先来学个重要的小把戏。
我要怎么在代码中引用某个节点呢?——为什么要去引用一个节点呢?因为在一个复杂的场景中,我们可能需要通过代码控制场景中的某个节点。
告诉你一个简单粗暴的办法:
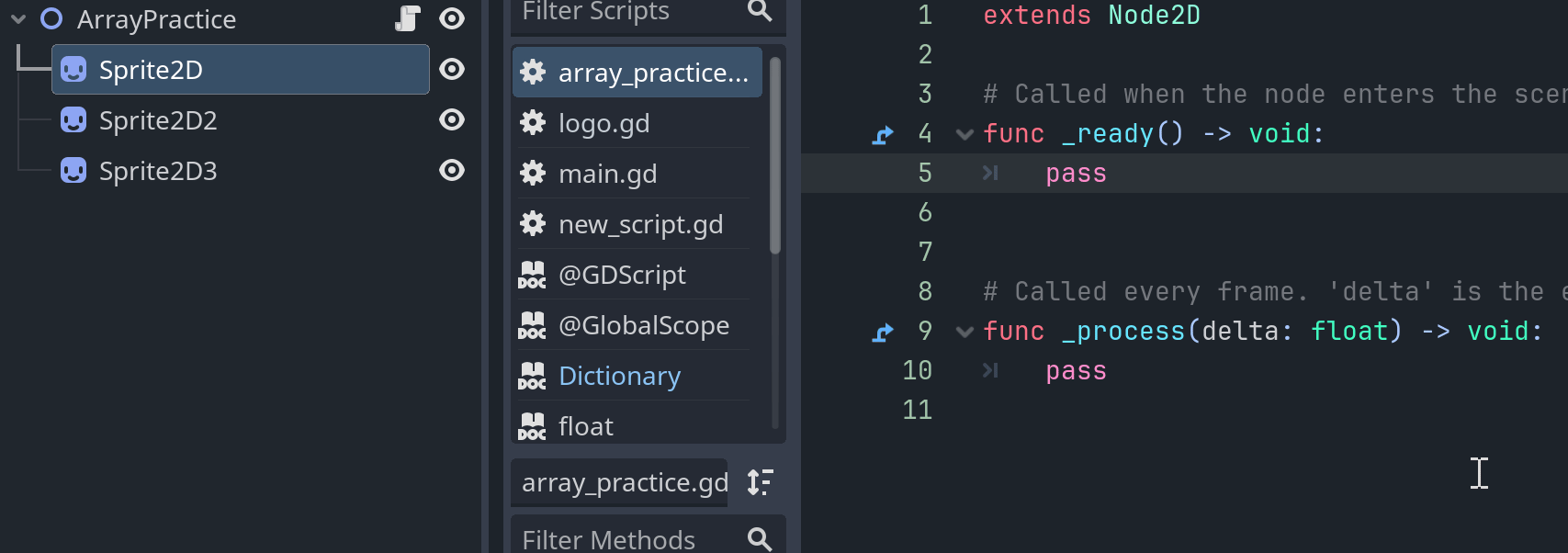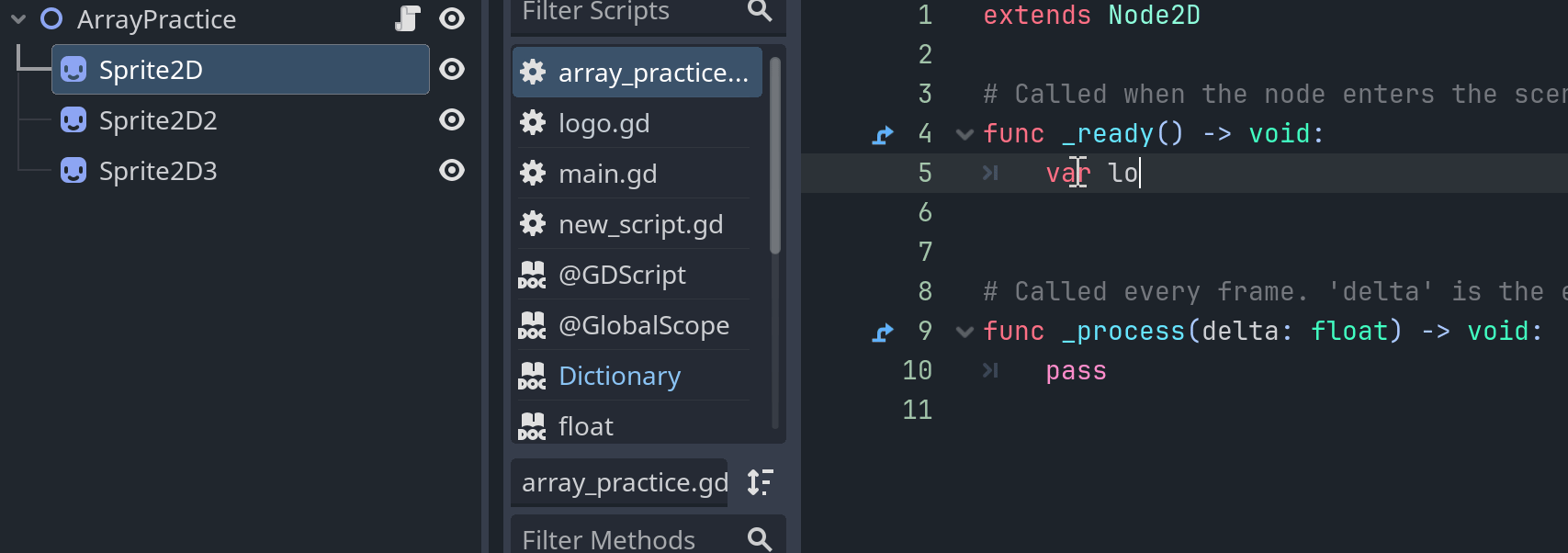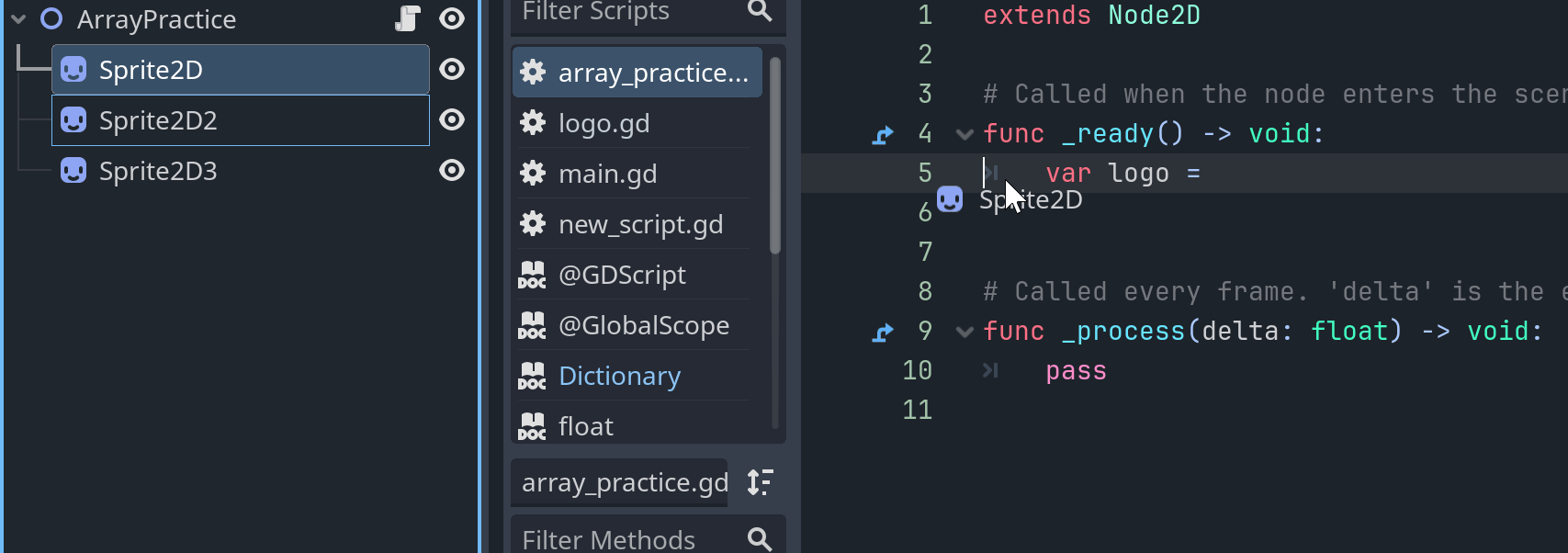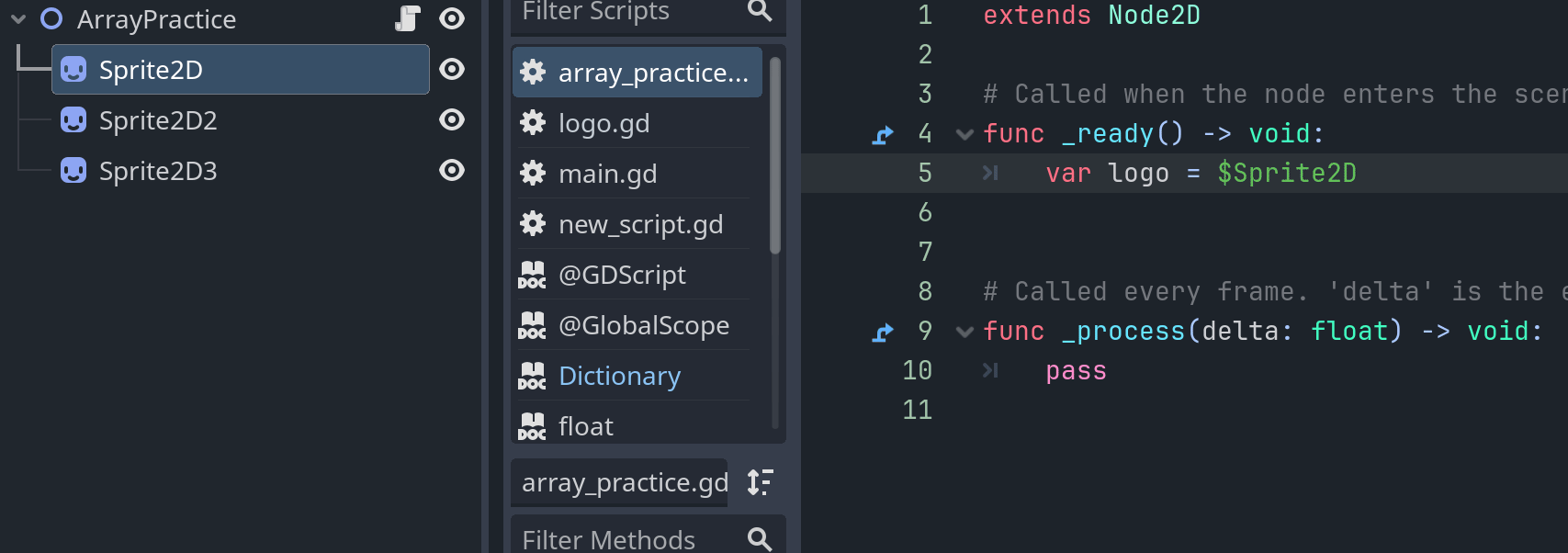
就这么简单,我们就在代码中拿到了这个logo。这是GDScript专门为节点设计的一种特殊语法,可以直接通过类似于文件路径的语法($Path/To/The/Node)来获得场景中的某个节点。场景和文件系统一样呈现树形结构,这种路径式语法是很符合直觉的。例如在另一个更复杂的场景中:
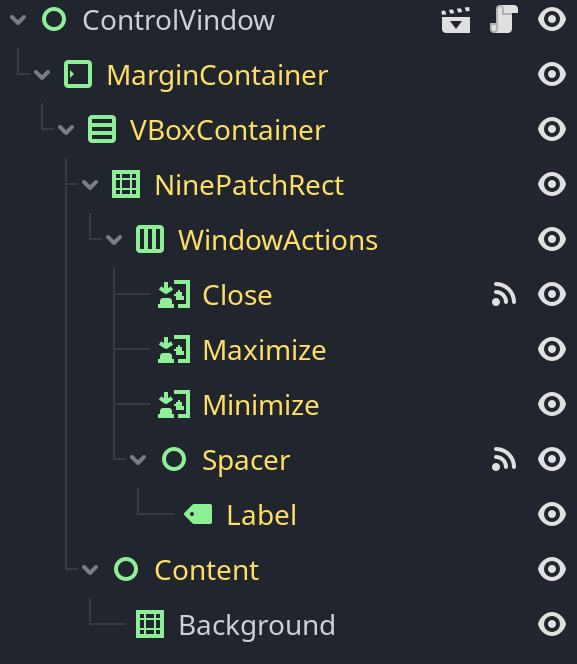
