前言
这次读的是2023年SIG中,来自High Moon Studios的CTO——Stephan Etienne
的一篇分享。(这个工作室是动视旗下的一间工作室)
虽然我没玩过《使命的召唤》系列,但是在我的印象里这个系列无论好玩与否,基本是画面和运行性能都很顶格的游戏。而大地形系统,作为一个战场中“打底”的模块,要做到近处精细,远处自动LOD,同时兼顾剔除与分块;所以虽然其实每个3D引擎几乎都有自己的地形系统,但细看下来又有一些细节上的取舍和不同。
本文还是以翻译原文PPT页及解说稿为主,打星号的部分则是我个人的补充。虽然页数不算多,但是由于每页文字量比较大,篇幅原因还是会拆成上下两篇。
正文
*这次的正文比较整体,或者说分节比较碎,基本一两篇就是一个小课题。当然,内容量还是比较足的。而且这篇分享配图相对比较清晰,讨论的课题从图上把握的话其实比较明白了。

大地形如何工作
超大地形是一组地形表面的集合。
在这个截图中,每个紫色的矩形是一个地形表面。每个红色的区块是一个兴趣点,有着各自单独的地形表面。
有这么多地形表面的其中一个原因是——我们在同一个地图上有很多并行的开发制作;另一个原因是我们想有丰富的细节。
地形表面有着一些限制——它们不能被缩放或旋转;它们也需要是方形(拼合)的,这能使代码变得简单高效。
地形中标红的部分呈现出并非方形,并且经过了旋转的状态,这是通过cut out体积来实现的——后续会介绍到。
几何体
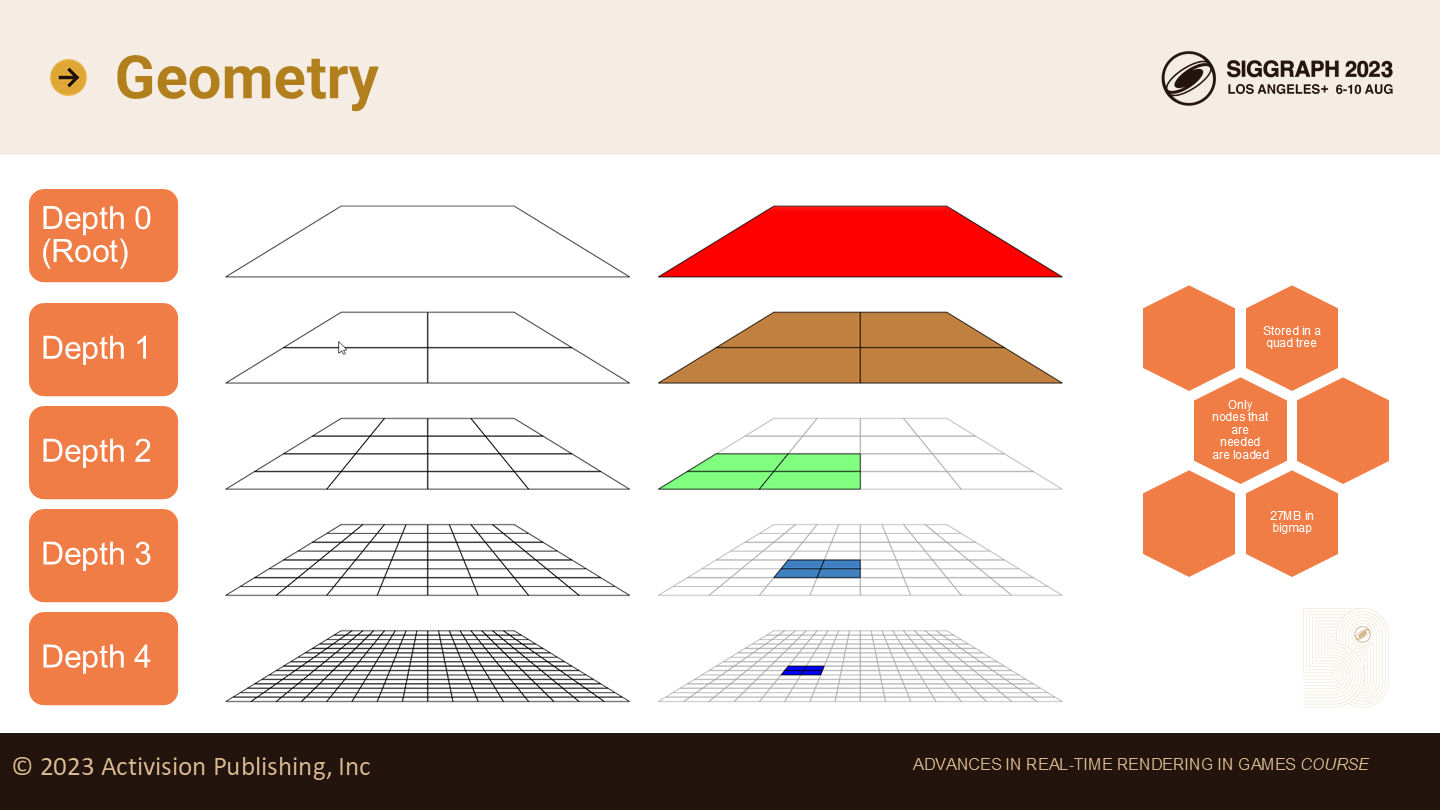
地形技术对于四叉树有着深度的使用。
每个地形表面有一颗四叉树,在每个节点上,我们存储了渲染必须的顶点和索引缓冲;不需要被选择的节点则不用加载顶点和索引数据。

