CSDN文章鏈接;https://blog.csdn.net/hrh1234h/article/details/144024554?sharetype=blogdetail&sharerId=144024554&sharerefer=WAP&sharesource=2402_89228704
目錄
什麼是緩存,緩存有什麼作用
什麼是緩存穿透問題
布隆過濾器解決緩存穿透問題
什麼是布隆過濾器
布隆過濾器解決緩存穿透的思路
使用布隆過濾器(Redisson內集成了Bloom Filter)
引入依賴
配置Redisson客戶端
創建布隆過濾器,配置過濾器屬性
使用布隆過濾器
布隆過濾器原理深入解讀
布隆過濾器的數據結構
手搓布隆過濾器
布隆過濾器的優缺點總結
優點
缺點
——————————————
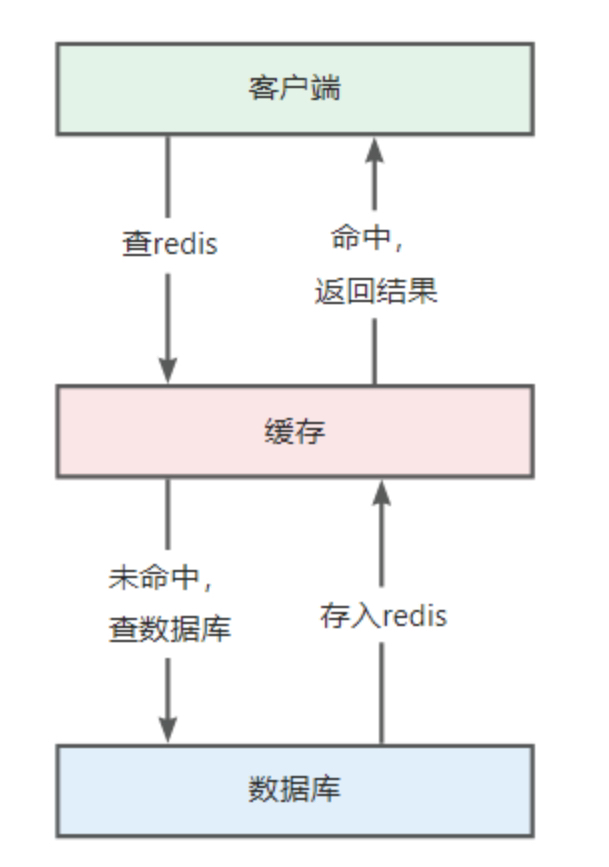
什麼是緩存,緩存有什麼作用
緩存通常用於存儲經常訪問的數據,以便快速檢索,減少對原始數據源的直接訪問需求。通過存儲頻繁訪問的數據,緩存可以減少對後端數據庫或服務的請求,從而減輕它們的負載。
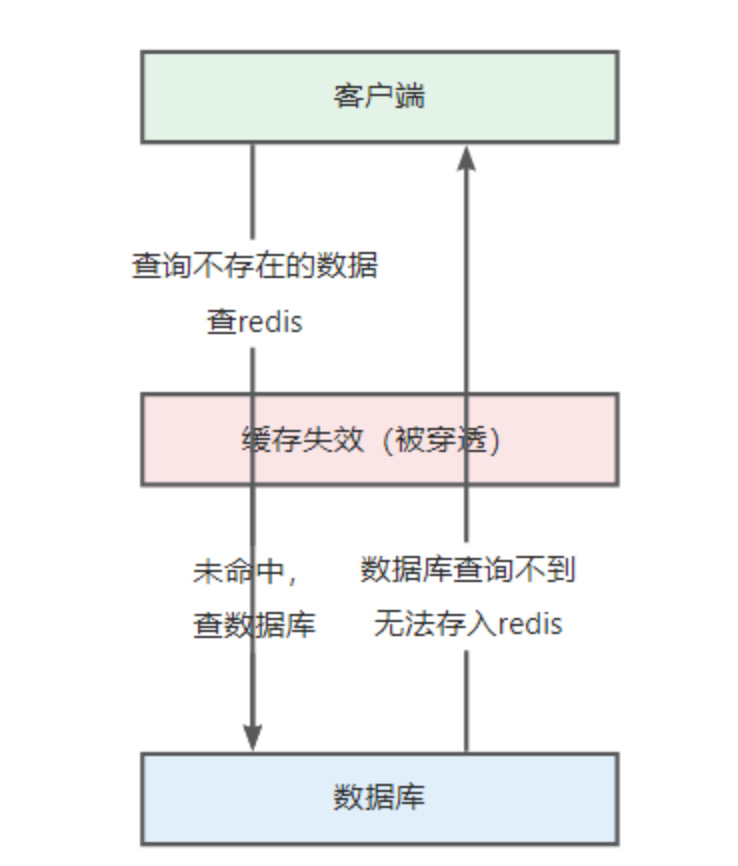
什麼是緩存穿透問題
如果查詢一個不存在的數據,數據庫查詢不到數據也不會直接寫入緩存,就會導致每次請求都查數據庫,相當於緩存失效,如果這種請求很多,尤其是惡意攻擊時,會對數據庫造成很大的壓力,甚至可能導致數據庫服務不可用。
布隆過濾器解決緩存穿透問題
什麼是布隆過濾器
布隆過濾器(Bloom Filter)是1970年由布隆提出的。它實際上是一個很長的二進制向量和一系列隨機映射函數。布隆過濾器可以用於檢索一個元素是否在一個集合中。它的優點是空間效率和查詢時間都比一般的算法要好的多,缺點是有一定的誤識別率和刪除困難。
布隆過濾器解決緩存穿透的思路
在系統啟動或定期更新時,將數據庫中已經存在的所有鍵,這樣,布隆過濾器就包含了所有合法的鍵。請求到達緩存前先在布隆過濾器預檢查,如果布隆過濾器判斷該鍵可能不存在,則直接返回請求不存在的結果,不再進行後續的緩存和數據庫查詢。如果布隆過濾器判斷該鍵可能存在,則繼續進行後續操作。
使用布隆過濾器(Redisson內集成了Bloom Filter)
引入依賴
Redisson內集成了布隆過濾器,我們可以直接使用Redisson。