要获得Background,其路径为$MarginContainer/VBoxContainer/Content/Background。
不过,这样子只能在_ready中引用它,很麻烦。好吧,那你说在外面定义它吧。
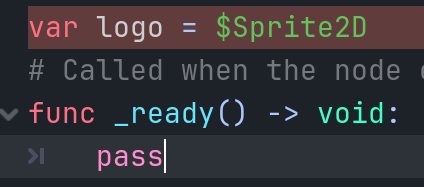
然后报错了。错误信息说:
The default value is using "$" which won't return nodes in the scene tree before "_ready()" is called. Use the "@onready" annotation to solve this.
在ready调用之前,使用$的默认值不会返回场景树中的节点。用@onready解决此问题。
简单来说,ready还没调用的时候场景肯定还没准备好。那么场景中的相关节点肯定也没准备好,如果此时尝试引用场景中的某个节点,我们可能拿不到一个正常的节点,它甚至可能是空的。

前面已经讲到了@export标记,这里要用到另一个标记@onready。和它字面上的意思一样,被@onready标记的变量会延迟到ready被调用后再进行赋值,此时场景已经准备好了,引用某个节点也不是问题。
现在问题来了。如果场景中有5个logo排成一排,我想让它们每帧逐个上升一点怎么办?
先准备一个场景,在一个2D场景中放入若干个Sprite2D。如果你跟着前面的文章做了,用那个有很多logo的场景也行。
大概这样
你可能想到用刚才所学,直接定义5个@onready变量挨个操作。不错,那要是有10个logo,甚至100个呢?
首先要解决的问题是,如何引用这100个logo。
前面介绍到的数据类型,都是代表某一个东西。这里我们要引用很多个东西,就需要用到一些容器(container)来装它们。在某些时候,这类容器也被称为集合(collection,不要和源自数学的集合set混淆)。
数组
数组(array)是我们要学习的第一种容器类型。GDScript中的数组用以保存一系列对象。数组中的内容可以是任何类型,并且数组可以动态增减其中的元素。

要获得数组中的元素,也需要用到方括号。方括号中填入元素所在位置。这个位置我们一般称为索引(index)。有时候也称为下标(subscript):

注意,在GDScript以及大部分主流编程语言中,数组的索引都是从0开始的。所以第一个元素的索引为0,1是第二个。
GDScript中的数组索引和Python一样,可以为负数。-1就是数组的最后一个元素,-2则是倒数第二个:

下面是一些常用的用来操作数组的函数:

append会在数组末尾追加一个元素。pop_back会弹出数组的最后一个元素并返回,而`pop_at`则是弹出指定位置的元素。
数组的`push_back`函数和append作用相同。pop和push实际上是针对栈(stack)这种数据结构常用的术语。概念上来讲,栈是一种操作受限的数组。它只能在最后(或者说”上面“)追加元素,每次只能删除最后(最上面)一个元素。是一种先进后出/后进先出(Last in first out)的数据结构。想象一下(没有”托盘“的)筒装薯片。
如果我要你逐个print数组中的元素,(中略),那要是你有一万个元素在数组中呢?