网格简化
一个地形表面包含一个
高度图(height map)和一个四叉树(quad tree)。四叉树的每一个节点,是一个地形补丁(patch)。
在最低级别,地形补丁使用程序生成的顶点,并且所有顶点被放置在一个传统栅格(grid)中;在分支(branches)处,我们进行网格简化。网格简化器在每个顶点输出2个float值,分别是X和Y,而Z通过采样高度图被重构。
这使我们得以用少量的顶点来维持显著的细节。我们得到了视觉质量以及性能,因为GPU更倾向处理大三角形而不是小三角形(*这里和之前一篇可见性缓冲又联动了)。
地形补丁也会引用它们的低精度网格。在摄像机远离网格时,顶点会向低精度的一侧部分做插值(合并)。
当相机离网格足够远(sufficiently)时,所有顶点最终都折叠到最低精度的网格——我们就将其(整体)切换到低精度网格。
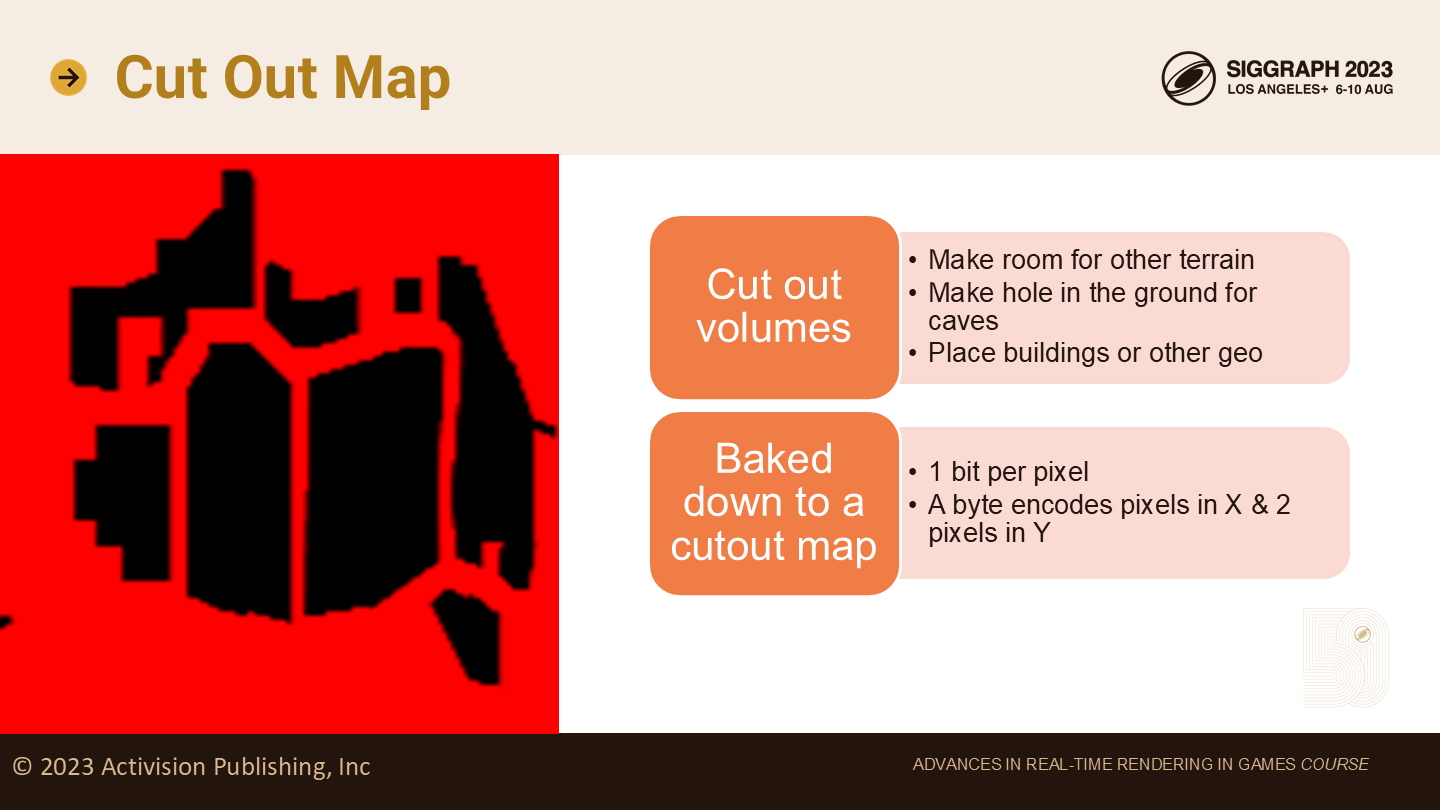
cut out贴图
当制作地形时,艺术家们通常使用cutout体积来标记不希望生成地形的区域。
这有时是因为低分辨率远景的地形中需要让出(性能)空间给其它位置,在可游玩的区域提供更紧密的地形网格;这也用于在地形上挖洞,以开辟山洞或是放置建筑。
cutout体积在每个地形上会烘焙到一个纹理上,它在内存方面非常高效,每个顶点只需要1bit。一个字节(byte)中编码了8个顶点——2行各4个顶点。
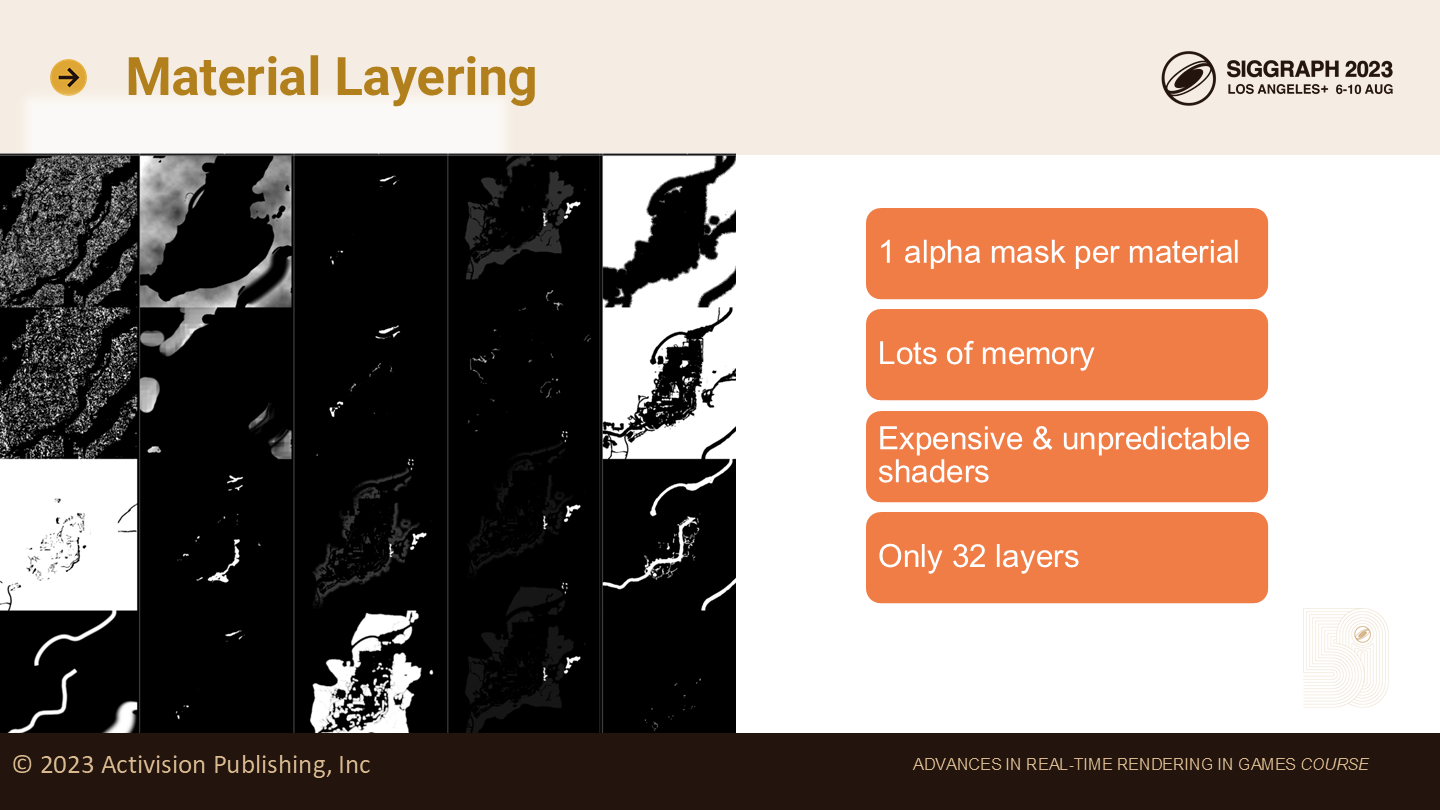
材质层级
一个地形表面由一组材质构成,我们称为地形层级。传统的地形层级可能是草地、沙地、泥土等。
在我们原始的地形技术实现中,每个地形层有一个单独的alpha遮罩。
我们只支持32层地形层,但所有的alpha遮罩仍然需要大量的内存。(*memory,英文不区分,但其实基本是说显存)
同时shader的开销也是不可控的,多数像素可能只使用了1层,但也没有办法阻止一个像素使用全部32层来渲染。除此之外,32作为限制也是一个过低的值,我们希望提高它。
*这里主要是说想把分层做得动态一些,在旧的结构里32层即使没有用到也有很多需要计算的部分。

