众所周知,家族管理在数据统计上面是个脏活累活。依托现在OCR技术,其实可以减轻这一过程的负担。这一帖子一是技术交流,其次也是希望有老哥能帮我一起维护和使用我的
简介
理想的全自动过程是:(1)机器人进入深渊列表,(2)获取图片,(3)OCR识别,(4)生成结构化数据及可视化
由于(1), (2)步过程比较繁琐,我的实现还不稳定,而且有违规被用于非法用途之嫌,所以这里不公开及介绍这部分。(4)有空我单独开贴介绍。这里主要介绍目前我实现(3)步骤的大体思路。简单来说:如何上传图片到百度API识别,再拉下来试用。
大致流水线:
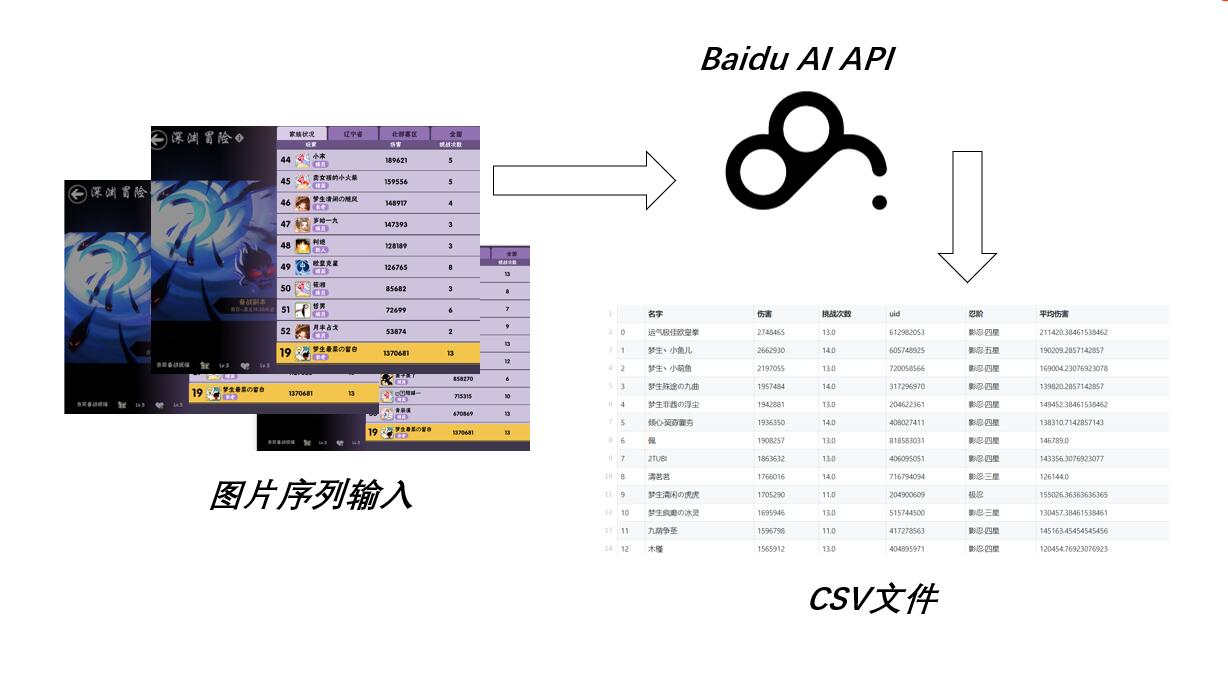 Disclaimer: 虽然这里用到了百度的技术,但这绝对不是百度AI平台的广告,我也没收过百度一分钱。这里只是分享这个技术在自动化家族深渊数据的应用。
Disclaimer: 虽然这里用到了百度的技术,但这绝对不是百度AI平台的广告,我也没收过百度一分钱。这里只是分享这个技术在自动化家族深渊数据的应用。第一步 你先要获得一张像这样的深渊的图片:
