前言
上篇 中鋪墊了很多關於基底(Substrate
)材質系統,主要是關於“材料”這一部分的抽象提煉——每個部分被稱為一個slab,而相互的組織方式是通過運算符。
有了單個Substrate,下一步就是考慮其上的一些組織方式、數據傳輸及計算——讓我們從Substrate Tree開始。
本文還是以翻譯原文PPT頁及解說稿為主,打星號的部分則是我個人的補充。由於篇幅原因拆成了上下兩篇,這是其中的下篇。
1 基底樹——Substrate Tree
首先讓我們假設你想渲染圖中的黃色粗糙金屬,它被有著藍色高光的清漆包裹。
在使用Substrate的情況下,我們會用slab B表達粗糙金屬,用覆蓋在其上的slab A表達清漆層,通過一個垂直層疊(vertical layering)運算來組合。
但我們不能直接分別計算兩個slab再對光照貢獻進行累加。這會得到錯誤的結果,因為我們需要先計算slab A在slab B上層產生的效果,例如材質透射或fresnel效果等。(*即光線並不是全部到達了slab B)
為了正確計算這種效果,我們使用一個樹狀結構來作為材質的拓撲表達——運算符作為節點(nodes),slab作為葉子(leaves)。
We are going to process/walk/evaluate this tree in order to be able to output closures. Closures represent a bag of parameters that can be sent to the renderer for lighting evaluation, accounting for all the different operators effects on the visual result.
我們將逐步處理、遍歷、計算這顆樹以便輸出結果的閉包(closures)。這裡的閉包代表了一組參數,用以傳遞給光照計算渲染的階段,基於所有不同的運算符需要的效果來計算最終的視覺結果。
在圖中的例子裡,我們可以看到Slab A在材質拓撲的頂層,因此光照可以直接計算;而slab B在層級的底部,因此我們需要考慮Slab A中通過的光線,以便能計算slab B的光照。
一旦經過求值計算(evaluated),一個Slab會輸出一個閉包。每個閉包能以任意順序或並行進行計算得出——每個閉包計算會輸出一個亮度顏色(luminance color),然後所有閉包結果進行組合運算就得到最後的圖像。
*這部分主要是說閉包是每個slab能自己算出的參數或屬性單元(基於材料特性可以算一些例如顏色、法線、分佈函數PDF等),閉包參數計算是順序無關的,只在對樹求值的階段需要關注順序。

讓我們再看一個更復雜的例子。
圖中我們有碳纖維(carbon fiber),水平混合了粗糙金屬。你可以看到兩個slab間的過渡區域——這就是兩種slab通過一個水平混合(horizontal mixing)運算符鏈接的原因。
在這之上,你可以看到一個通過垂直層疊運算連接的清漆層。