这里我们需要用到循环(loop)来减少重复的代码。
当…
为了输出数组中的诸元素,我们可以用一个变量来记录当前print到哪里了。只要这个值还没超过数组的长度——准确地说是“最大有效索引”——我们就继续print。
这里可以到while循环。while循环的语法如下:

只要while后面的条件满足(也就是说为真),while下方的代码块就会执行,否则就退出循环。
len函数顾名思义(length),可以求出数组的长度。
这个变量初始化为0,也就是数组的一个有效索引。在条件中,只要它不大于数组长度减一,那就说明还没有print到头。
在循环内部,print之后我们给i加一,下次循环就会print下一个了。如果忘了这一句,你的循环就会永无止境地继续下去……
对于…
好吧我又一次骗了你。其实上面的循环这样写太复杂了。对于数组这样的集合类型,还有一种更简单的循环方式,这就是for in循环。
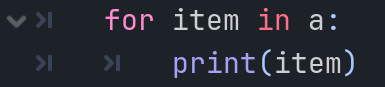
for后面是一个变量名,这个变量会在每一次循环中拿到数组中的一个元素,随后就可以在循环代码块中引用它。
字符串也像数组一样
实际上字符串也可以这样用:

在某些场合我们称这类数据结构为可迭代(iterable)对象,也就是说它们可以逐个产生出一系列对象,且通常可以和编程语言中的某些语法进行互动以简化代码。我们会在后续介绍更多的可迭代对象。
控制循环
除了逐个处理可迭代对象或者根据条件循环,我们也可以在循环内部按照额外的条件来控制循环。
break语句可以直接结束循环。比如这里到3就直接结束循环:

到3为止且不会输出3
continue会跳过本次循环的剩余代码,直接进入下一次循环。如果我们只想在元素为偶数时进行处理,我们在发现不是偶数时就进入下一次迭代。

这里出现了一个没介绍的算术运算符%,它是取模运算符,或者更直白地说叫求余数运算符。如果一个数无法被2整除那么它就是奇数。
现在还需要最后一块拼图来完成一开始的问题。我们如何获得场景中所有的Sprite2D而不用挨个创建变量呢?