逐顶点材质(OMPV)
在Black Ops Cold War(黑色行动冷战)中,Treyarch将地形层遮罩技术替换成了一项新技术——逐顶点材质,简称OMPV。
OMPV使用一个索引映射图,我们在图中展示为红色——它为每个像素存储一个字节数据;以及一个颜色映射图,展示在索引映射图的左侧,为每个像素存储RGB值。
通过OMPV,层遮罩就不再需要了,而由于颜色是采用BC1格式压缩的,这能显著的节省内存。
对于每个像素,索引映射图记录了最重要的的层,而颜色映射图为该层提供了染色(tint)的数据。
*注意这里是映射(map)数据的贴图,不是材质贴图。后面会混合具体的材质纹理。

OMPV分析
通过OMPV,假设要为T纹素着色,shader代码中会收集周围4个顶点的索引和颜色。
我们用每个顶点中定义的贡献度(contribution)计算alpha值。而纹素越靠近一个顶点,则该顶点对应的alpha值就越大。
每个顶点的索引指向一个地形层。由于每个顶点可能会引用同一层,我们可以通过累加alpha值来加速重复层的处理过程。
例如,假设所有4个顶点恰好引用了同一层——而这也是很常见的情况,这样相比于采样同一材质4次,我们将只采样一次就够了。
基于JT在他的GDC演讲中介绍的“定义不清”(ill defined)的问题,我们将alpha值乘2,之后再收缩到0至1的范围内。(*精度问题)
之后我们通过艺术家制作的显示纹理(reveal map)来混合所有层,这样他们也可以对混合的过程有控制力。
并不是所有层都被同样处理。所有层会基于索引排序,有着最低索引的层作为基础层不会被合并——它始终有着1的alpha值。
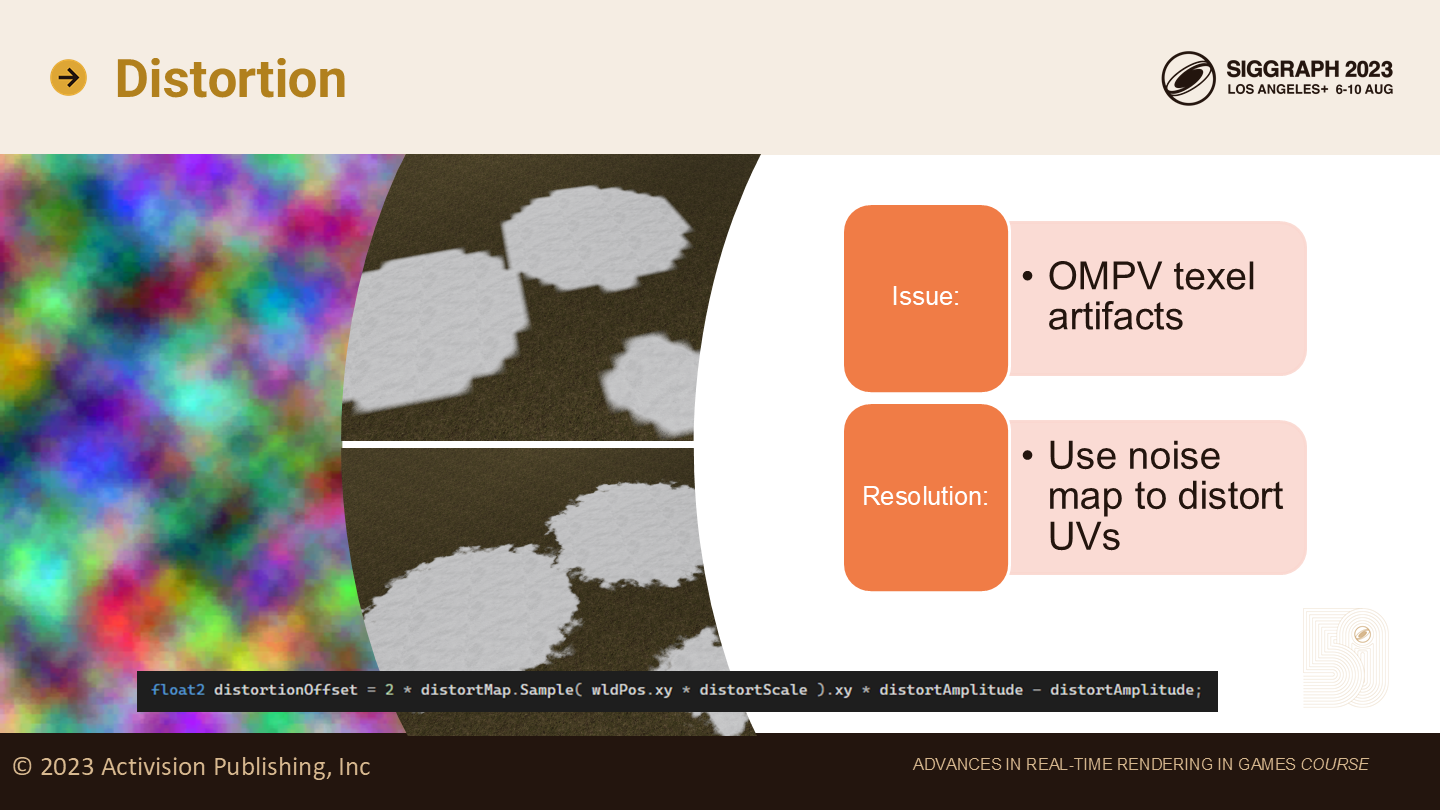
扭曲
与节省性能相对的,OMPV也有其自身的问题。(*原文是has its fair share of,公平份额的issue)
第一个问题是,通过之前介绍的方法,绘制的结果看起来是“像素化”(pixelated)的。从右侧上方的图中可以明显看出。
为解决这一问题,我们通过一个全局256X256的扭曲贴图来扭曲UV——如图所示。
艺术家可以逐层控制扭曲的幅度和频率。这是一个映射层面的概念,因为UV在索引和颜色映射被采样前就被扭曲了。