在這顆樹中我們需要計算大量的閉包,以便對slab之間的各種運算進行求值。例如:
- ToViewThroughput(可以翻譯成:視覺方向的吞吐量),它受水平混合權重、上層吞吐量或覆蓋率權重的影響。
- TopTransmittance(可以翻譯成:上層傳播係數,上篇講過它是一個0到1之間的值),它代表了一個給定的slab的傳播係數,我們可以在光照計算中使用它——通過一個簡單的公式將實際的光線方向進行重映射(remapping)就能實現。
- 我們也輸出粗糙度和厚度用於粗糙折射效果(後續展開細節)。
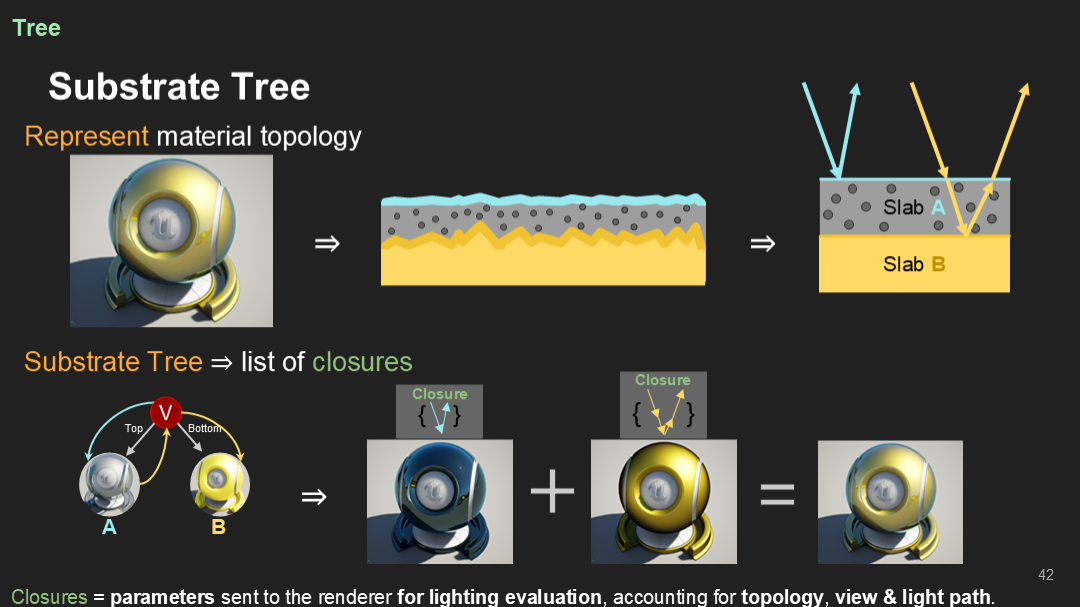
那麼我們如何處理和遍歷這顆樹?為了保持展示頁的相對簡單,我們僅展示一下如何通過閉包計算光的覆蓋率(Coverage)和傳播係數(Transmittance)。
首先,我們計算每個slab的覆蓋率和傳播係數。可以看到圖中底部的slab都是不透明的,因此它們的覆蓋率是1,傳播係數是0。
The colored coat slab has coverage of 1 and a transmittance mapping resulting from the mean free path as seen when viewing the material in isolation along the normal of the surface.