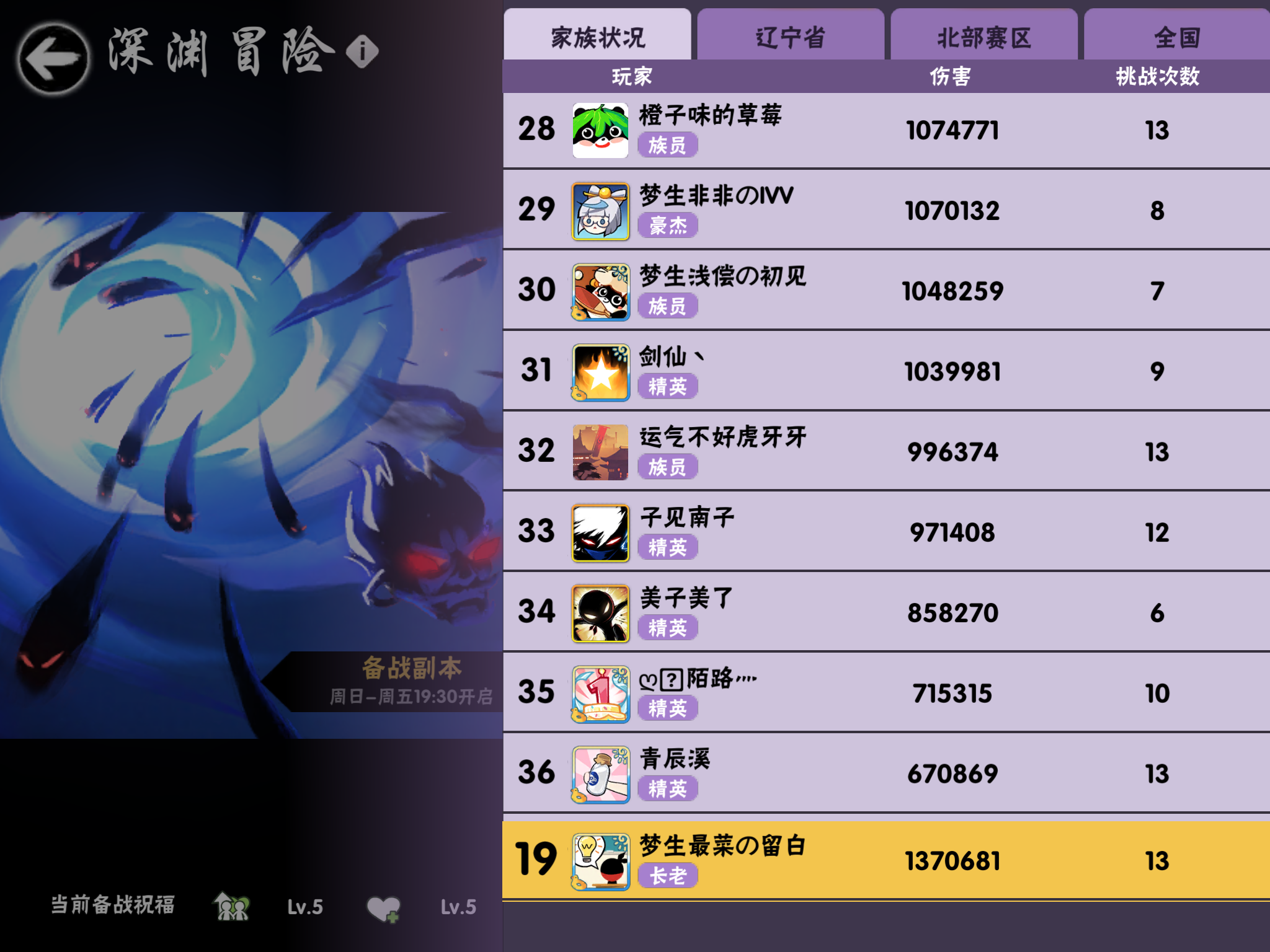 第二步 百度云账号申请,可以参考这个帖子前半部分https://www.jianshu.com/p/816cc6ef571b 第三步 进入OCR子模块:https://console.bce.baidu.com/ai/#/ai/ocr/overview/index
第二步 百度云账号申请,可以参考这个帖子前半部分https://www.jianshu.com/p/816cc6ef571b 第三步 进入OCR子模块:https://console.bce.baidu.com/ai/#/ai/ocr/overview/index第四步 点击iOCR-创建模板-上传模板图片(刚才的深渊图片)
 第五步 设置参照字段,用于程序校准,能够识别到深渊板块的位置。这里我的工程实践是选择:深渊顶部标签页的:家族状况、全国。下面的玩家、挑战次数。