Tile隐藏
不管是否用OMPV,当一个地形层被用于地图上大画幅(原文是swath ,直译是刈幅)的部分时,平铺视觉故障就变得显眼了。解决这一问题需要用到我们称为tile隐藏的技术。
在每一个顶点,我们基于世界空间位置为顶点计算了一个随机旋转。这个旋转是0-15之间的一个整形值,从角度转化成弧度。
这种方式能有效掩盖平铺视觉故障,但由于添加的随机旋转,我们不能混合重复的地形层了——除非它们有着相同的旋转值。
在上方的图中,由于大部分顶点都会引用草地材质,通常着色一个像素只需要采样草地材质一次。
在执行了隐藏步骤后,由于4个顶点可能有不同旋转值,着色一个像素可能需要采样4次,每次使用不同的UV。不过为了这种视觉提升付出的开销是值得的。

远景连续UV
另一个问题是当同一个纹理被用于地图上大画幅时,最终所有最高的mip中的细节塌陷成了一个单色。这个问题的解决方法被称为远景连续UV(Vista Uvs)。
使用Vista Uv,我们计算了第二套UV的集合,和原始的UV类似——除了缩小UV以放大被采样的纹理。我们重新采样了漫反射系数(albedo)和法线(normal)以计算这些宏观的贡献度。
我们在常规贡献度和宏观贡献度之间插值,基于摄像机距离来计算最终的贡献度。
在某些类型的素材上——例如岩石,Vista Uv能在远景出产生很好的细节表现。