清漆層也有著1的覆蓋率,而其傳播係數的一組映射,是由沿著表面的不同法線方向單獨“觀察”這一層的mean free path(上篇中的一個概念)得出的。
*這裡作者沒有明確說這組參數的含義,個人猜想是最大、中位數、最小值。
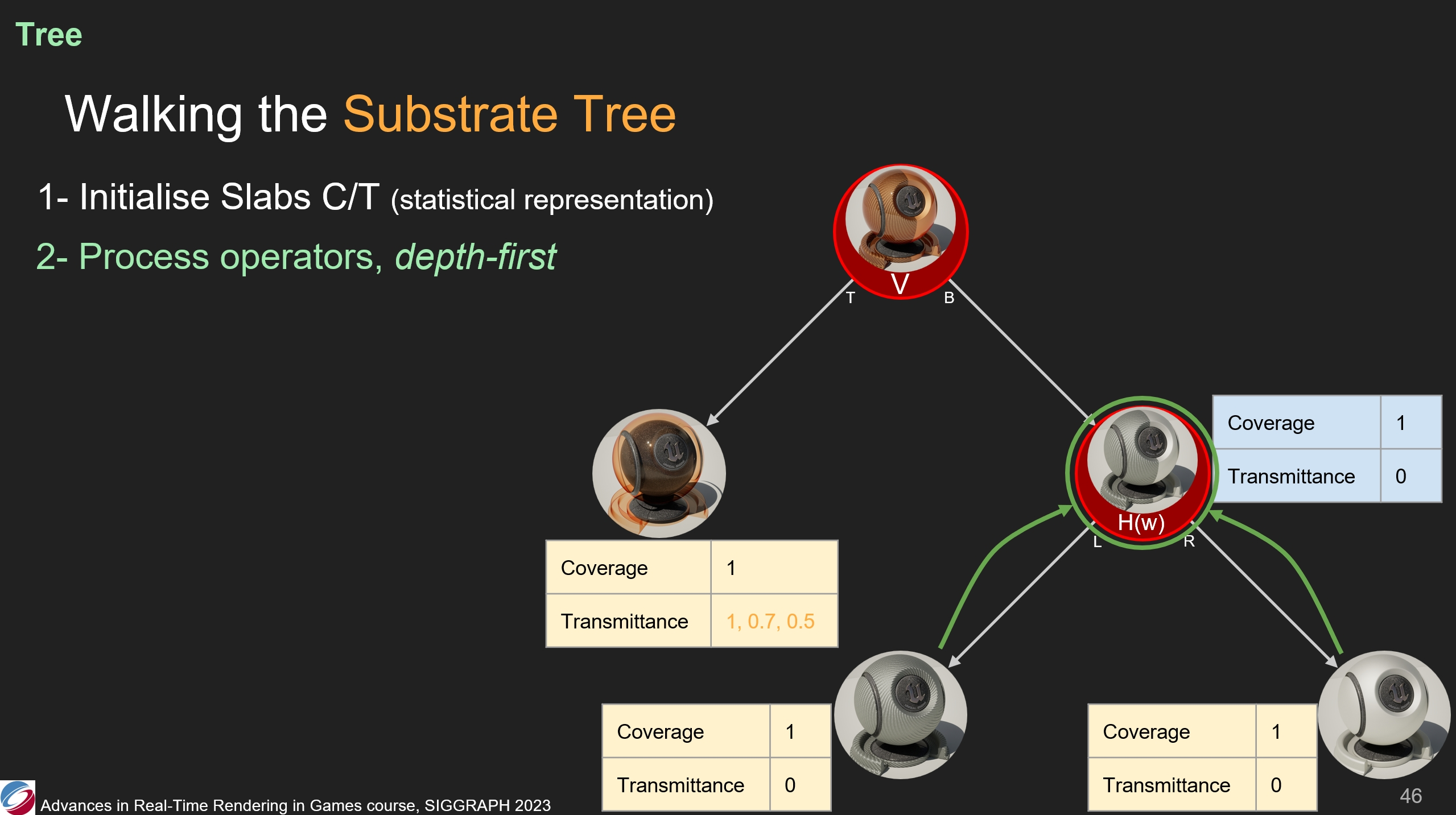
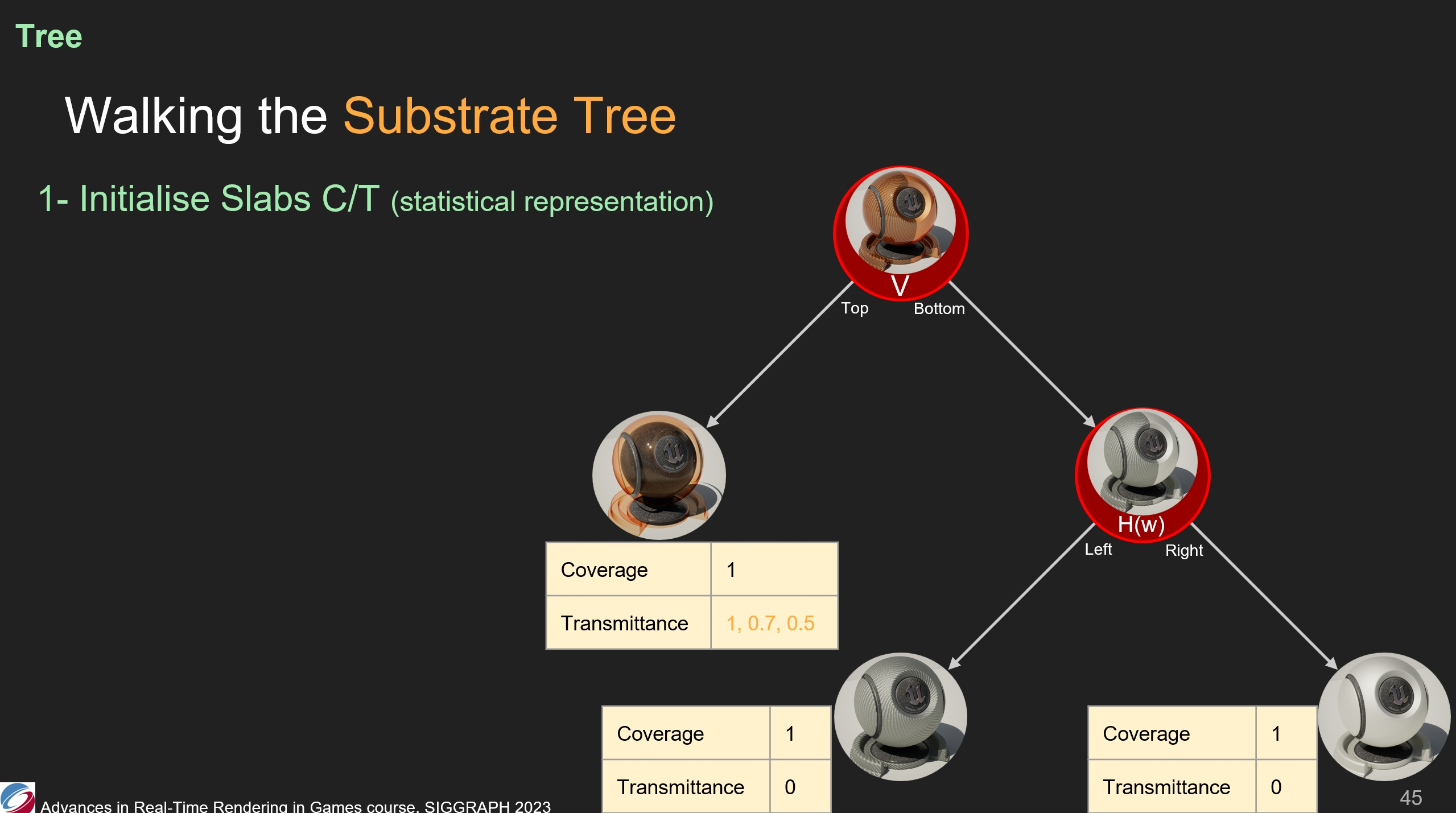
其次,我們將處理每個運算符——深度優先,以便從slab中彙集信息。
因此,水平運算符收集了(其葉子節點的)覆蓋率、傳播係數的值。在圖中的情況,兩個不透明的slab共同組成了一個不透明的表面。
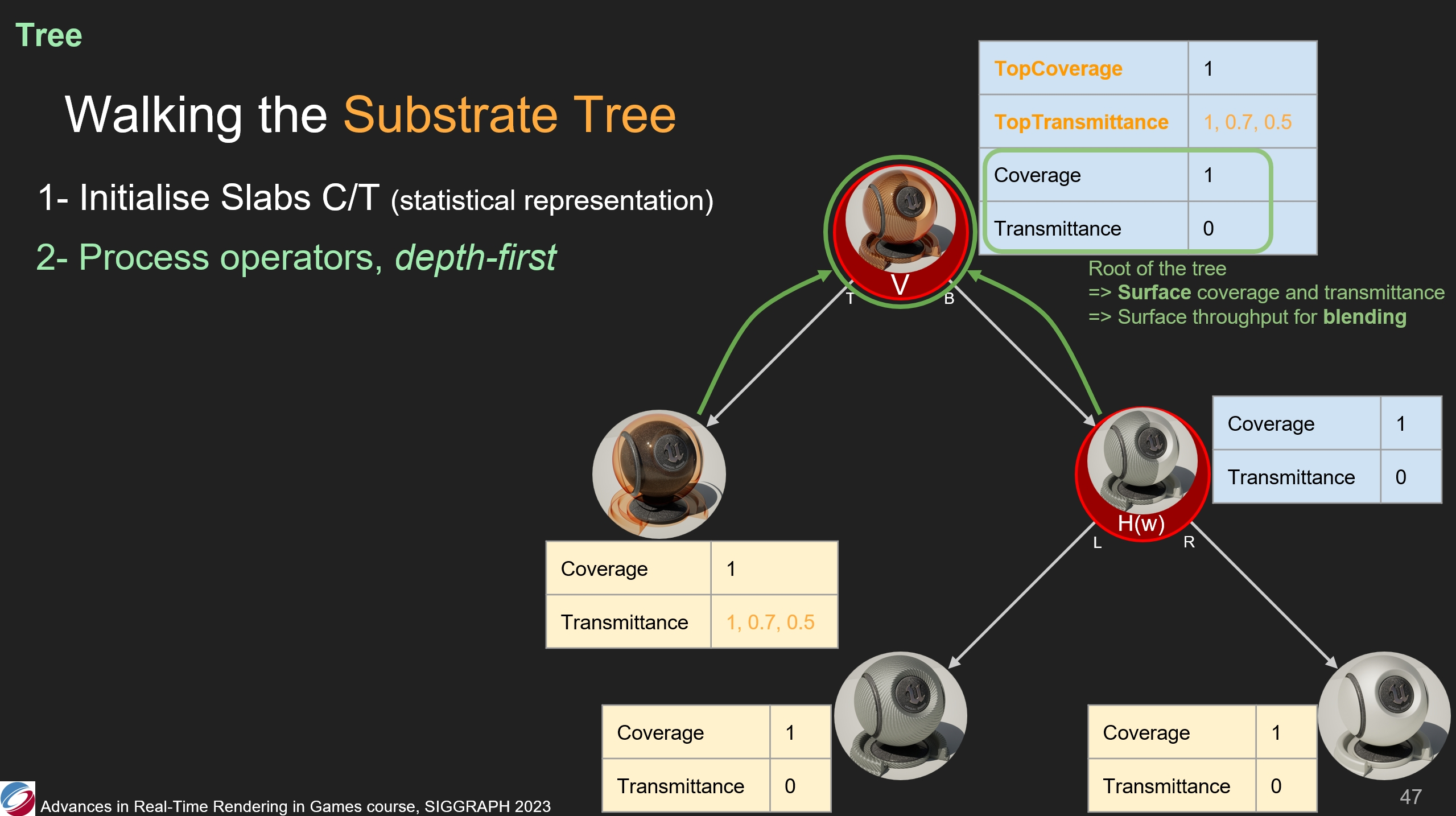
之後,處理根節點的垂直運算符——它也從葉子節點中彙集了覆蓋率、傳播係數。
在不透明表面覆蓋清漆層,整體得到的仍是不透明表面。(*最終傳播係數是0)
根節點的覆蓋率、傳播係數的值很重要:它代表了材質的整體覆蓋率和整體傳播係數,用以計算光吞吐量——如果用戶選擇了alpha blend混合和半透明渲染方式,則材質會按規則和場景顏色進行混合。(*即到了根節點才考慮計算和場景的半透明混合,之前都只計算閉包值)