第五步 设置参照字段,用于程序校准,能够识别到深渊板块的位置。这里我的工程实践是选择:深渊顶部标签页的:家族状况、全国。下面的玩家、挑战次数。 第六步 设置识别内容
第六步 设置识别内容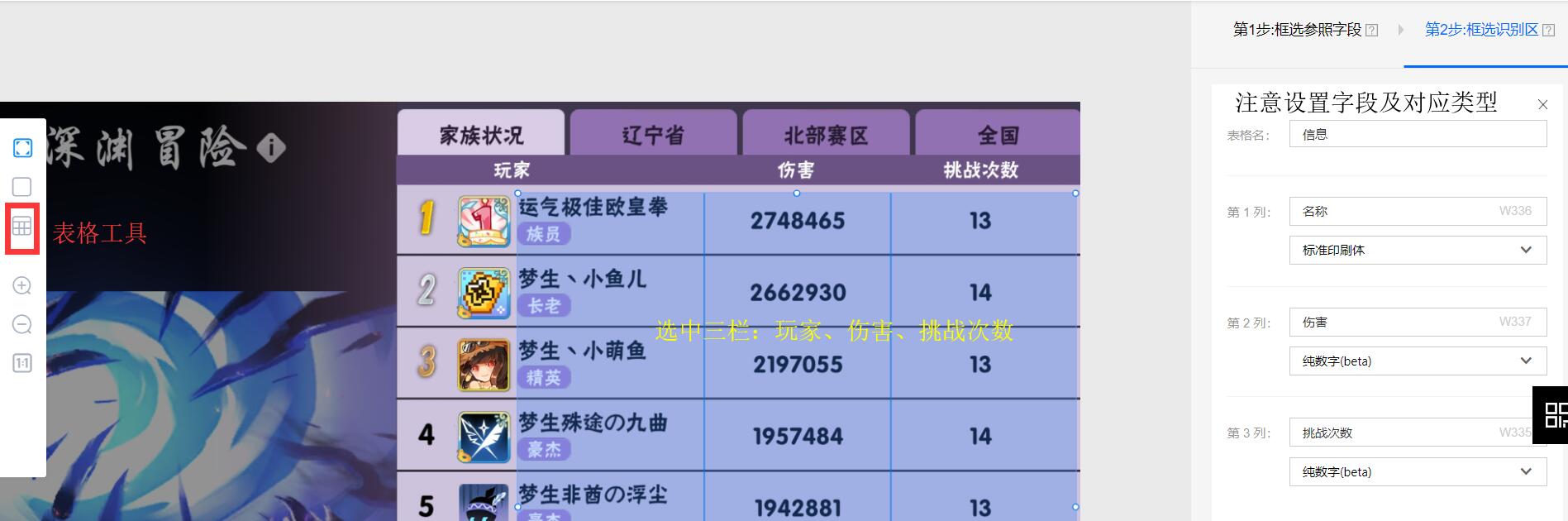 第七步 模板完成了,可以点击右上角试一试。在这里分享一下我的模板ID5e325de161f970154c1d11c26147712b
第七步 模板完成了,可以点击右上角试一试。在这里分享一下我的模板ID5e325de161f970154c1d11c26147712b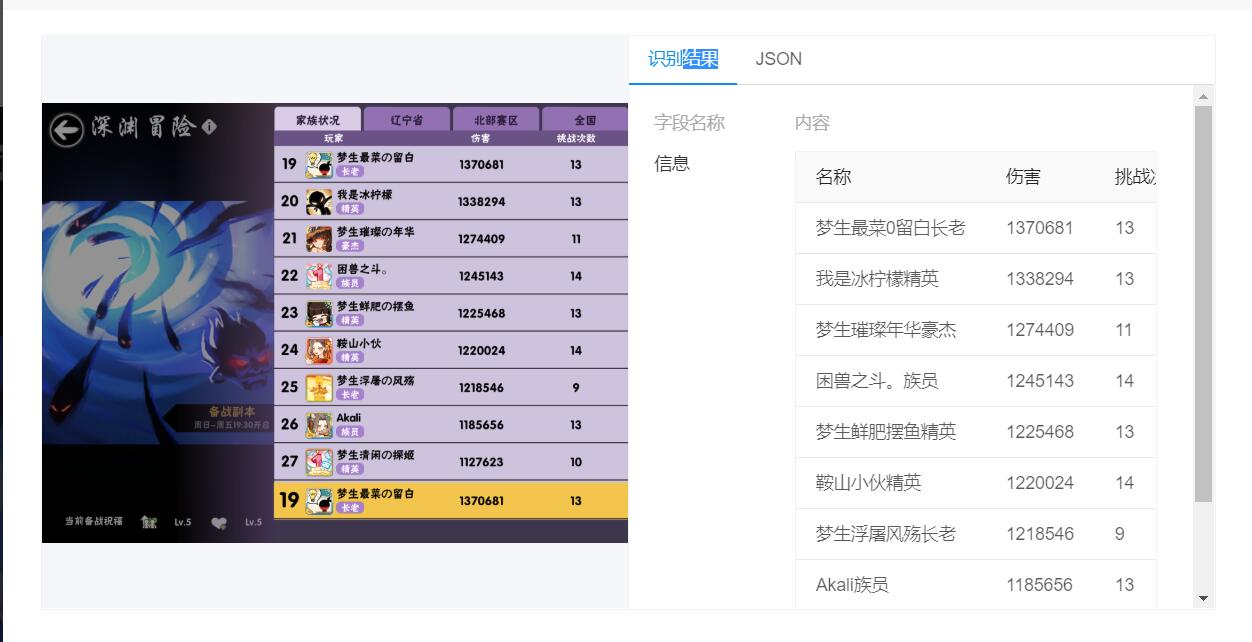 可以看到虽然有一些不完美,但是大体名字和数字还是很准确的。由于百度提供的是API(python可以pip安**aidu-aip库直接调用,很方便),我们可以借助本地脚本一些后处理,去和提前录入的玩家metadata做匹配(名字,UID等),来校准名字,最后输出成CSV文件。我的python实现在
可以看到虽然有一些不完美,但是大体名字和数字还是很准确的。由于百度提供的是API(python可以pip安**aidu-aip库直接调用,很方便),我们可以借助本地脚本一些后处理,去和提前录入的玩家metadata做匹配(名字,UID等),来校准名字,最后输出成CSV文件。我的python实现在
结束
毕竟是Tap论坛,在这里只是对我这个闲暇时间小项目做个推广,我不想写的太硬核。更多后续教程我应该会发布在我Github库的WIKI里。
最后,再招募一下有兴趣的家族管理和我联系。
1.希望至少有一定python基础。
2.此外,有测试相关经验的可以帮助我继续完善文档。有Web全栈能力的也可以试着将写下前后端(Web我实在苦手),方便没有编程技术的小伙伴。
3.有计算机视觉相关经验的也可以联系我。但目前为了程序效率,和不想标注数据(神TM还在游戏里加班标数据),不需要深度学习经验的小伙伴。更加希望对传统方法:基于HOG特征的图像搜索等等的联系我,便于宝物自动识别的工作。