前言
作为一个先看了《DOOM启示录》才迈进游戏行业的人来说,听了重轻老师《游戏帝国 第二季》中讲id software的部分真的感触很多。因此这周决定就从节目中提到的BSP开始,简单讲讲游戏中空间划分(Spatial Partitioning)的脉络和应用。
游戏中的空间划分思想往往由加速数据结构和遍历算法两部分构成,两者配合得当时就可以得到以空间换效率的效果,一定程度上突破当时画面渲染物体数的上限。一般来说加速结构是基于预计算的,因此会对动态物体有诸多限制——动态物体较多时每帧需要重算的数据量较大,甚至可能无法通过加速结构来优化,这往往意味着整体画质会下降。(*前一期有一个评论说战地游戏里的场景破坏要素少了,可能就是精度上去了反而破坏不动了)
由于最早应用到游戏中已经是90年代,那还是一个前显卡时代,本文介绍的有些技术现在已经是时代的眼泪了,随着硬件的发展仅保留了部分思路或者产生了全新的做法;新时代的加速设计更多是面向GPU的并行计算特性。
本文最后一节会介绍的Clustered Forward Rendering虽然也会对空间做划分,但这种运行时的划分更多是基于并行计算了(中间仍可以采用预计算的空间划分加速结构,两者不矛盾)。介绍这一课题时会节选一小段《Siggraph2016 - The Devil is in the Details: idTech 666》的内容,带大家一起看看一下新DOOM中对于这项技术的应用,作为对写本篇初衷的一个呼应。(原文标题就有 idTech 666,具体不知是什么梗)
