗糙反射的不連續問題。屏幕空間光照緩存對於一個寬鏡面反射波瓣已經有足夠的方向精度了,因此我們可以對其重採樣——通過對GGX波瓣做重要性採樣的方式來得到一個方向,之後從屏幕探針之中插值radiance。
這降低了反射開銷——基於算法能跳過多少(原本需要反射射線的)區域,不過在多數場合開銷被降低了50%到70%。
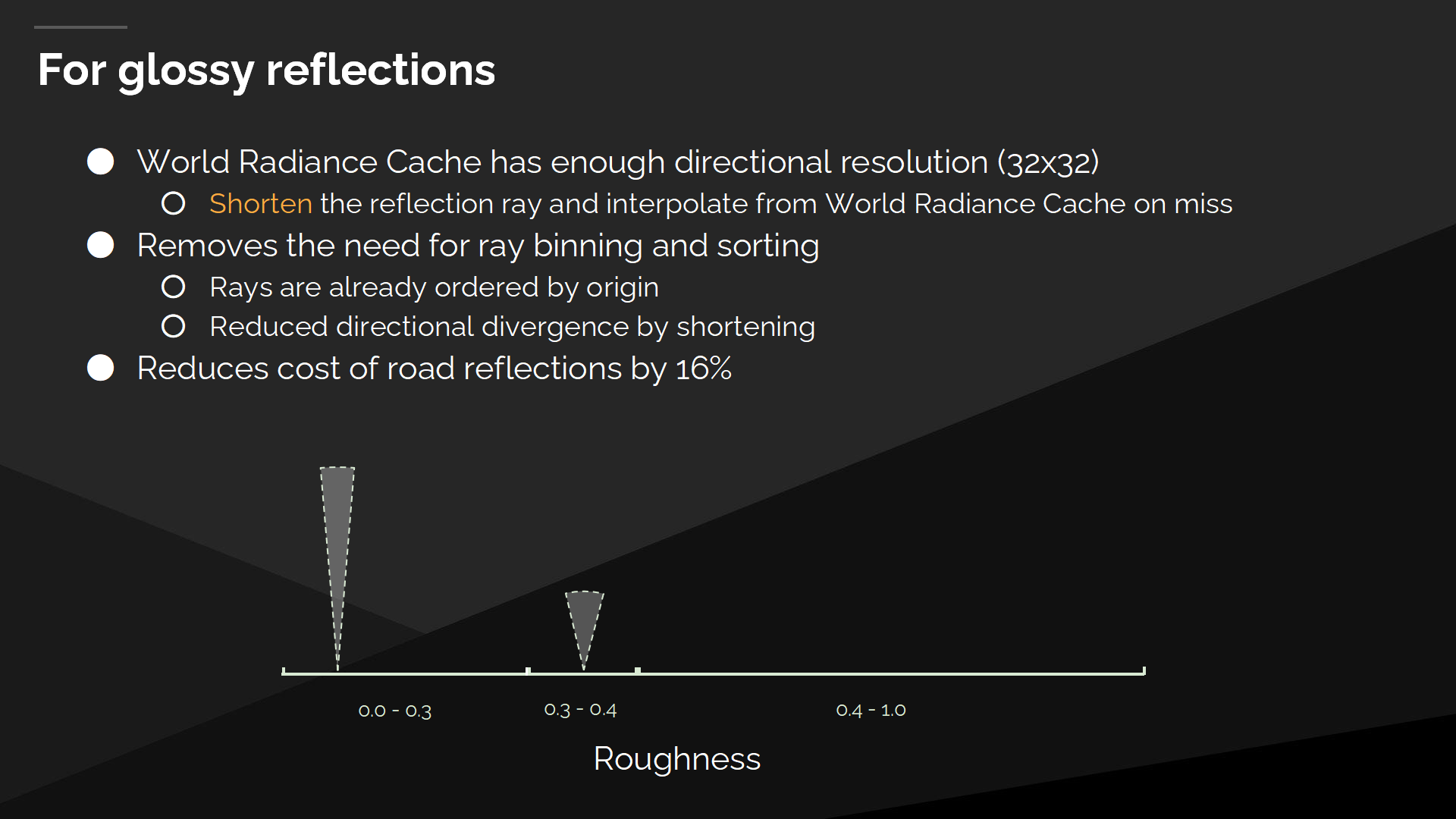
對於光滑反射
For that middle range of glossy reflections, the Screen Space Radiance Cache doesn’t have enough directional resolution, but the World Space Radiance Cache does. We shorten the reflection ray, and interpolate from the World Space Radiance Cache on miss.
對於中等範圍的光滑反射,屏幕空間光照緩存不能提供足夠的方向精度,但世界空間光照緩存能。我們縮短了反射射線,並將未命中的部分從世界空間光照緩存中插值。
這消除了對射線進行丟棄和排序的需要,因為我們通過縮短射線降低了方向上的差異,並且它們已經是基於各自原點位置排序過的了。.
在 “The Matrix Awakens”中,我們可以看到路面反射的開銷額外降低了16%。