另外,需要注意頂層的覆蓋率和傳播係數是被單獨存儲的,以便後續的一些計算用使用。
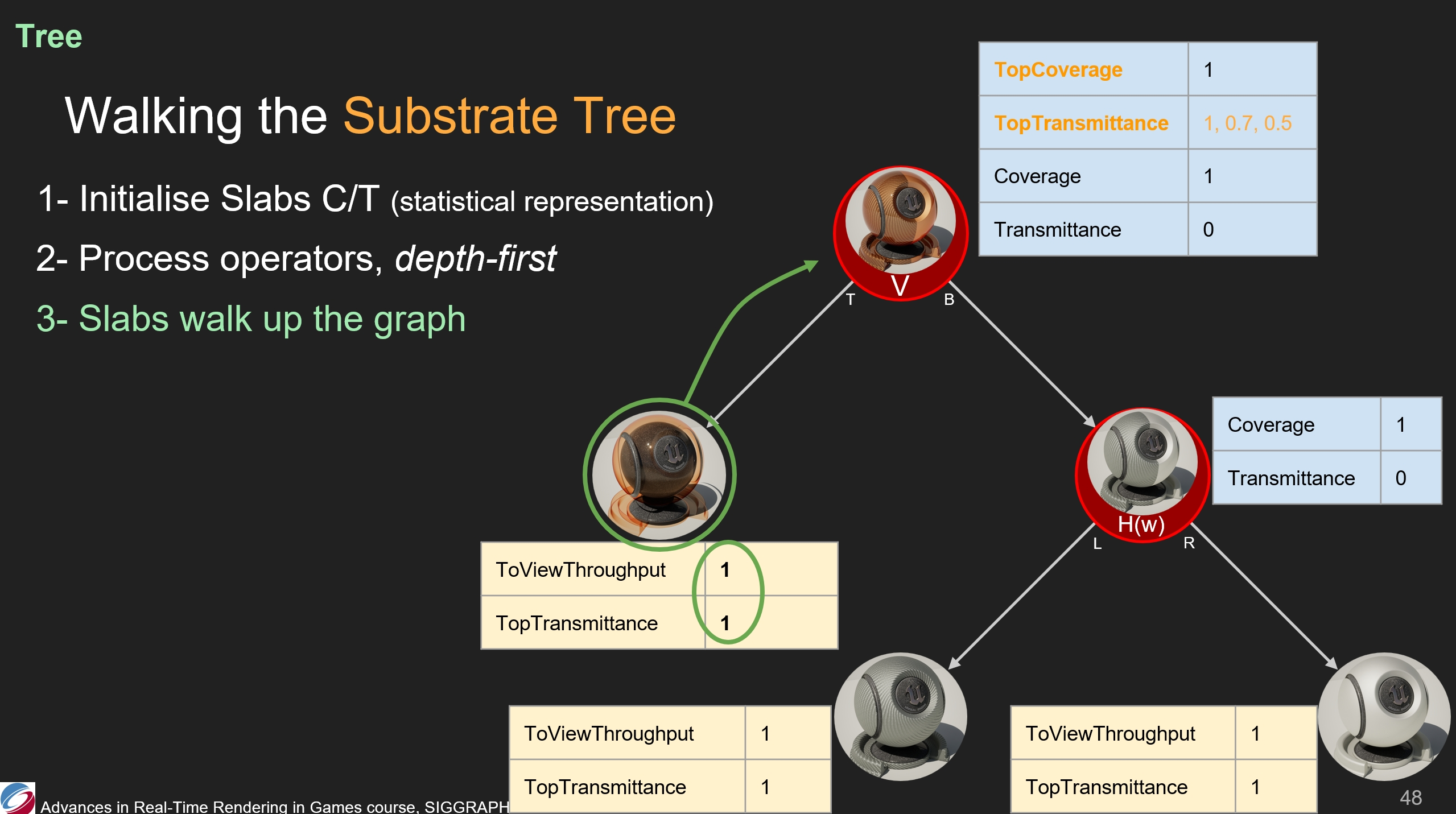
第三步,我們從每個slat開始向根節點遍歷,以便計算其它的一些值,例如之前提到的ToViewThrouput或是TopTransmittance。
我們可以看到,在清漆層向頂層執行垂直運算時,這兩個係數都是沒有變化的。(*個人覺得這兩個參數的取名有一定誤導性,最終還是要結合後面的步驟如何計算來看)
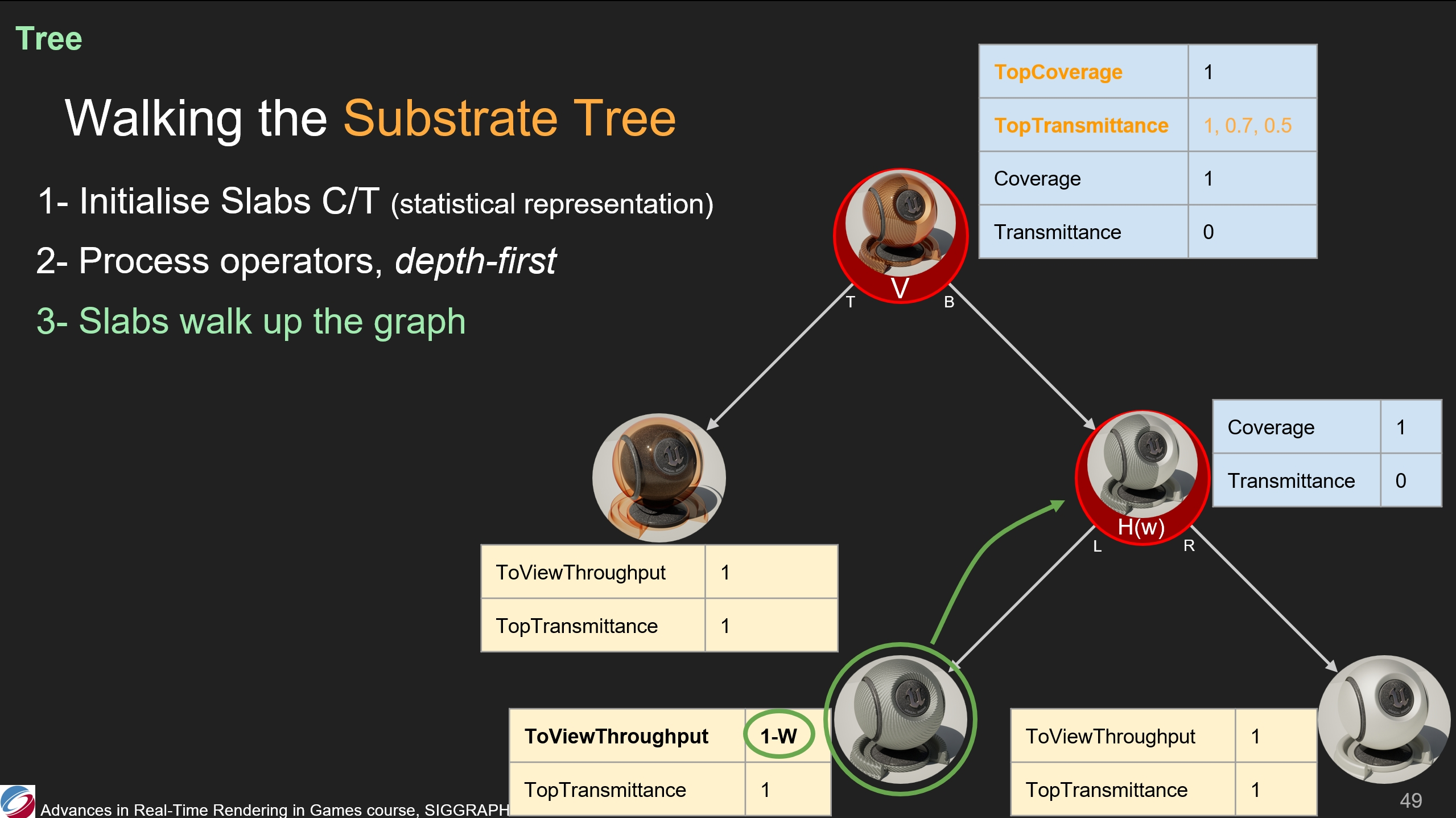
碳纖維slab首先遍歷到了水平混合運算。因而,它的ToViewThrouput會被混合權重影響。
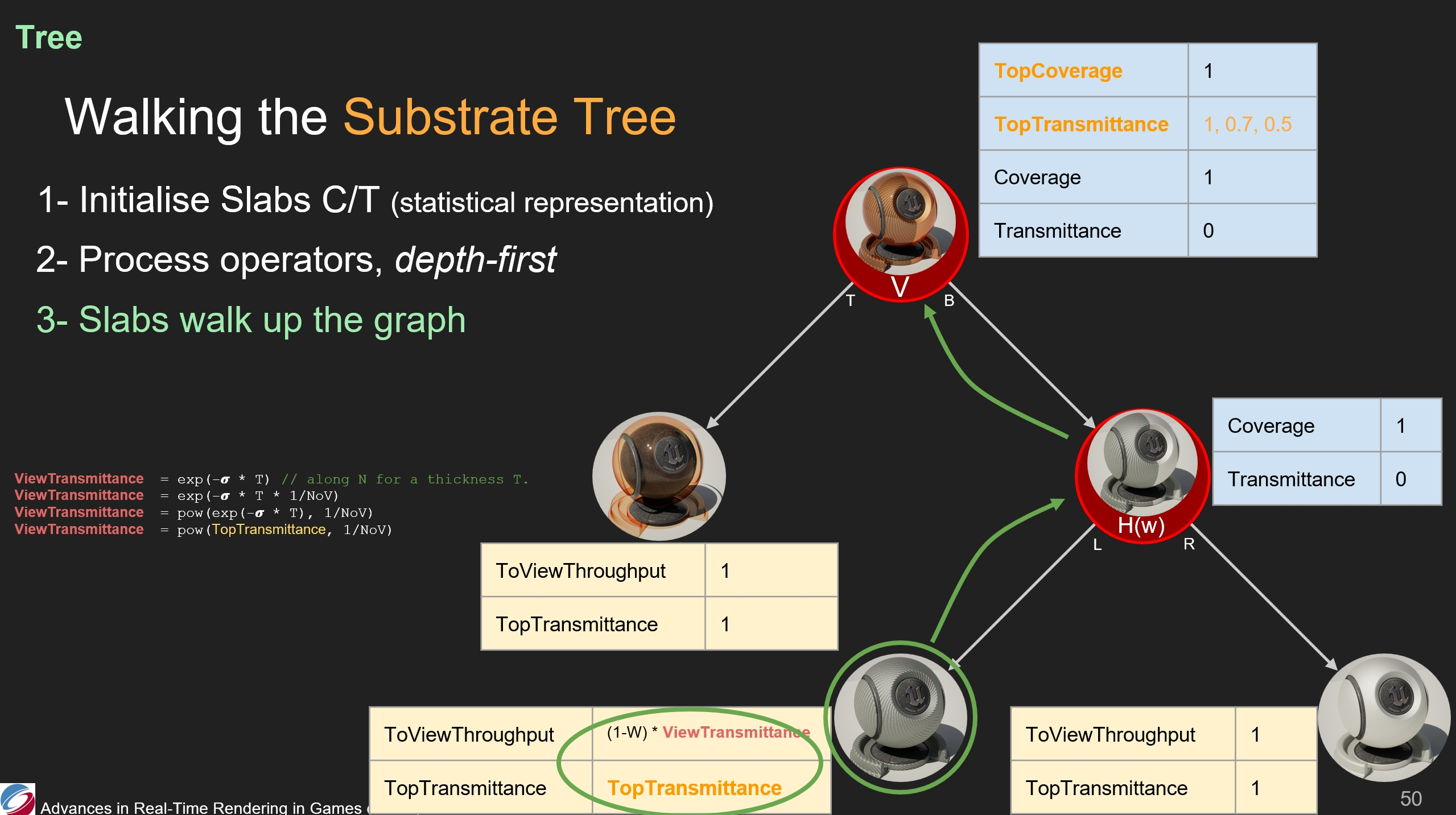
之後碳纖維層遍歷到了垂直運算節點,因此它的ToViewThrouput和TopTransmittance被節點中存儲的TopCoverage和TopTransmittance影響了。(*可以看圖中,都相乘了)
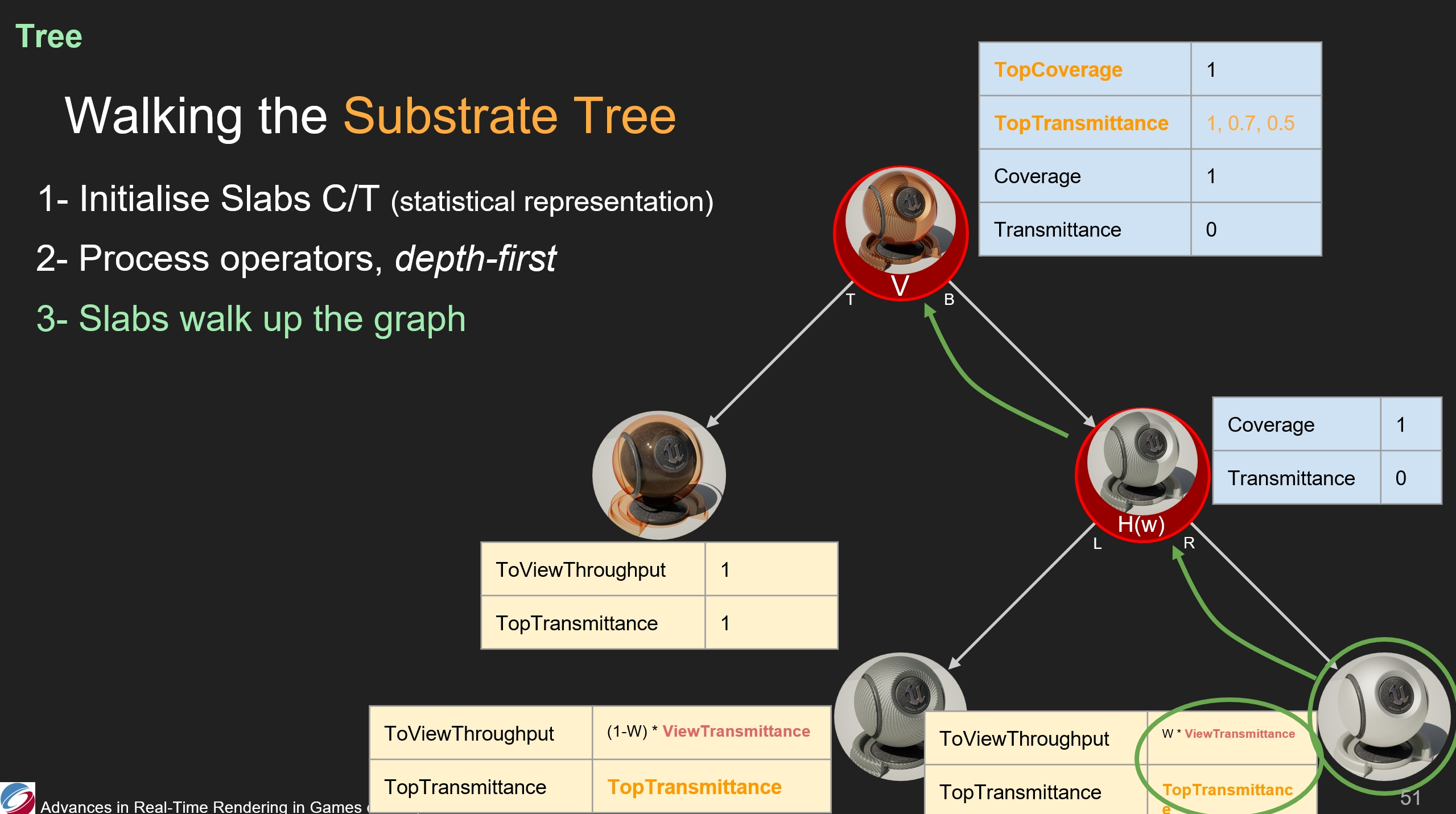
繼續對每個slab都執行類似的操作。