1 BSP——Binary Space Partitioning
关于如何划分二维空间可以去听机核《游戏帝国 第二季 EP4》中重轻老师的讲解,或者是参照我后面提供的Wiki地址或其它网络资料。例如第一步切割的时候,结果如下图:
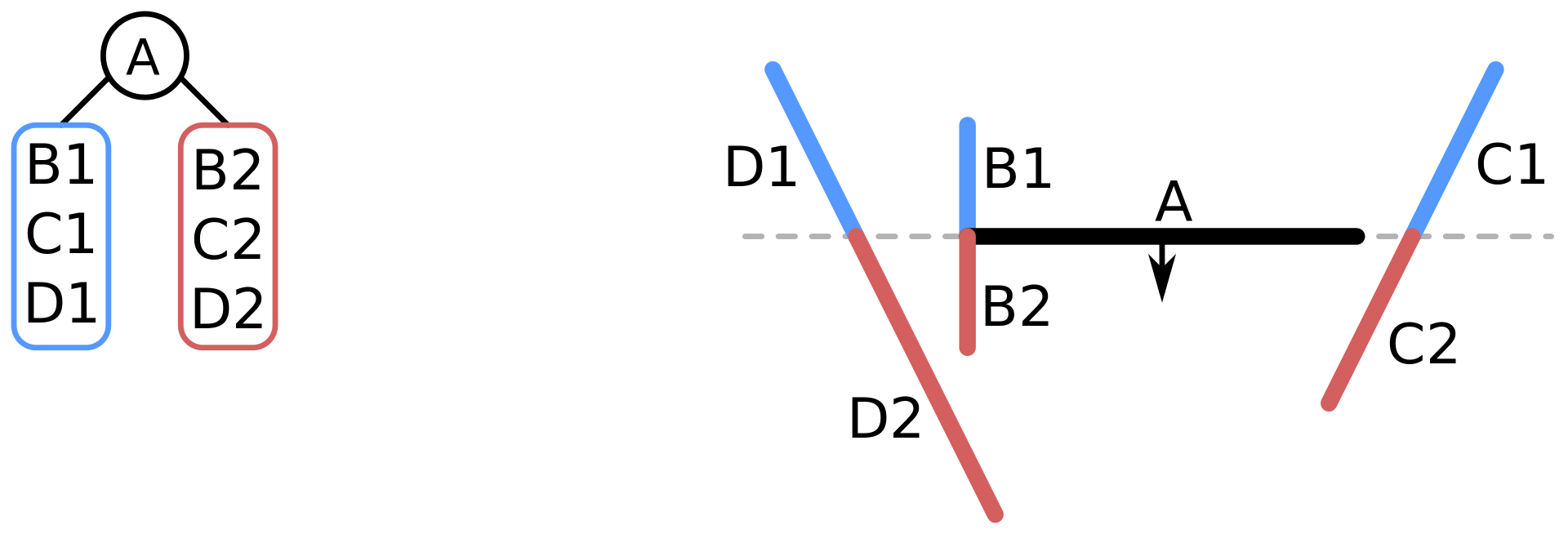
作为这里的平面切割的例子,每个被完整切割的节点都包含一个线段及其方向。理论上得到的二叉树尽量左右平衡最好,如何选取开始切的这条边在Games101系列课中也有论述,有兴趣也可以去看看。
以图中切割完毕的结果为例,左侧节点为后,右侧为前,线段对应双面多边形。这里简单的把对应的遍历方案来过一遍:
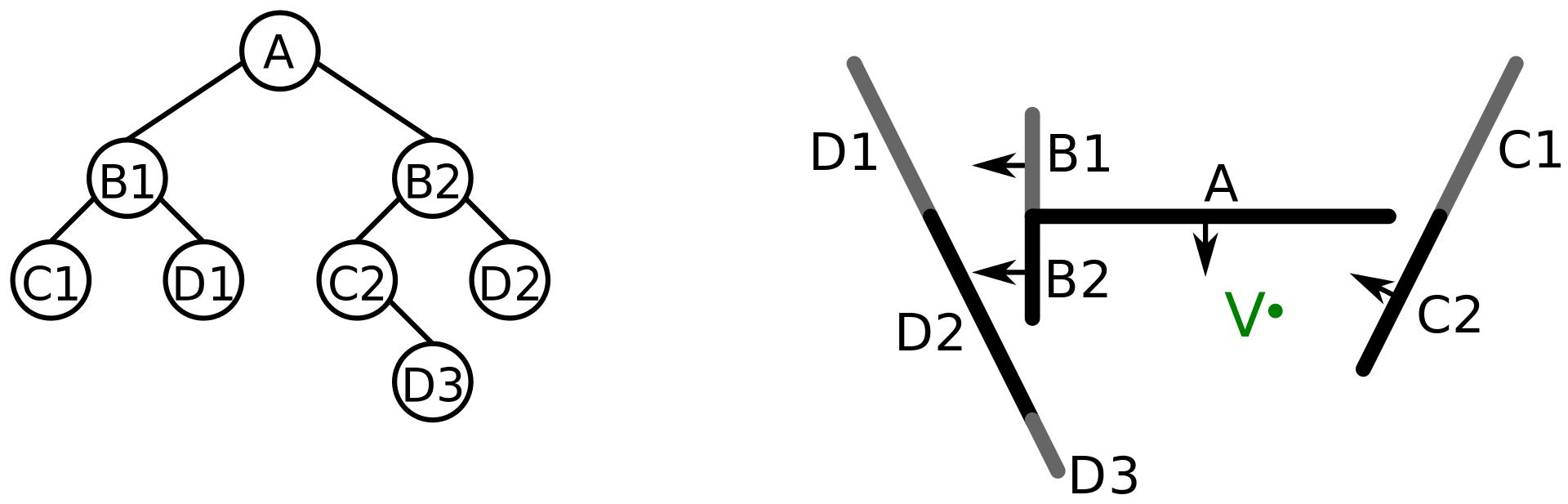
针对已经划分好的树,从V点遍历
基本的遍历算法可以描述如下:
1)如果当前是叶子节点,则渲染其多边形
2)如果V在当前节点前面:
3)如果V在当前节点后面:
渲染右侧节点对应的多边形——渲染当前节点对应的多边形——渲染左侧节点对应的多边形
4)否则V点一定在当前节点的相关平面上,那么:
渲染左侧节点对应的多边形——渲染右侧节点对应的多边形
下面来推演执行一下。假设视点为V,从树的根节点A开始(递归进行):
- A——V在A前面,类型2,进入B1;
- B1——V在B1后,类型3,进入D1;
- D1——叶子节点直接渲染;
- (回上一级)B1——渲染B1,继续类型3,进入C1;
- C1——叶子节点直接渲染
...