OMPV的问题
OMPV的另一个问题是材质之间过渡的边界太明显。这里(图中)我们展示了从泥土到沙子的过渡发生了什么。
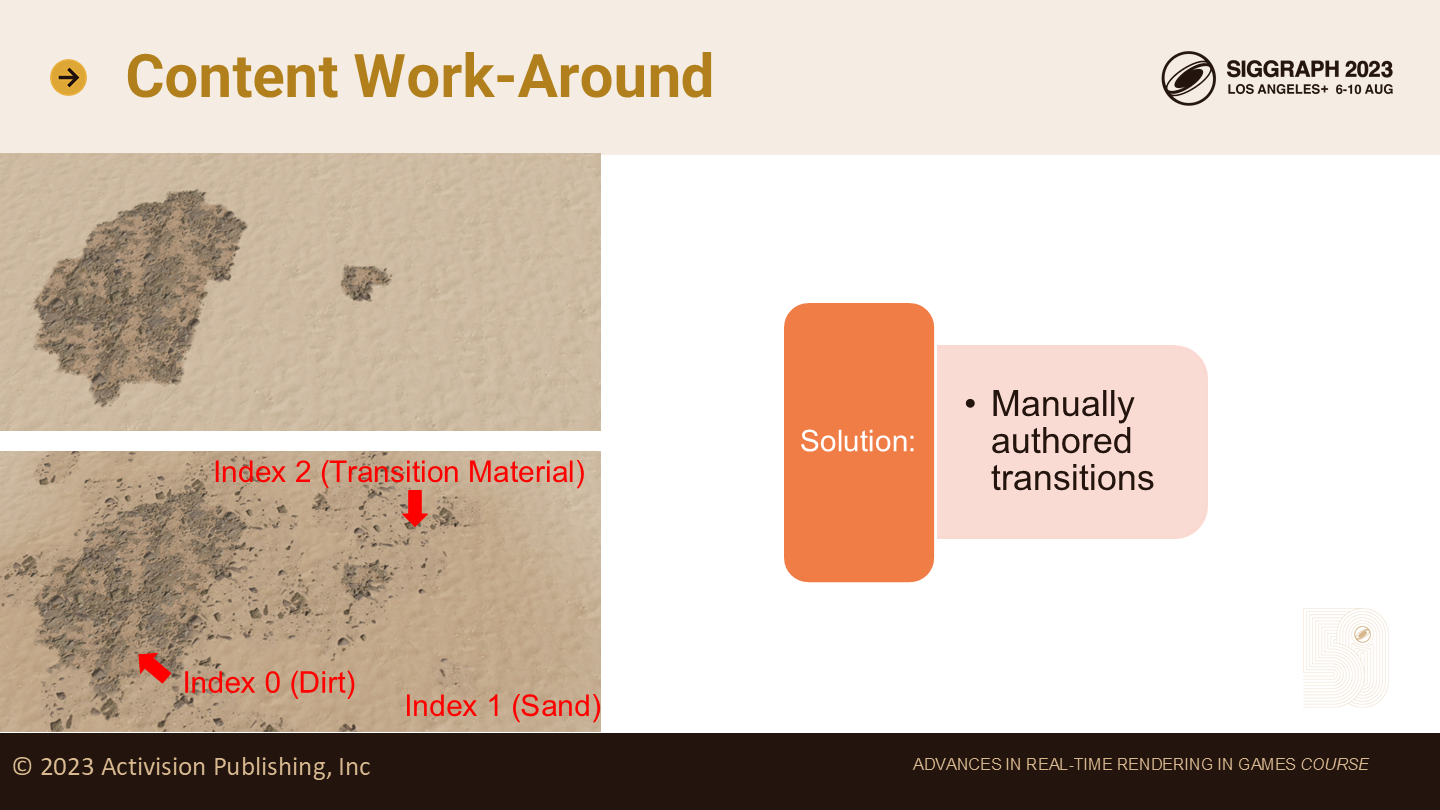
围绕地形的内容工作
目前为止我们采用的方案是艺术家手动调整过渡材质。这样效果不错,但会带来很大的手动工作量。
而由于每次过渡都是一组全新的纹理,这也会增加纹理streaming系统的压力,并消耗宝贵的内存。
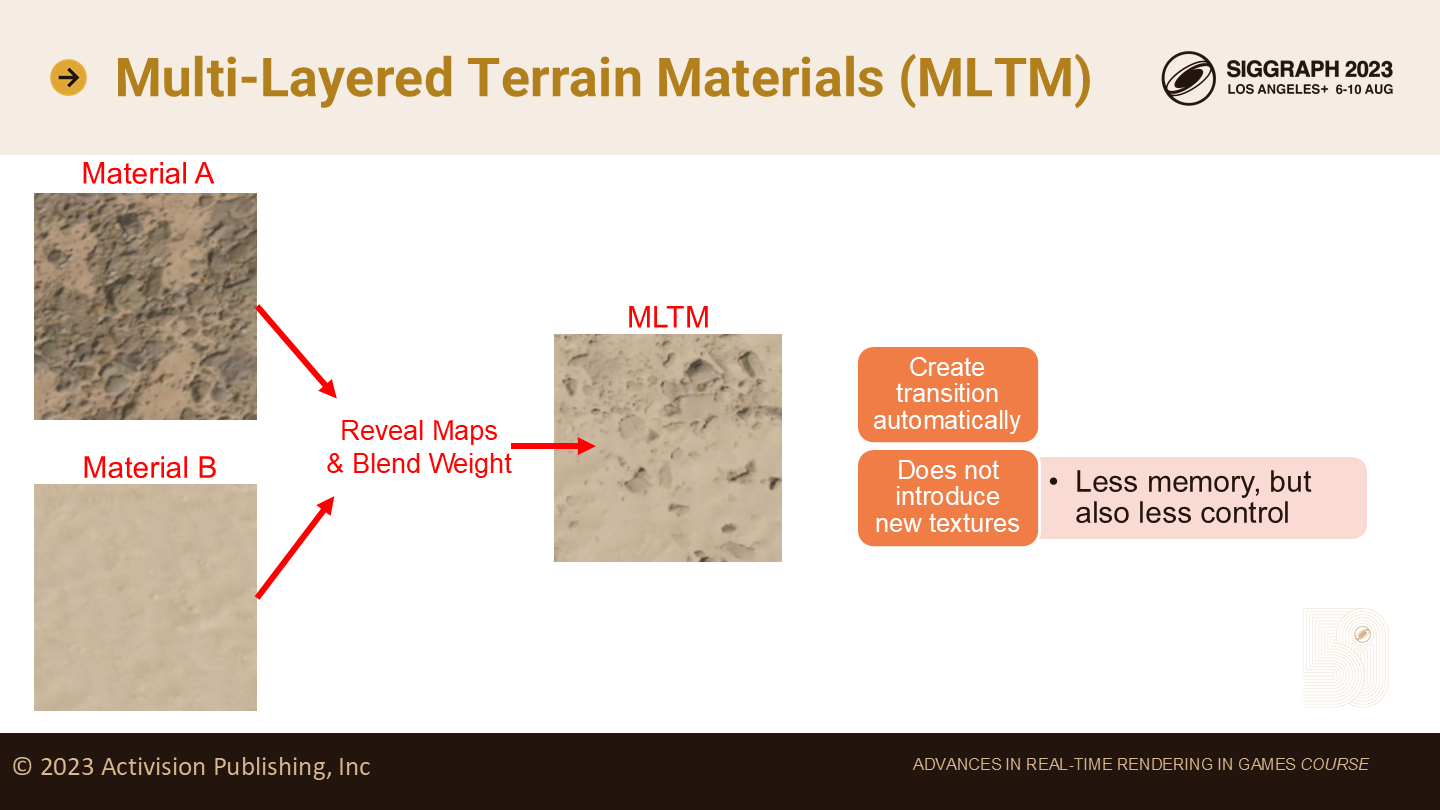
多层地形材质(MLTM)
目前我们为这个问题实现了一套方案,被称为多层地形材质(Multi-Layered Terrain Materials),缩写为MLTM。
一个多层地形材质接收2个地形材质的输入,以及一个用于混合两种材质的阈值(threshold)。它对应的reveal map被用于计算混合效果。
实际上这也类似Photoshop制作的过渡效果,但不需要额外内存开销。
所有混合过程都是运行时执行的。这确实会增加shader的开销,但由于这种材质只用于(两种材质的)过渡计算,因此是能接受的。
*这里说的几个点都是相对前一页,艺术家手动调整制作过渡纹理的情况。