處理substrate樹時我們其實還計算了更多數據:
- Energy preservative(可以翻譯成:能量駐留),代表slab間的能量傳遞信息。
- 我們使用粗糙度追蹤(roughness tracking)來體現粗糙的頂層對其底層的高光效果的銳利程度的影響。(*即粗糙的頂層會使光散射,使本來清晰的高光變模糊)
- 我們也考慮了頂層的粗糙度對於光線折射的影響——因而粗糙表面下的底層也會顯得模糊(基於頂層的粗糙度和厚度)。其中使用的Point Spread Function是一個使用高斯模糊特殊計算的波瓣(lobe *之前多次介紹過,是光分佈的一種描述),其中硬編碼了空氣到水體的折射路徑——我們基於折射高光波瓣(refracted specular lobe)來計算底層表面的模糊程度。(*這部分的效果可以看圖)

Some more details: when we compile a material topology, we do it for the worst case topology. This is needed because we need to flatten the tree parsing code. Compilers could not handle dynamic tree processing using for loop unfortunately (weird behaviors and crashes at compilation time would happen).
再介紹一些細節:當編譯一個材質的拓撲數據時,我們的編譯器計算了最差的拓撲情況。這是因為我們需要將樹的解析代碼儘量展平(flatten),因為(不幸的是)編譯器無法處理動態樹操作中的循環(會導致發生奇怪的問題和崩潰)。
我們也收集了例如切線(tangent)等slab之間基準的共享參數,只在GBuffer中存儲一份數據拷貝。
你可以從圖中藍色部分看出,我們也追蹤了每個slab啟用的特性(features),以便得知最差情況的複雜度和每像素的GBuffer字節需求。這也可以通過項目設置中的最大每像素GBuffer字節(maximum GBuffer bytes per pixel)來進行簡化,後續會解釋到。
2 規模控制——Scalability
*這一節主要介紹通過工程設置來控制閉包規模,最終影響畫質的流程。Scalability在考慮規模變大時也會翻譯成可擴展性,但這裡更多是說控制規模。
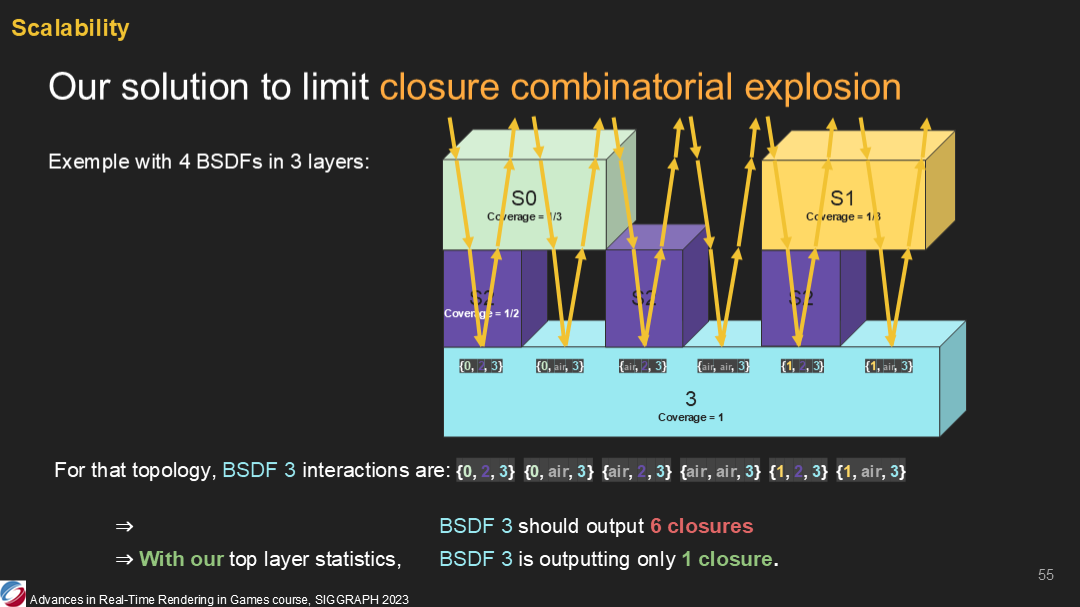
首先,我們需要克服閉包組合過多的問題(原文是closure combinatorial explosion)。
我們要演示的這個例子展示了標號3的slab與其上兩層不同覆蓋率的層有著複雜的拓撲結構(如圖)。如果想要以可信的方式表達出材質的拓撲結構,我們需要考慮不同的光路徑。(*圖中黃色箭頭)
例如,光可以通過S0,之後通過S2到達S3;或者它可以通過S0,然後直接到達S3。以此類推,能得到6種不同的路徑及(從S3觀測的)吞吐率和感官粗糙度。
這會直接導致需要計算6種不同的閉包(有著不同的ToViewThroughput、TopTransmittance和高光粗糙度)。這種計算過於昂貴。
為了簡化這種情況,我們得出了一種能夠在統計上表達slab組合(基於之間的運算)的方式。在本例種,slab3將被一個單獨的虛擬slab覆蓋,綜合了其它slab的參數。這樣就會僅得到一個閉包並計算。
*這裡用的trick感覺也近似掉了不少東西。