按这种递归思路,最后得到的渲染顺序是 (D1, B1, C1, A, D2, B2, C2, D3) 。当然实际运作时也可以先排序再考虑渲染的问题。
*再联动一下《游戏帝国 第二季 EP2》,其中有提到当时某个加速卡Z-Buffer过慢导致动态物体闪烁的问题,当时之所以静态物体不需要Z-Buffer就是被BSP解决了场景排序。
常见的三维BSP划分有两种:基于多边形表面的划分和基于轴对齐的划分。基于多边形表面的划分,这样划分完后每一段是可以严格落入一个叶子节点的;而基于轴对齐的划分是一类比较粗略的划分,但好处是有更快的计算性能(少用或不用除法)。
其它还有一些游戏中常用的基于轴对齐的划分方式,如:KD树、四叉树、八叉树等,分别有其不同的划分方式和遍历方式,这里就不展开了。(*其中KD树可以认为是一种特殊的轴对齐BSP树)
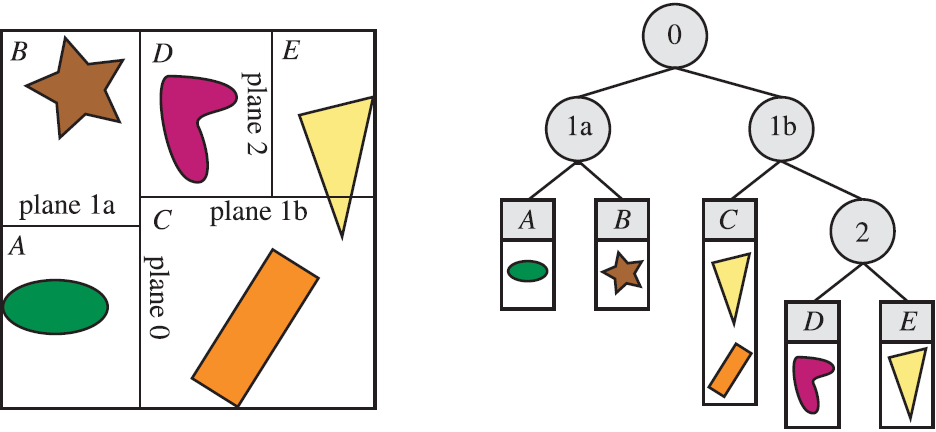
轴对齐BSP
对于一个物体落在两个区域的情况(图中黄色三角),划分时要么使其存储在上一级节点中,要么使其分别存储在多个子节点中。前者有精度不足影响效率的问题,后者有如何规避计算渲染两次同一个物体的问题。所以实际各种划分方式都在尽力规避这种情况。
2 PVS——Potentially Visible Set
在3D引擎蓬勃发展的过程中,很长一段时间内场景渲染最好的加速方式就是算好遮挡剔除(之前有一篇文章简单介绍过)。某一段时间,对于分房间的室内场景人们提出了Portal方式渲染和PVS(最小可见集)加速结构,简单来说就是分房间,并提前确定房间之间的可见性。
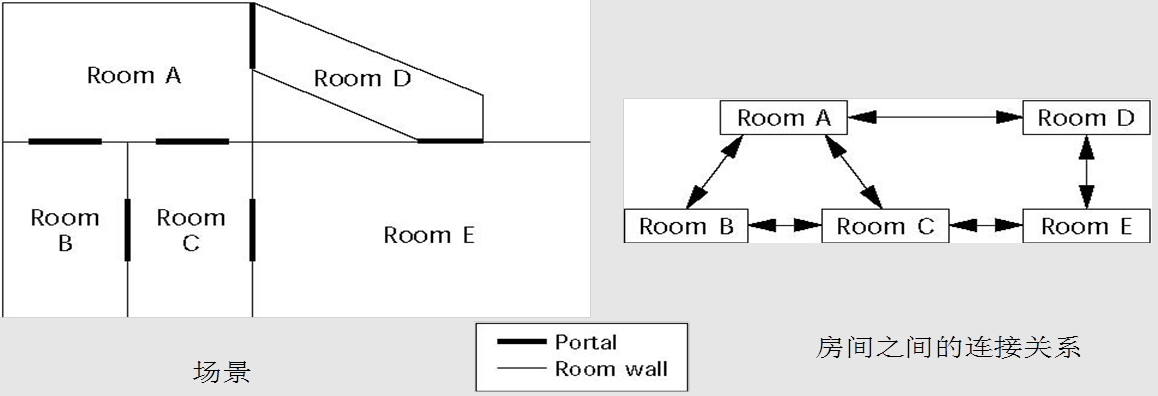
一个简单的房间关系的例子
其中portal渲染指的是计算当前视锥体内再额外划分出的一些小的视觉通道(如门、窗等),PVS则可以为这个思路额外排除一些确定看不到的房间及物体。
以图中A房间为例,即使A房间内视锥体可以覆盖到E房间,但经过3个portal和对应的PVS也排除了E房间。
不过这个方案局限性也很明显,除了明显需要更多存储和内存以外:
- 必须是以房间为主的场景
- 房间的关系需要一定的人为定制来保证
- 不支持无限破坏房间增加不可预期的portal出口,不支持完全动态的场景
3 BVH——Bounding Volume Hierarchy
