本福特定律(Benford's Law),它指出在自然產生的數據(如人口數量、財務報表、河流長度等)中,數字 1 作為首位數字出現的概率最高(約30%),而後續數字出現的概率依次遞減,數字 9 作為首位數字的概率最低(約4.6%)。這一規律尤其適用於跨度多個數量級的數據集。
人為干預的潛臺詞就是數據造假
基本上在學術上也會經常使用!

所以其適用範圍為,隨機數,不受人為干預的,可以驗證的,但像郵政編碼、身份證號等顯然不適合。
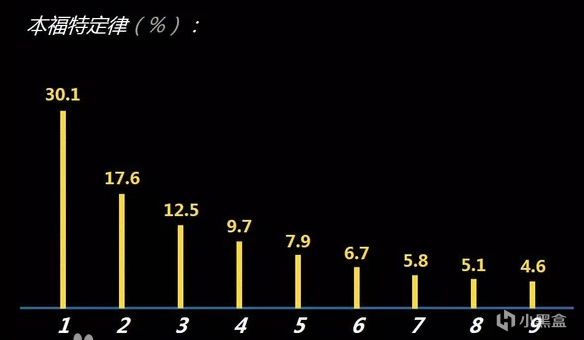
各首位數據的頻率!
光說沒用我們就用幾個實例示範一下就清楚了
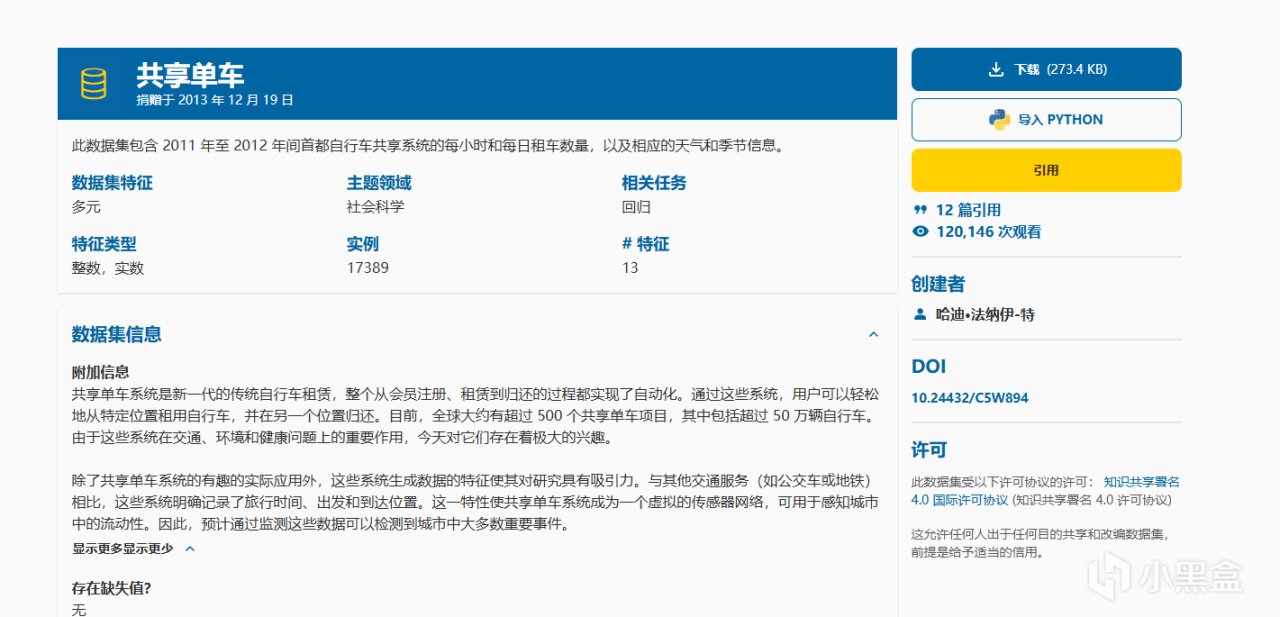