在我們的統計表達中,一個slab,或者說多個slab的合計,可以表達為以下參數:傳播係數、覆蓋率、粗糙度和折射波瓣。(transmittance, coverage, roughness and a refraction lobe)
It assumes there is no correlation between the coverage of the matter of each Slab.
這個方式假設不同slab的材料的覆蓋率之間沒有相關性。(*例如上層材料必須覆蓋在下層材料之上)
例如,slab的覆蓋率運算是怎樣的?它僅僅減少slab的覆蓋率,而不影響材料的其它幾項參數。
我們也為水平混合和垂直層疊運算提供了更復雜的方案,具體可以參照bonus頁。
*bonus頁中有5頁介紹了這部分內容,簡單來說覆蓋率主要通過基於權重的加和乘來計算,而傳播係數的計算還要考慮各自覆蓋率的影響。篇幅原因就不列出bonus頁了,有興趣可以去看看原文。

現在我們控制了閉包的數量,下一步就是基於不同平臺和畫質的設置。例如,我們可以動態適配:
- 著色質量
- 啟用的特性(enabled features,粗糙追蹤或粗糙折射等)
- 通過設置每像素的緩衝區字節上限,可以控制GBuffer中的數據精度,甚至能調整例如移動端前向渲染使用的數據精度。

所以對於圖中的包含水平混合和垂直層疊的例子,我們如何簡化閉包的輸出?
需要記住的是,一個slab是一個材料的基礎表達方式。因此在理解這一構成的基礎上我們可以構思合併不同slab的方式。
Thus our solution to the simplification problem: progressive tree simplification using parameter blend of slabs descriptions based on some empirical rules. If that is not enough, we can even simplify by disabling special features.
對於這一簡化問題,我們的方案如下:使用激進的樹簡化方案,採用一些經驗規則來做slab的參數混合。如果還不夠,我們也能直接關閉特定的feature。
需要著重注意的是,這對於通過MDL或MaterialX標準提出的一些BSDF是不可行的——例如特定的BSDF和DiffuseBSDF無法通過這個方式合併。

這裡是一個簡單的例子:
- Slab A包含了diffuse, F0, F90和normal這幾個參數(F0、F90上篇介紹過)
- Slab B包含了不同的diffuse,F0, F90和normal參數
- 一個相當直接的想法就是通過一定的插值方式來對參數做混合

這裡的默認材質包含了所有的lobe和3個閉包,存儲在72字節。

我們可以簡化這一材質,通過對最深的子樹做水平混合操作。此時,我們只需要2個slab,2個閉包存儲在48字節裡。

最終,我們可以通過混合垂直運算將它簡化成一個材質——這時就只有1個slab,一個閉包存儲在12字節裡。
3 存儲與計算——Storage & Evaluation
*Evaluation這個詞雖然翻譯成計算,但其實完整的信息應該包括計算求值,而且這裡特指的主要是光照計算求值。
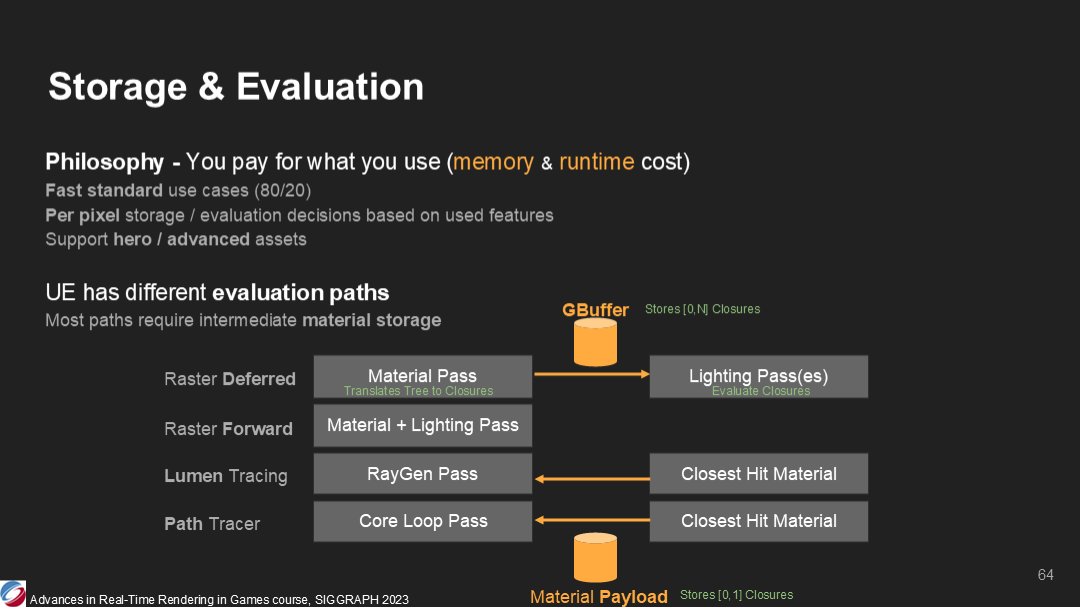
這裡的設計理念(原文用了philosophy一詞,直譯是哲學)是,你應該只為有效使用的數據付出內存和光照計算的開銷。
我們可以逐像素適配它的內存分配規模——基於對應渲染內容的複雜度。如果材質的大部分都比較簡單,則開銷就比較小。這種特性又能允許某些場合出現很複雜的材質。
如你所知,虛幻引擎有多種不同的光照路徑(管線):
- 延遲渲染,其中閉包數據存儲在gbuffer,之後在光照pass讀取
- 前向渲染,光照計算在基礎pass中進行
- Lumen光線追蹤,材質屬性存儲在一個光線追蹤的數據交換區(payload,直譯是荷載)
- 以及類似的,傳統光線追蹤
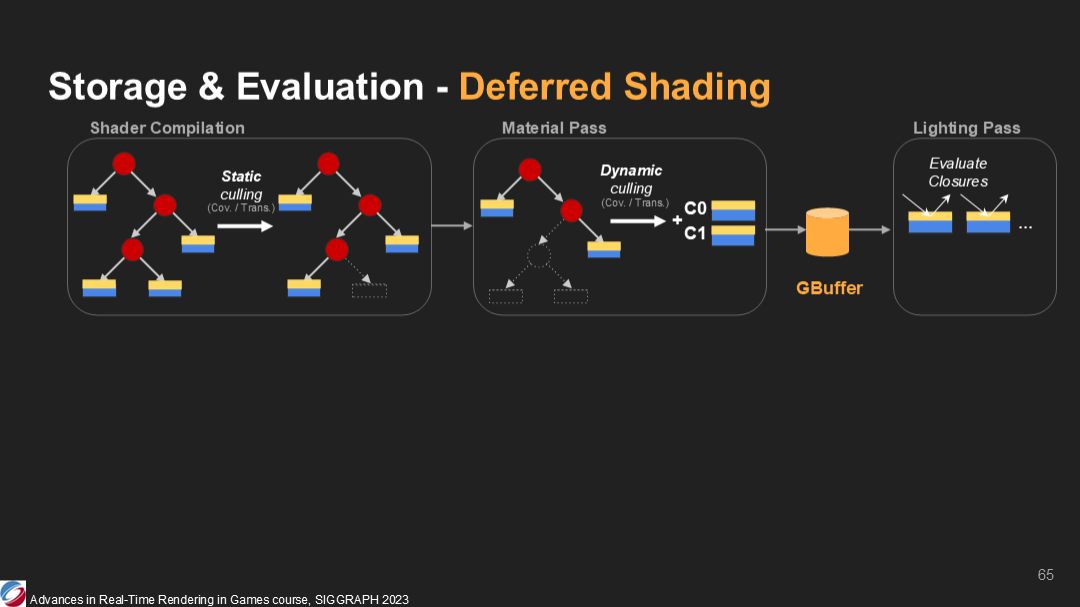
讓我們看看材質的生命週期中發生了什麼:
- 材質被編譯。編譯器確定出權重始終為0的slab,它們會被靜態編譯分析出並剔除,之後對生成的代碼進行平整。
- 當基礎pass的材質shader被執行時。閉包被計算並寫入gbuffer——如果一個閉包的權重是0,它將被跳過並從待寫入的列表移除。
- 之後,閉包就被準備好用於光照pass的計算。
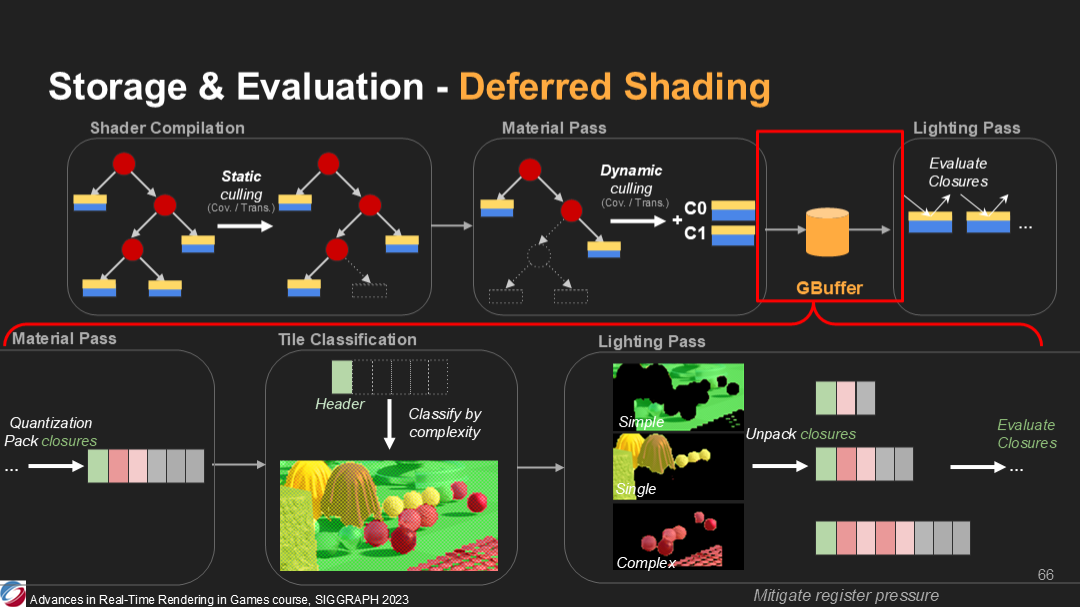
讓我們看看更多gbuffer使用上的細節:
- 材質閉包在gbuffer的存儲採用激進的壓縮策略,以儘量減少字節數。
- gbuffer中的第一位表達了每個像素的複雜度,然後屏幕被基於著色複雜度分成不同類型的tile塊(簡單slab,slab+features,多個slab等等)
- 我們的每個光照pass都是tile化的(支持並行),因而shader代碼可以被優化,以便在讀取和處理閉包時能高效進行。這些都可以減少數據註冊的壓力,提高數據容量並減少GPU的渲染開銷。
*材質複雜度在UE中直接就有一個調試工具,輸出在屏幕上就是圖中綠底的圖。