通過重用的高效透明漆雙反射
我們也有非常高效的(基於重用的)透明漆(clear coat)反射。光滑的底漆部分可以重用屏幕空間光照緩存,因此我們只需要從頂層的清漆層追蹤新的射線。
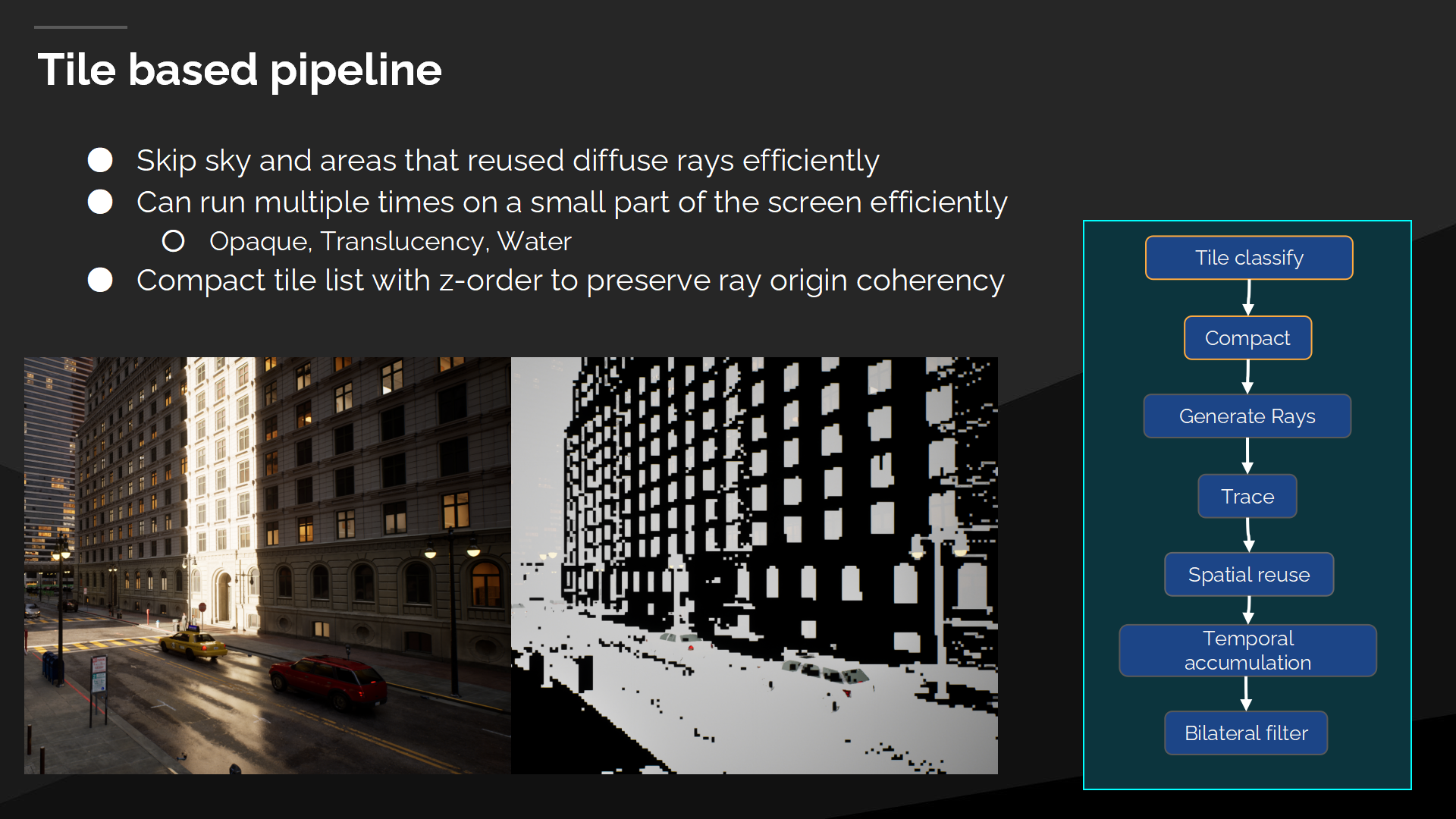
基於Tile的管線
我們的反射管線是基於tile的(*tile不特殊解釋的話都是指把屏幕分塊進行多線程處理)——這允許我們高效地重用漫反射射線,以跳過天空和部分區域。這點很重要,因為我們在管線中有很多派遣——如圖中右側所示,並在追蹤管線中有著更多(派遣數),能這樣只操作屏幕上需要的區域會有很大性能提升。
我們實際上會多次執行反射管線——視場景情況而言。其中至少對於不透明部分的反射執行一次,但也可能對於投射材質反射以及水體反射再執行一次,因此只操作屏幕中需要的區域是很重要的。