虚拟纹理
虚拟纹理是在运行时被用来模拟(emulated)超大纹理的一种处理。
类似虚拟内存为计算机显著地在物理内存的基础上增加内存一样,虚拟纹理能使本来特别大(超过尺寸限制)的纹理变得可行。
这个模拟的关键是2类纹理:
- 首先,有一个物理纹理(physical texture)以管理超大纹理的页——一个页对应模拟纹理的一小块方形区域,或它的mip。一个页通常有256X256像素,但它也可以是你需要的任何尺寸。
- 其次,有一个间接纹理(indirection texture)存储足够的信息,以便GPU能重定向采样物理纹理中存储的纹理数据。其中的一个像素将指向物理纹理中的一个页。
例如,一个4K的物理纹理包含256x256页,再乘以2K的间接纹理就能覆盖512K的纹理。
虚拟纹理通常也被称为程序化(procedural)的虚拟纹理,因为最终的模拟纹理是程序化组合材质及其它绘制单元的结果。
在本次分享中,程序化这个词被省略了,但它实际上是很重要而值得被记住的——因为最终的纹理是一系列复杂的混合处理的结果,并不存在于硬盘上。
*现在VT已经不止用于处理超大尺寸纹理的问题了,但最初针对超大尺寸的这个思路确实是约翰卡马克提出的。

自适应虚拟纹理(AVT)
虚拟纹理对于模拟不符合GPU尺寸要求的纹理是很有效的。
然而,其数量级对于模拟更庞大的纹理还是不足。
例如,512K的虚拟纹理只能覆盖大约3平方英里、每英寸(inch)25像素的地表。
对于更大的虚拟纹理,育碧公司的Ka Chen在2015年的GDC上介绍了自适应虚拟纹理(Adaptive Virtual Texturing)的方案。之后我会把它缩写成AVT。
AVT可以模拟最多包含24层mip的纹理。以每英寸25像素作为精度时,这足以覆盖10.6平方英里的区域。
作为算法的基础,世界被切分为210英尺(feet)左右的很多部分(sectors);每个部分通过一个虚拟图像(virtual image)来管理——这部分实质上就是传统的VT。
虚拟图像的尺寸是动态的,它会随摄像机距离的不同而变化——这就是它被称为自适应的原因。

虚拟图像
一个虚拟图像有16个mip。通过它们,我们能覆盖210平方英尺,每英寸25像素精度的区域。
只有靠近摄像机的sector是被激活的,我们只支持最多255个sector。
也有一个默认的sector覆盖整个世界,而它总是使用16mip的虚拟图像。
屏幕左上方的方形区域展示了这种方案的间接纹理——它只有512X512像素。
- 默认的sector是灰绿色的,它占据了左上角。虚拟图像在这个间接纹理中为它们各自分配空间。
- 从图中可以看出虚拟图像中的哪一部分图样(scheme)是负责为哪一部分地形着色的。当我们靠近一个sector,你可以看到它的虚拟图像变得更大;当远离时,它对应的虚拟图像就会缩小。
*这里作者演示了一段视频,文稿中虽然没有但从颜色对应能理解作者的意思。
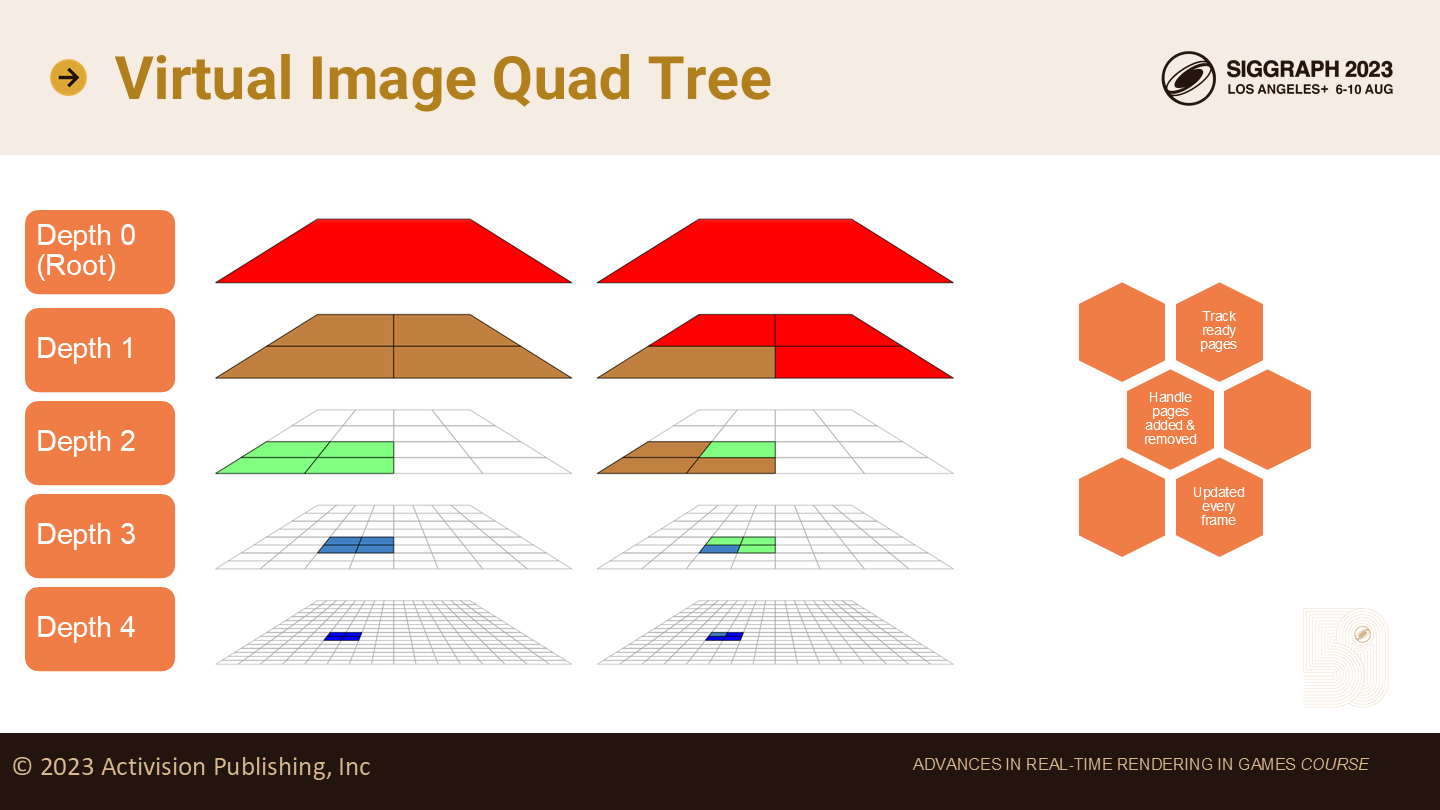
虚拟图像四叉树
一个虚拟图像的四叉树(quad tree)比起普通的四叉树更复杂,因为它要追踪GPU中使用的页。
当展开四叉树的分支时,部分子节点可能没有对应的页,这时它们需要指向父节点的页。图中展示了这一过程。
例如,在深度1,根节点的4个子节点需要被展开,以创建棕色的页;另外3个子节点则直接指向父节点(以此类推)。
每一帧,这些页可能变为准备好的状态,或相反地变为无效的状态。
当一个新的页被合成时,四叉树直到下一帧才更新。这是因为我们无法承受GPU中使用了合成中的页的风险。(*基于多线程的原因)
当一页不再被请求时,它会进入缓存中进行计时。它在四叉树中被(逻辑)删除了,但内存中它会存在至少3帧。这对于GPU不会使用回收中的页已经绰绰有余(more than enough)了。