這裡簡單演示了一下閉包的動態剔除(前兩中頁介紹的內容)。
圖中可以看到2個slab水平混合。在tile分類的debug視圖(右側)中,你可以看到我們只為複雜的tile付出開銷——這部分材質每像素輸出兩個閉包;而混合權重為0的閉包則被計算pass直接移除掉了。

那麼我們是如何在GBuffer或材質buffer中逐像素存儲數據的呢?
- 數據頭(header)代表了材質的複雜度,例如分類、閉包數量、切線基(tangent bases)的數量等。
- 之後基於啟用的特性不同,我們有一組閉包列表——每個閉包對應不同特性,例如SSS或Fuzz。
- 在之後我們有切線基的列表(所有閉包計算共用的)。
- 最後但是同樣重要的是,我們存儲了其它數據例如TopLayer數據(法線、粗糙度等)和SSS數據以便傳遞給我們的後處理部分——例如SSR、SSAO、DFAO或SSS,以避免屆時需要讀取全部材質數據。
基於不同的複雜度情況我們有著不同的數據打包(壓縮)方式。
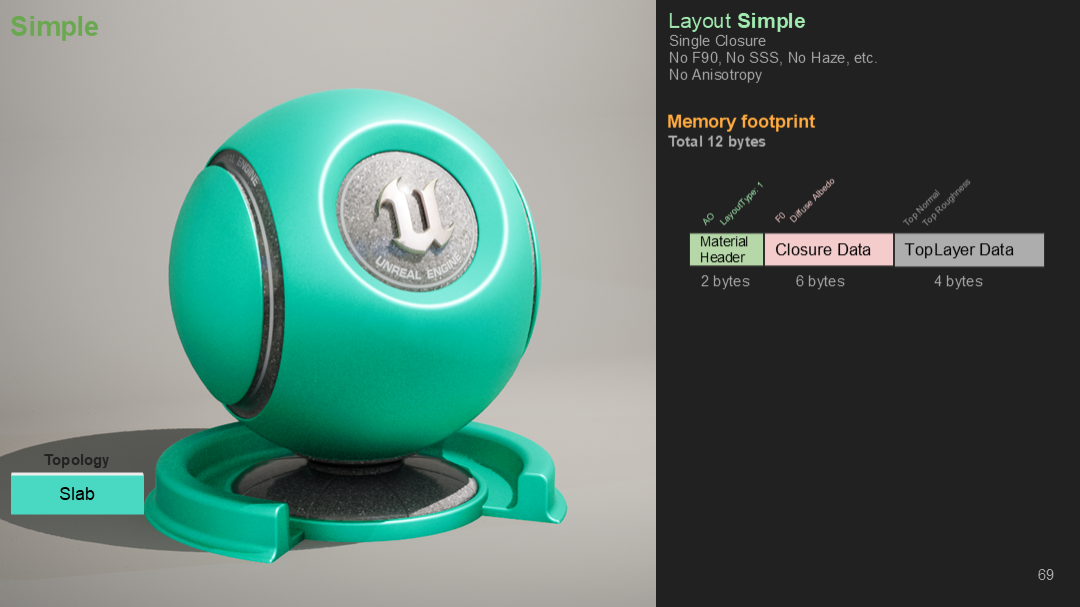
例如,對於圖中的簡單材質——僅依賴diffuse、specular和roughness,只需要12字節數據。
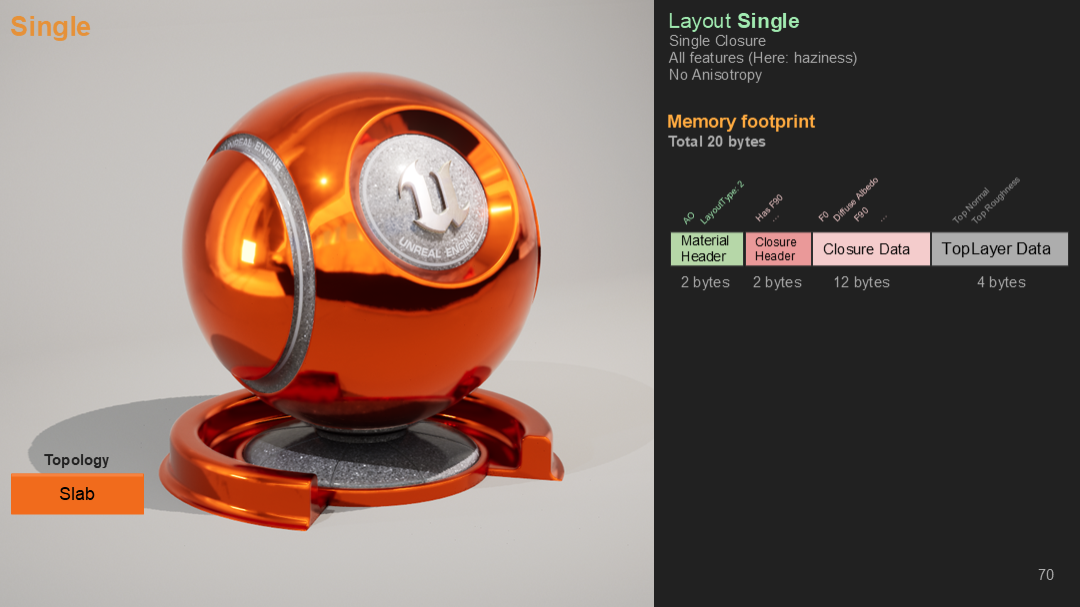
這裡是一個單獨材質——一個slab包含一些feature。在這個例子中,用到了朦朧(haziness)特性,字節數上升到20字節每像素。

這裡是一個複雜材質,包含很多slab。
你或許認出了我們上一個GDC的DEMO中展示的蛋白石(Opal )材質。它由2個用到了raymarch的高度場的slab組成,以及一層高光的透明覆蓋層。
這裡使用了閉包的通用表達格式,每像素需要76個字節。

這裡是一個特殊的材質,包含了例如Glint和SpecularLUT等進階的視覺要素,它能夠用來精確表現有著閃爍的車漆或進階的珍珠形式的外觀。(*圖中表明瞭,閉包部分92個字節,總共100)