tile之外的分時過濾器鄰接對齊讀取
There’s a gotcha with implementing a tile based reflection pipeline - all of the denoising passes read from neighbors which may not have been processed. For the temporal filter’s neighborhood clamp, we could clear the unused regions of the texture, or branch in the temporal filter. It’s slightly faster to have the pass that runs before the temporal filter clear the tile border. We can only clear texels in unused tiles, to avoid a race condition with the other threads of the spatial reuse pass.
這裡展示了一個基於tile的反射管線的實現——所有的降噪pass從相鄰處的讀取可能是未被處理過的。對於相鄰對齊的分時過濾器,我們可以清理未使用的紋理區域,或在分時過濾器中做分支。在分時過濾器清理tile邊緣之前執行這個pass會略微更快一點。我們只能在未使用的tile上清理紋素(texel 大於一像素的圖塊),以避免其它線程對於空間重用pass的競爭狀態。
*這一段原文稍微有點繞了,其實主要是在說何時以及如何清理tile的邊緣。

透射物反射的挑戰
對於透射物體的反射,我們需要支持任意的層,並且我們不能直接從像素shader中追蹤,因此我們需要在像素shader外層來處理,之後再插值到像素shader中。同時,玻璃也需要鏡像反射,因此這部分我們不能做任何插值。

前景層追蹤新的反射射線
未提供這種玻璃反射,我們通過深度剝離(depth peeling 之前水體的文章介紹過)的方式把最前景的層拆分至一個儘量小的GBuffer中。之後我們再對有效的像素部分執行一次反射管線,並關閉降噪以減少管線負擔。

額外的層使用世界空間光照緩存
對於其餘層,我們再次使用世界空間光照緩存。我們使用與不透明Final Gather相同的光照緩存,只需要放置更多的探針。我們通過以低分辨率光柵化透射表面——來標記新的探針位置,之後標記每個像素位置需要的探針。
然後我們將透射部分光柵化至任意層,其中的像素shader都從光滑反射的光照緩存中插值計算。
結語

對其它技術分享的引用
這次引用列表就很好的反映出渲染技術與引擎開發是一項多麼需要積累的事情,而新的渲染技術越來越是“改”出來的而不是憑空造出來的了——其中多數人例如Wright都是虛幻引擎的核心開發人員。另外,設計一套中間數據結構緩存技術,並儘量重複用於多項不同的渲染模塊,也是現代引擎設計中最突出的一個思想。
原文還有“性能與擴展性”一節列出了一些數據,基於篇幅原因以及實際指導性不大的考慮,這裡就不翻譯了。我覺得看實際性能表現如何,可以去看看用虛幻5做的遊戲(一共沒幾個)——因為虛幻引擎的管線開放給開發人員干預的部分很少,因此實際的性能表現中引擎技術及其使用佔的比重是較高的。
最近的系列都在讀UE5技術分享的文章,一定程度上(至少對我個人來說)是一個逐步“打開黑盒”的過程。一方面可以看到Nanite和Lumen兩大模塊之間的設計與協調開發,以及其中少量磨合得不盡人意的地方;但更多的是看到了其它引擎開發商無法深入去探討與實踐的,屬於最高精度渲染才需要考慮的無數細節。
最後是資料鏈接:
Sorted-Deferred tracing pipeline [Tatu Aalto 2018] [Kelly et al 2021]的一個摘錄地址
Lumen: Real-time Global Illumination in Unreal Engine 5 的PTTX