间接纹理
CPU版本的四叉树对于GPU来说太复杂了。(*这里我理解是这个算法对于偏并行计算的GPU不友好)
作为替代,我们把四叉树烘焙到一个间接纹理上。每一帧,游戏会计算前一帧和当前帧的四叉树的区别。
这一步会被转换成指令,并在一个compute shader中执行,它负责更新这个间接纹理。
The picture here shows what the CPU quad trees looks like from the perspective of the GPU.
图中展示了从GPU的角度来看CPU中的四叉树的状态。

动态尺寸
当摄像机移动到和sector足够近,游戏会决定启用新的mip并添加。
它首先会从主间接纹理中分配更大的子间接纹理,之后会用每帧填充间接纹理同样的算法填充它。
当摄像机移动得足够远,相反的处理会被执行。最终mip会被从间接纹理中移除。

间接纹理的纹素
一个32bit的间接纹素(texel)提供了物理页中的坐标。它也指出了页在四叉树中的mip级别。
所有这些信息在从sector的Uv定位到物理页Uv的过程中都是需要的——这里的代码片段展示了这一转换过程。

动作中的间接纹理
我们也开发了工具以帮助可视化和debug间接纹理——如图所示。
每个地形的方块代表了间接纹素的32bit,并被展现为一个albedo颜色——而通常它们会被以物理页(实际的纹理)填充。

地形的渲染在prepass和opaque pass中都执行了。
During the prepass, terrain writes to the depth buffer and to a stencil bit reserved for super terrain. We also write the geometric normal to a g-buffer.
在prepass阶段,地形写入深度缓冲(depth buffer),对于超大地形还会写入一个模板bit。我们也会将几何法线写入gBuffer。
During the opaque pass, terrain is deferred rendered using a full screen quad. Every pixels that have the stencil bit set, sample from the virtual texture to shade the current pixel.
在不透明着色阶段,地形以延迟渲染的方式通过一个全屏的quad来渲染。每个设置了模板bit的像素,从虚拟纹理中采样来为当前像素着色。
*这模板bit的具体数据结构作者没有介绍,但基本是和之前介绍的虚拟纹理索引有关。

虚拟纹理的一个核心面向就是GPU驱动(driven)。
在opaque pass中,它既为每个像素着色,也计算可用的情况下会使用的物理页。这些信息被存储在一个回馈buffer中(feedback buffer)——它在3帧之后被CPU读取。
它的分辨率是240X136像素,不过我们也在研究在低端硬件上使用更小分辨率的可能。
基于性能方面的考虑,这部分也没有线程同步(thread synchronization)的过程。
*这里的feedback buffer主要是起到纹理计算与分派的作用。
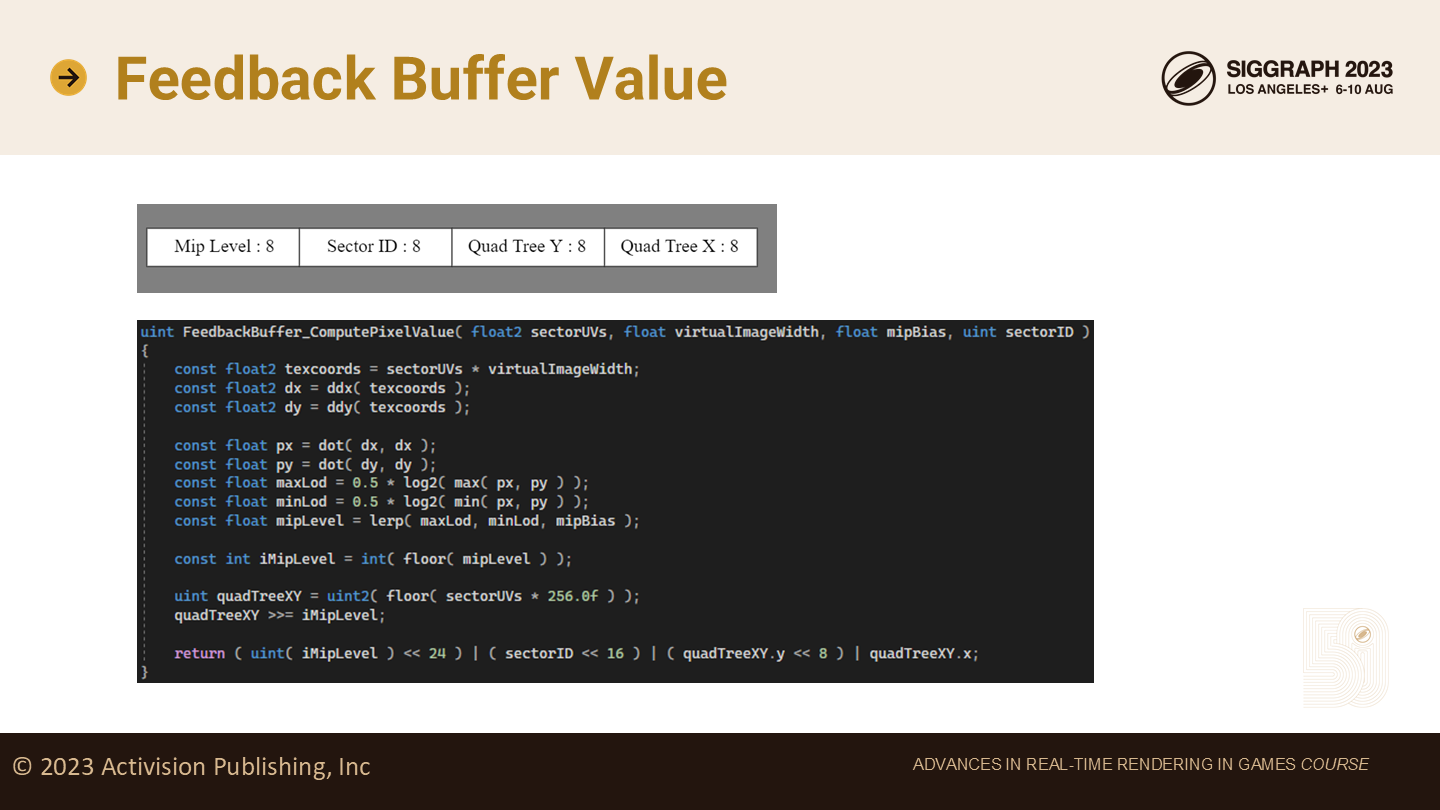
在opaque pass阶段,每个地形像素存储一个32bit的值到feedback buffer中。
它写入了虚拟纹理的mip级别,像素的sector ID以及间接纹理四叉树节点中的四叉树坐标。
其中最困难的部分是mip级别。它是通过查找UV的梯度(gradients)来计算的,而图中的代码片段展示了这一过程。
*简单分析下,这里用偏导数(ddx,ddy)计算了UV(textcoords就是纹理坐标,缩写就是UV)的变化率,来确定应该采用的lod或者说mip级别。如果不是虚拟纹理,这一过程一般已经封装在纹理采样的函数中了。