對於每個閉包,它們的參數被激進地使用離散化(quantization)的方式壓縮。並且我們使用了dithering以避免出現帶狀偽影(banding artefact)。所有這些閉包數據最終都以UINT流的形式寫入我們的GBuffer。
我們的GBuffer是一個UINT作為數據格式的2D紋理數組——被我們稱為材質buffer。
在基礎pass中,最初的3個層被映射為Render Target輸出,以便在部分硬件上利用其混合輸出的緩衝區機制。剩餘的層被映射為一個單獨的UAV,超出之前Render Target輸出範圍所有的UINT數據被寫入其中。(*UAV是一個著色的中間概念,是Unordered Access view的縮寫)
在低端平臺上,我們的目標是避免昂貴的UAV寫入,因此所有舊材質都有3UINT的數據上限。
而關於buffer的的分配策略:我們允許它增長,基於屏幕上渲染哪種材質;但我們從不收縮它的容量,以避免內存重分配導致的內存碎片和顯示故障。

一旦閉包被壓縮存儲到GBuffer中,後續就可以讀取並用於計算光照了。
我們簡單地循環所有閉包,並加載它們,之後基於啟用的feature來計算光照。
如前所述,tile複雜度的分類能幫助我們優化這些pass中的GPU開銷。

對於硬件光線追蹤,我們需要把材質數據發送給射線生成Shader(RGS——Ray Generation Shader)。這一步在光線追蹤的payload結構中完成,並且這一結構需要保持儘量小且高效——我們將其限制在了64字節。
然而,我們不能傳入整個材質的substrate tree的數據到RGS中,因為這無法匹配多個slab的表達形式——類似的,多閉包也在很多情況下無法適配。
對於Lumen,所有的lobe和反射細節相對沒有那麼重要——對於全局光照來說。我們對一個substrate tree執行了一個全面的簡化——簡化成一個單獨的slab,只輸出一個閉包。這樣它就能符合payload的需求,並在lumen的RGS中計算了。
而對於傳統的光線追蹤,我們需要關注所有的反射細節和光的互相影響。我們簡單地隨機選擇一個閉包,並基於直接光照的albedo在hit shader中進行處理。這個閉包的PDF會基於所有閉包的直接光照的albedo進行重新分配權重,之後光線追蹤器就可以對這個閉包的lobe進行選擇和採樣了。
這是一個選擇,犧牲了豐富的變化來換取更好的性能。通過些微更多的採樣數,結合我們的降噪器,就能得出圖中展示的例子。
*光追這一步看著雖然差不多,但實際上已經不是多個slab組合這麼回事了。所以之前那麼多slab特性主要還是針對直接光照的,在簡介光照上精度其實損失了很多。
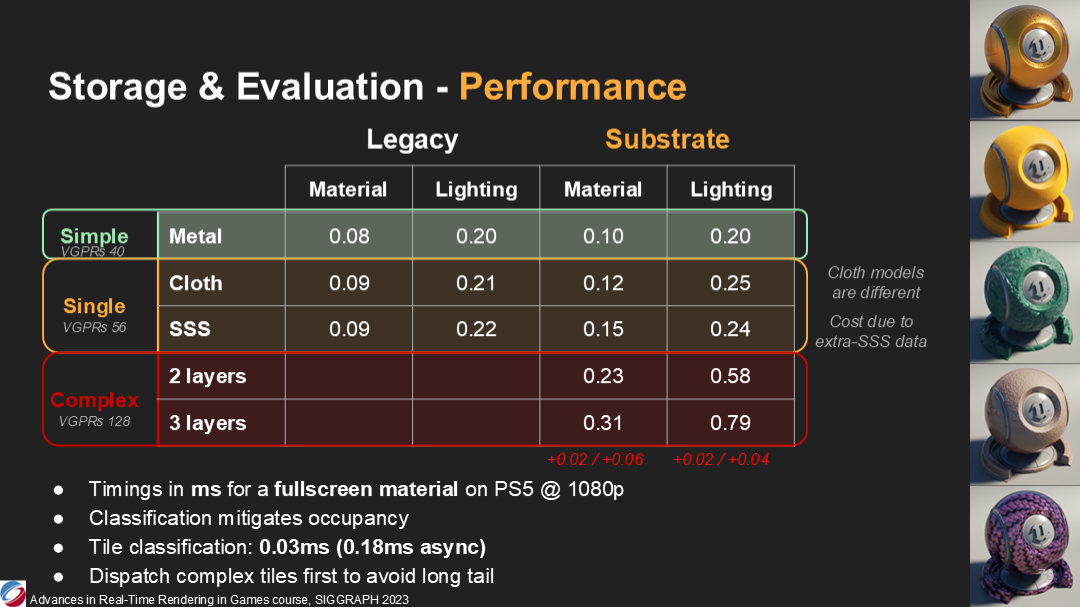
*這裡給出了不同複雜度材質在PS5 1080P時的耗時,提供了傳統材質和Substrate材質的對比。

*最後是一些內存佔用對比。

*不同材質複雜度的數據字節佔用。
4 總結
*總結的部分不長,好處就不重複了,上篇中都提到過。這裡主要看看目前的侷限。

首先,我們需要一個深度prepass(即預先繪製深度,而不是深度+著色的方式進行)。這是由於某些材質和閉包可能需要在UAV中寫入數據。
其次,我們需要一個單獨的貼花加速pass(decal accumulation pass),通常被稱為DBuffer。這是因為我們新設計的GBuffer不再能混合了,一些貼花需要在閉包生成之後的pass再被合成進去。
也有一些shader編譯方面的挑戰: 在base pass可能遇到更多編譯和數據打包的情況,因此shader會變得更大並且需要編譯更久。雖然凡事都是有代價的(Nothing comes for free 更好的效果就要付出更多時間成本),但我們會持續改進這一點。
我們也希望減輕額外buffers寫入相關的額外開銷——主要是與後處理pass通信的TopLayer和SSS數據緩衝的部分。
最後但是同樣重要的是,我們也希望基於更多的用戶體驗來進行調整改進。因為slab參數化方式自身相比原有的材質參數化方式有著一定的學習曲線,最終可能我們會提供一定的方式來提供簡化的參數化方式,例如映射成類似傳統shading model的形式。
*作者似乎很喜歡用Last but not least這個詞組。總的來說,新系統的開銷會略高於目前的材質系統,並有著更長的著色器編譯時間,目前方案的可接受程度踩在工業化能接受的臨界線上。
結語
原文中還針對其中2項問題及工具化的細節有10頁左右的的Bonus,這裡就不展開了,有興趣可以去詳細看看具體技術細節。
目前作為一個可選插件來說,Substrate材質在虛幻5中還是被標記為“實驗性”階段,距離實際可穩定用於產品還有一定距離。
不過回看之前的一些實驗階段的成功案例,至少在虛幻的路線圖中成功在工業化領域落地的比例比較多。除了一整套基於實景掃描及網格自動處理的高清資源管線外,典型的還比如逐漸廣泛用於動作遊戲的Motion Matching(動作自動匹配混合)系統。在《黑神話:悟空》的研發中期就曾經在一次分享會上提到這個技術,介紹了當時的一些侷限及應用細節——距離當時2年之後,現在隨便一個開發者都可以對著UE的範例工程配置出相當豐富的實時混合動作了,而且這項技術最終也在黑猴遊戲中得到了不錯的產品級驗證。
正如在Motion Matching之前踩在硬件CPU性能的平均線上一樣,Substrate材質系統目前也基本踩在GPU性能的平均線以上,但是我估計很快就會有以Substrate材質作為視覺特點的產品出現了,畢竟這能夠大幅縮短圖形和材質Feature的開發時間。
如果說之前只是看渲染相關的方面,近期我確實逐步瞭解了虛幻5這個引擎的方方面面。以我目前的瞭解來看,之後的3D遊戲不管是任何開發規模,至少在畫面精細程度和動作流暢度上都會有著相當高的起點——高質量只是一個方面,最重要的是工具鏈非常的高效。
最後是資料鏈接:
Authoring Materials That Matters - Substrate in Unreal Engine 5 的PPTX
作者提供的參考資料譜系