BVH(包围盒层级)是对空间中物体的另一种划分方式,主要用来解决可见性问题(通过求是否相交)。如果说BSP、KD-Tree之类都是空间划分(Space Partitioning),BVH则是一种物体树状层次结构——下面简称物体划分。
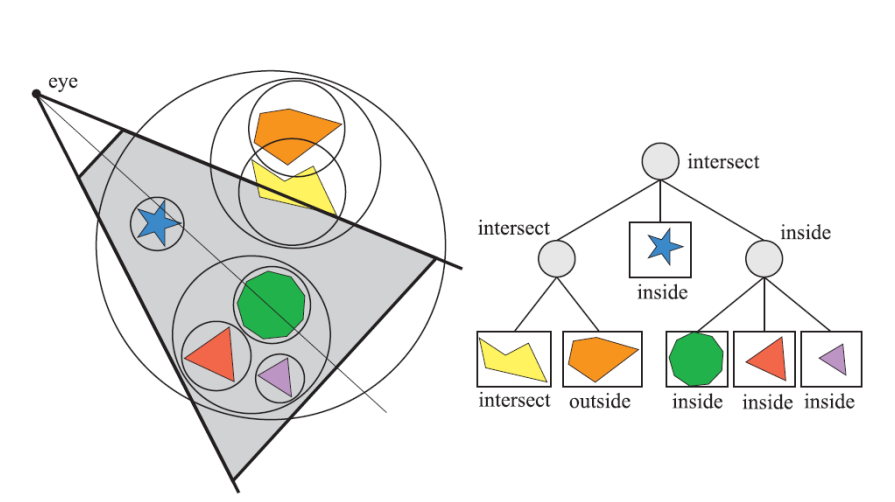
BVH遍历的例子
BVH遍历的基本思路是:如果和父节点(大包围盒)相交或包含,逐步检测子节点是否相交或包含;可以略过完全不相交的节点及其子节点。
考虑到游戏中物体多边形复杂度逐渐提高等原因,如果仍沿用轴对齐的空间划分会有很多落入多个空间的物体,因此也有越来越多使用BVH方式作为加速结构的游戏。
比较空间划分和物体划分,可以想到两者的区别如下:
- 空间划分——划分的空间子集是不重叠的,但物体有可能落入多个子集
- 物体划分——划分的空间子集是可能重叠的,但物体仅属于一个子集
BVH相比早期的空间划分更多的是一种权衡而不是替代,它的提出晚于空间划分,虽不复杂但是也很有效。实时光线追踪的运算中也仍在使用BVH。
4 Clustered Forward Rendering
终于来到本文的“硬菜”,让我们还是回到Doom——《Siggraph2016 - The Devil is in the Details: idTech 666》结合《DOOM (2016) - Graphics Study》。原文其实很多段落展示了渲染的方方面面,我会以翻译原文再加上个人评述的方式来展示其中Clustered Forward Rendering的部分。

为光照和着色准备数据结构
- 起源自(后面的两个论文,名字不翻译了)
- 一些提升与优势:透明表面不需要额外的pass或处理了、独立的深度缓冲、避免了深度不连续性上的误差(false positives 假阳性,表示一种错判)、更多Just Works见下一页
*这里Just Works TM应该就是梗的陶德的那句有名的“It just works”,似乎这已经称为游戏行业分享中的一个名梗了,大概意思就是说一些莫名好使的东西。

准备集群数据结构
1)视锥体素化、光栅化处理流程——在CPU上每一个Job执行一个深度切片
2)对数的深度分布——扩展了的远平面与近平面(公式就不翻了,可以看到切片不是轴向均匀的)