在GPU写入feedback buffer完成后,CPU从中读取。在其精度是240X136时,这意味着要处理32000个值。
- 首先,我们计算所有唯一的值。
- 之后,我们将子节点的计数传递给它们的父节点。这是为了确保当子节点没有足够的hits(内存命中)时,期望父节点能有(对应的内存数据)。
- 最后我们按照流行度(popularity)来排序。我们希望最先请求的页是最需要合成的页。
我们对sector的根页做了偏移(bias),因此如果一个sector是全部可见的,至少有一页空间是留给这个sector的。我们也基于相机速度对高分辨率的页做了偏移。
由于feedback buffer是通过非同步的线程来更新的,因此它可能会有很多噪声(noisy)。我们通过引入一个阈值来解决这一问题,因为我们不希望影响页的合成。
有时,接近阈值的页会有一帧超过这个阈值,而下一帧又低于这个阈值。因此,我们也需要抢救(rescue)已经可见的页,以避免视觉故障;我们也从不请求(缓存中)超过1/3的总数的页,以避免视觉扰动(churn)。

尽管前面已经介绍了很多(数据和优化细节),游戏中仍然会时不时地看到低分辨率的虚拟纹理。(*这里指预期外的一些视觉故障情况)
例如,如果你的摄像机面向一个方向,之后快速朝向侧面,使屏幕渲染内容的请求填满了缓存区域,之后再做180度旋转看向身后,新的页就会经过几帧才能添加到缓存——这种情况就显得很明显。
解决方案是为每个sector选择最接近的中等分辨率的页,并将它们添加到请求页的列表中。
我们经常进行摄像机位置的瞬移(teleport),或很快的摄像机切换——例如从天空切换到玩家实际出生(spawn)的位置。游戏会提前告知摄像机瞬移的目标位置,因而我们可以提前stream合适的资源。(*通过带有预判的加载来解决快速切换问题)。
AVT技术也肩负着创建中等分辨率页的任务。
Virtual texturing is essentially a cache. Typically, you only want to populate caches with up-to-date data. If the VT wants to composite a page, we need to make sure all the mips that are needed for that page are loaded before the page is composited.
虚拟纹理实际上是一个缓存。通常来说,你只希望缓存中填充合用的数据。如果VT希望合成一个页,我们需要确认相关的mip都已经被加载了。
不幸的是,在存取速度很慢的硬件上,可能需要数秒来加载需要的mip。这会导致视觉上的BUG,摄像机会很快用尽VT的空间,而整个地形看起来就像PS游戏(那么糊)。
我们发现更好的方式是在页被请求是立刻去合成,但标记它是低分辨率的。
15帧之后,如果它还没有准备好,我们会重新合成一次,并假定我们有足够的带宽来执行。
之后这一延迟会加倍成30帧,我们会再次尝试合成它——直到这个页被标记为准备完成,我们会最后一次合成它(作为合适的分辨率)。
*这里更多是在加载很慢的设备上的一种取舍,即性能实在不行的时候如何尽量看起来舒服一点。这里实际上说的就是VT方式下进行了从低精度mip开始的加载。
结语
读的上半部分更多是基于虚拟纹理的介绍,这项技术提出已经有相对不短的时间了,但对于硬件还是有一定基本要求的。
值得一提的是,虚拟纹理也不仅仅用来处理超大纹理的问题,例如虚幻引擎中的SVT和RVT,虽然不完全是一回事,但是其中有很多映射和缓存思想是相似的。同时VT也是渲染调用上的一种优化,例如能减少材质绑定的过程,调整渲染批次等。
而VT似乎也是卡马克大神在游戏领域提出的最后一项有前瞻性的技术,可惜对应的游戏《Rage》表现就一般了。
下周会继续更新这篇文章的下篇,看看更多地形合成上的细节。
最后是资料链接:
国外一篇比较好的Virtual Texture总结介绍
Large-Scale Terrain Rendering in Call of Duty 的PPTX