配置Redisson客戶端
配置Redisson客戶端,連接到Redis服務器。
創建布隆過濾器,配置過濾器屬性
使用Redisson創建一個布隆過濾器,並初始化其容量和誤判率。
使用布隆過濾器
在查詢緩存之前,先使用布隆過濾器檢查數據是否存在。如果布隆過濾器返回不存在,則直接返回默認值或錯誤信息,避免查詢數據庫。
布隆過濾器原理深入解讀
布隆過濾器的數據結構
布隆過濾器(Bloom Filter)的數據結構主要由一個固定長度的位數組(Bit Array)和一組哈希函數(Hash Functions)組成。
存儲數據:要存儲的數據,通過多個hash函數獲取hash值,根據hash計算數組對應位置改為1 。
查詢數據:使用相同hash函數獲取hash值,判斷對應位置是否都為1。
手搓布隆過濾器
直接上代碼。
System.out.println("apple: " + bloomFilter.mightContain("apple")); // 應該輸出 true
System.out.println("banana: " + bloomFilter.mightContain("banana")); // 應該輸出 true
System.out.println("orange: " + bloomFilter.mightContain("orange")); // 應該輸出 false
--------------------------
布隆過濾器的優缺點總結
優點
空間效率:布隆過濾器使用位數組存儲數據,因此非常節省空間,特別是對於大規模數據集。
時間效率:布隆過濾器的添加和查詢操作時間複雜度接近O(1),即常數時間複雜度,非常快速。
簡單性:布隆過濾器的實現相對簡單,易於理解和實現。
無誤漏:布隆過濾器不會錯誤地報告元素不存在(誤漏),即如果一個元素被添加到了布隆過濾器中,那麼查詢時一定能被檢測到。
缺點
誤判:布隆過濾器允許誤判(false positives),即可能會錯誤地報告一個元素存在。
不支持刪除:標準的布隆過濾器不支持刪除操作,因為刪除一個元素可能會影響其他元素的測試結果。
固定大小:布隆過濾器一旦創建,其大小和哈希函數數量就固定了,這限制了其靈活性。
內存消耗:雖然布隆過濾器節省空間,但在處理非常大的數據集時,即使是優化過的布隆過濾器也可能消耗大量內存。