3)以体块的方式来准备物体(Voxelize是一个生造词,这里不完全是体素化)
- 一个物体可能是:光源、环境探针或一个贴花(decal及其原理没提到过,有机会再说)
- 物体的形状可能是:物体空间的包围盒或一个锥体
- 光栅化的边界是屏幕空间的最小xy、最大xy以及深度的边界

准备集群数据结构
图中包含了300个光源,1200个贴花。
下面再引一些《DOOM (2016) - Graphics Study》的段落作为补充解析(不完全是翻译):
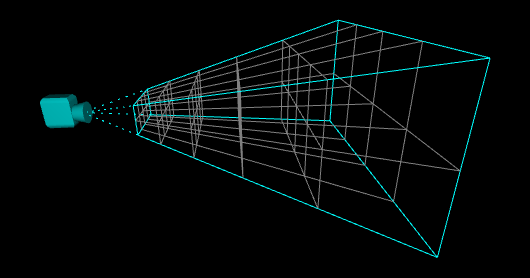
基于视锥体的划分方式
The depth test function is set to EQUAL to avoid any useless overdraw computation, thanks to the previous depth pre-pass we know exactly which depth value each pixel is supposed to have.
*之前的步骤已经进行了深度预运算,后续的分块运算都可以基于这个深度缓冲。
In DOOM the camera frustum is divided into 3072 clusters (a 16 x 8 x 24 subdivision), the depth slices being positioned in a logarithmic way along the Z axis.
*划分的集群数量是3072个,深度上的划分是延Z轴以对数的方式进行。
Each cluster can hold up to 256 lights, 256 decals and 256 cubemaps.
*每一个Cluster的上限,灯光、贴花和CubeMap都是256个。(划分这些的方式就大量用到了BVH)
the code loops over all the decals / lights of the cluster, calculating and adding their contribution.
*代码循环一个集群中的光照和贴花,计算并汇总它们对总光照的影响。