第一個示例:共享單車租借數據
https://archive.ics.uci.edu/dataset/275/bike+sharing+dataset
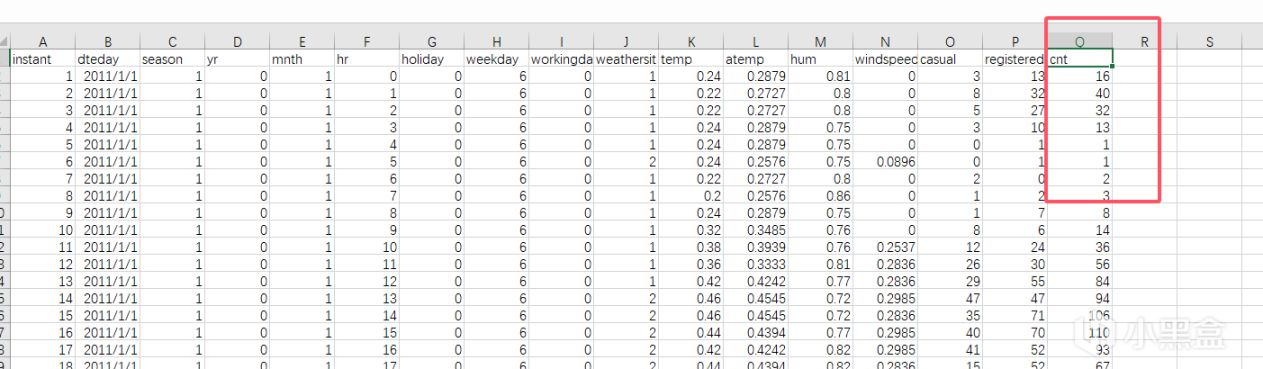
使用的是cnt列的數據
驗證結果:
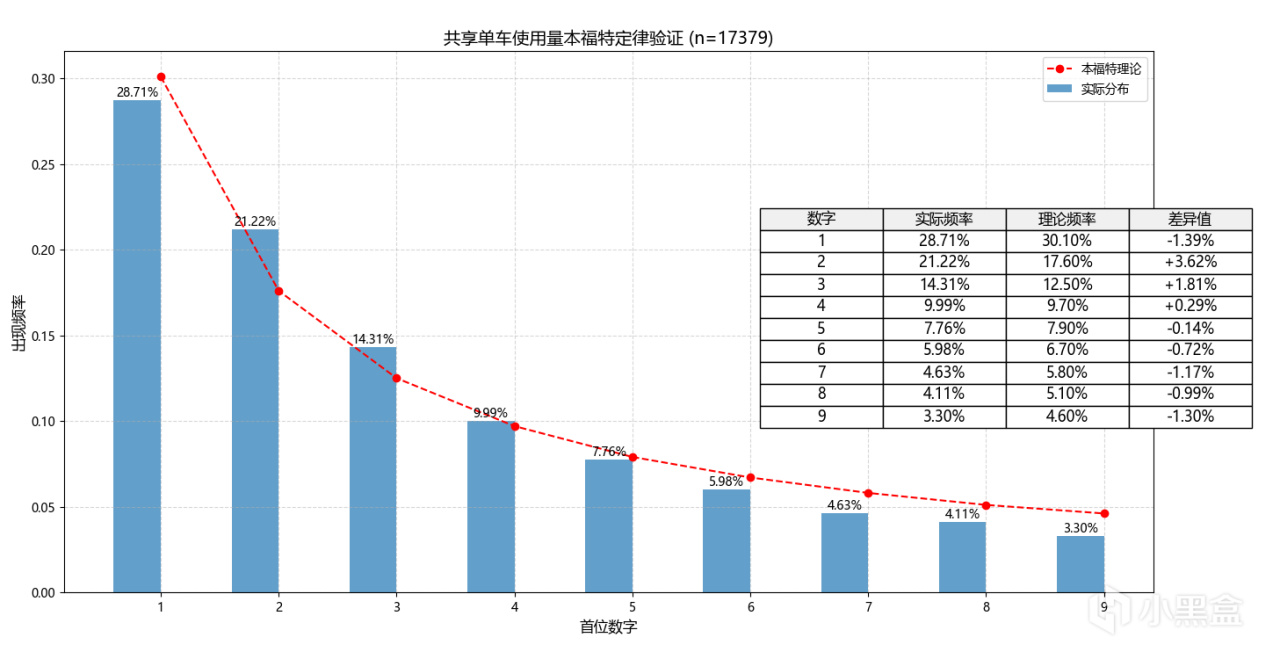
數字為1的實際頻率為28.7%,理論頻率為30.1%,誤差1.39%,還算可接受範圍
第二個示例:人數數據
https://catalog.data.gov/dataset/border-crossing-entry-data-683ae
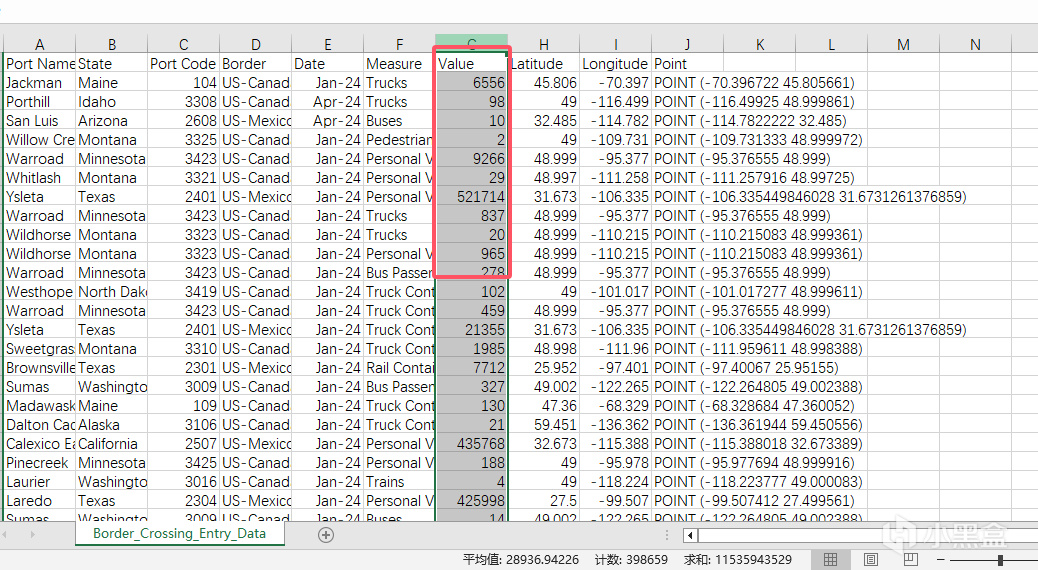
使用的是value所在列,即值。
運行結果:
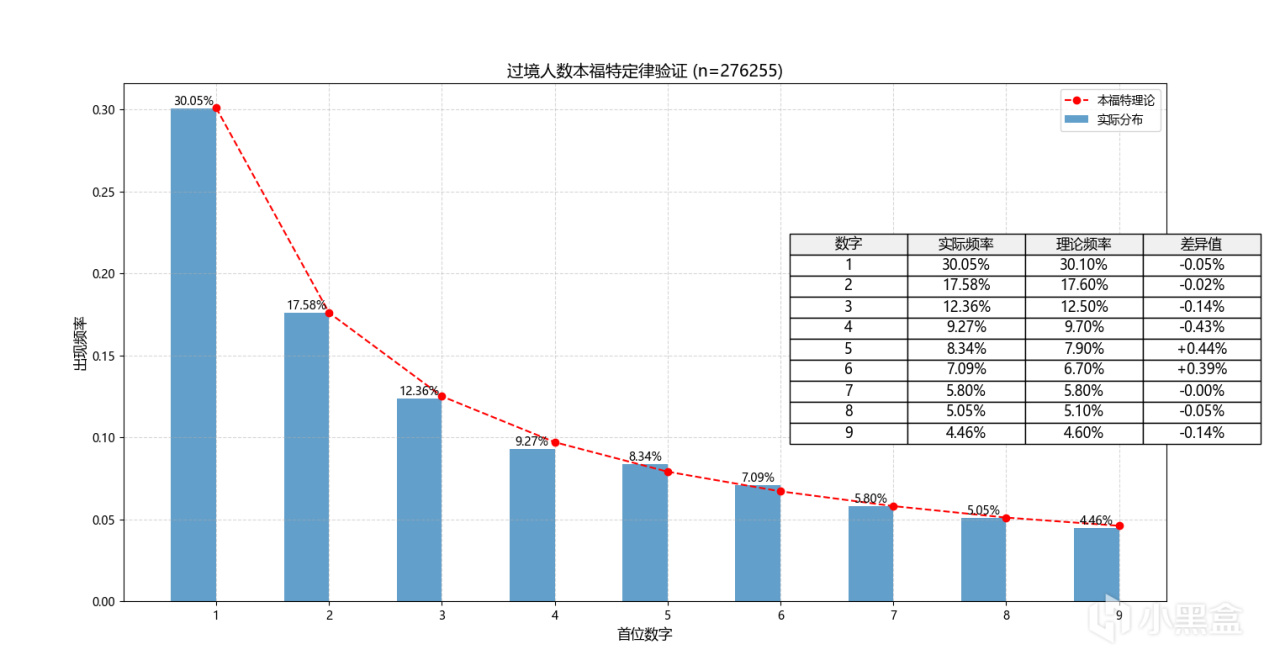
這個運行結果頻率就很高了
關鍵還是數據量要大,表現出隨機性,當某一數據出現明顯偏離一般指首位數字為1的情況,那就說明這組數據不具有隨機性,即存在人為干預!
除此之外,你也可以抽取某用戶發佈的視頻播放量,點贊量,評論粉絲數,也可以用這個進行判斷,亦可以針對遊戲的評價數量每小時進行統計。
對於理工科,需要判斷海量隨機數據,是否為隨機數據,即不存在認為干預!
也可以通過這個方法快速驗證,通過編程實現不難。驗證隨機性