Clustered-forward rendering is getting some attention recently: it has the nice property of handling more lights than basic forward while being faster than deferred which has to write to / read from several G-Buffers.
Clustered-forward rendering近年来得到了更多的关注。它比起传统的前向渲染可以处理更多光源,同时又不需要像延迟渲染那样需要频繁访问G Buffers,对带宽的压力更小。
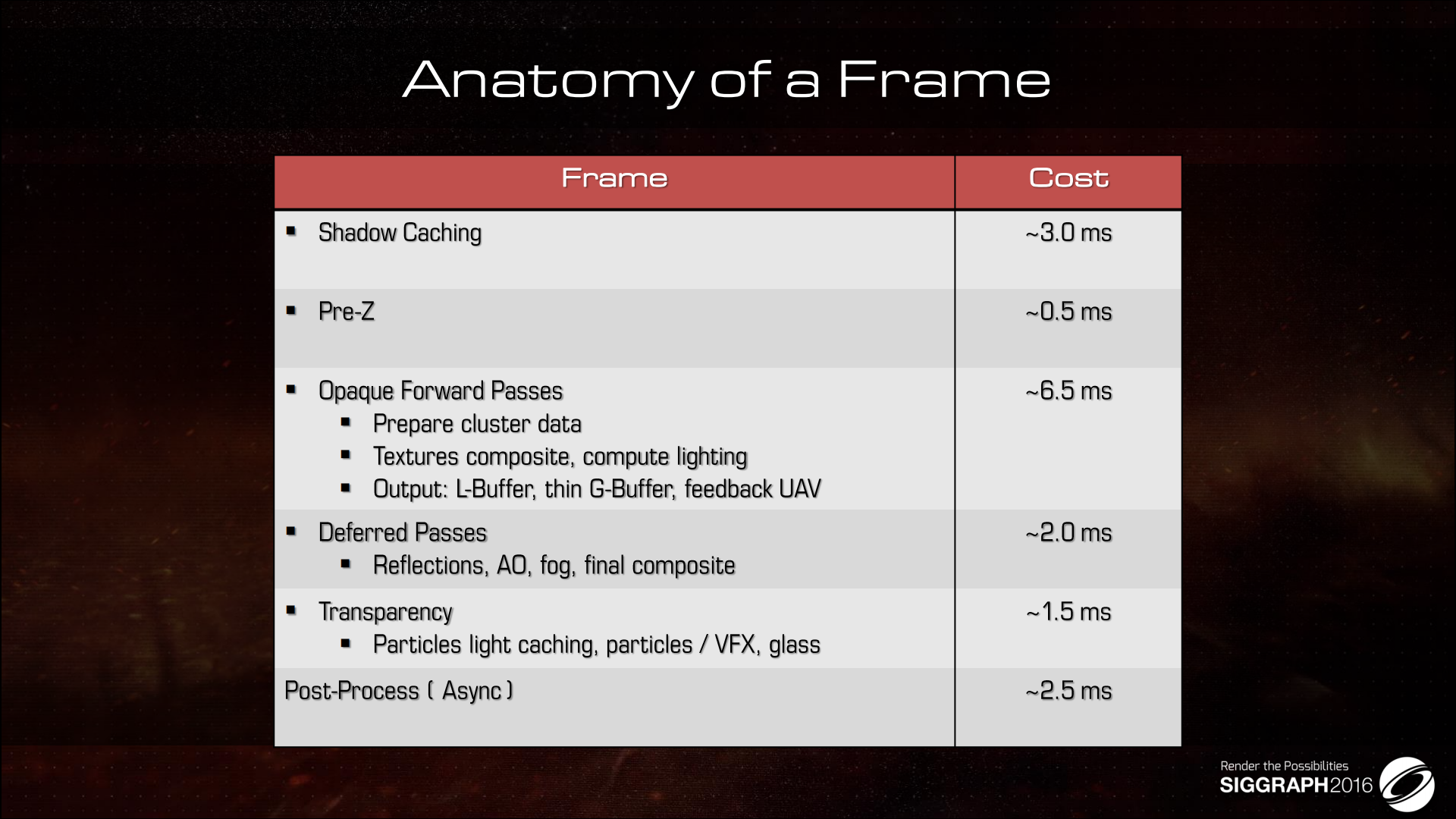
*最后是一帧整体的性能开销分布。介于篇幅原因没有再介绍与Cluster方案结合的缓冲区设计,有兴趣可以去看资料。
结语
虽然这里的新Doom不再是那个引擎技术的引领者了,不过他们在当时的idTech引擎中加入了Cluster Rendering来让画面有了很精细的表现,这在当时的一众3A游戏中仍然是很超前的。给我的感觉是即使id software被收购了,但在引擎技术和画面质量与性能的平衡上他们还是领先的;能看出画面质量确实大幅领先了其父公司的Bethesta的另一个引擎做出的游戏。(后来他们的《DOOM Enternal》也发了SIG分享)
这里还有一个题外话,就是我发现Clustered Rendering在某些场合被定义为“不同渲染机器一起协同联网渲染”的一种技术情况,我个人不确定这个技术当前的实用度和商业前景如何,但它确实混淆了这里Clustered Rendering的提法。我个人还是更愿意把Clustered Rendering接受为一个图形学意义上的,基于实时空间划分,组合了延迟渲染和前向渲染的技术。
如果对于详细计算有了解需求,可以去看看Games101系列课的光追部分,里面包含了BSP和BVH,以及分别怎么生成和求交点。本文主要是以我个人的理解来串了一下,主要还是想说说DOOM相关的技术,细节很多资料中都介绍了。
*下周五一期间会鸽一周,后面继续更别的话题。
下面是一些资料的链接:
BSP的Wiki
PVS的Wiki
BVH的Wiki
Siggraph2016 - The Devil is in the Details: idTech 666下载地址
DOOM (2016) - Graphics Study