这里用到一个叫find_children的函数。顾名思义它可以找到脚本所在节点的孩子节点。它的第一个参数是节点路径,第二个可选参数是节点类型。在这里我们想要找到所有的Sprite2D,所以第一个参数留一个通配符就好,第二个参数填入Sprite2D。注意是字符串,可以在文档中查到该函数的详细信息。

这个函数会返回一个数组,这正是我们需要的。
接下来就是在process里实现我们的目标。
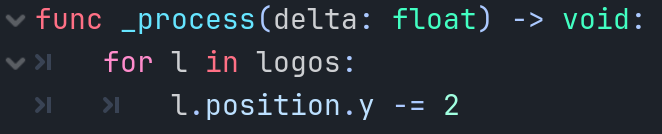
很简单,直接修改position的y坐标即可。
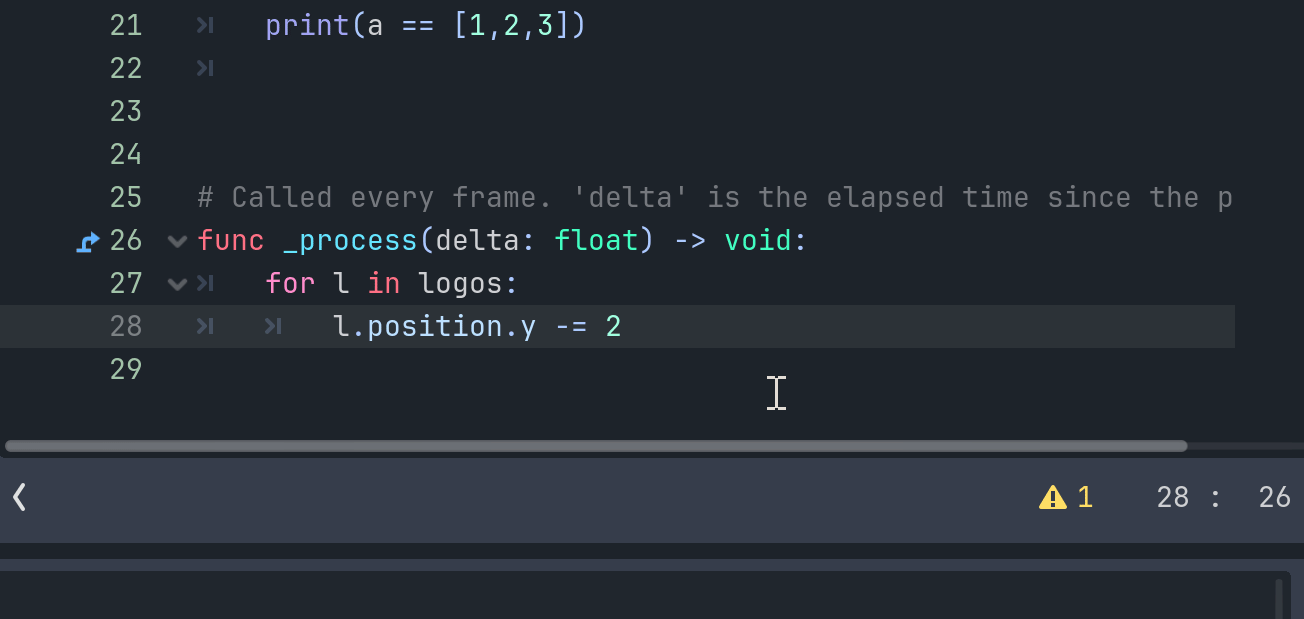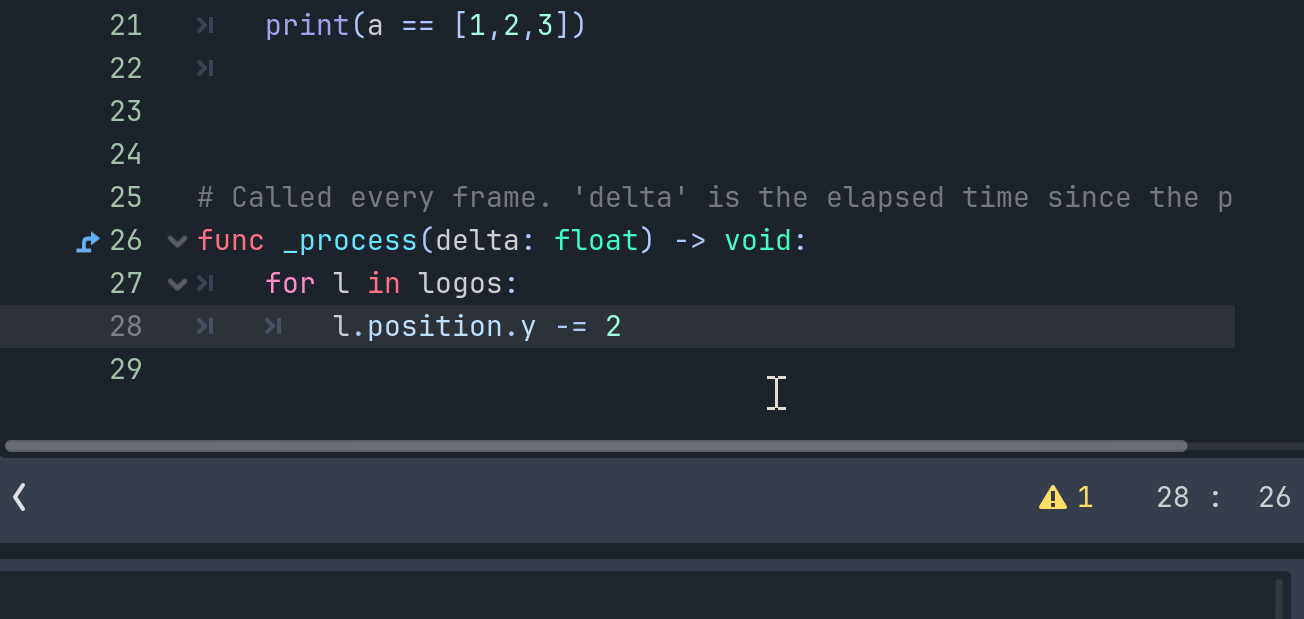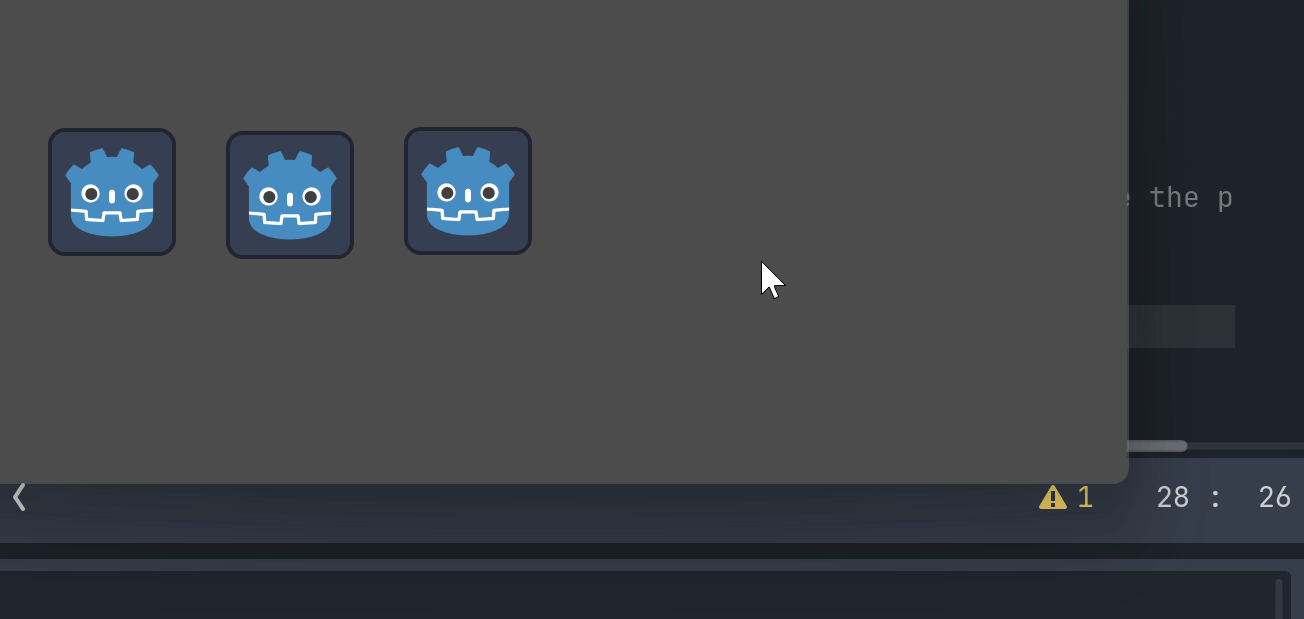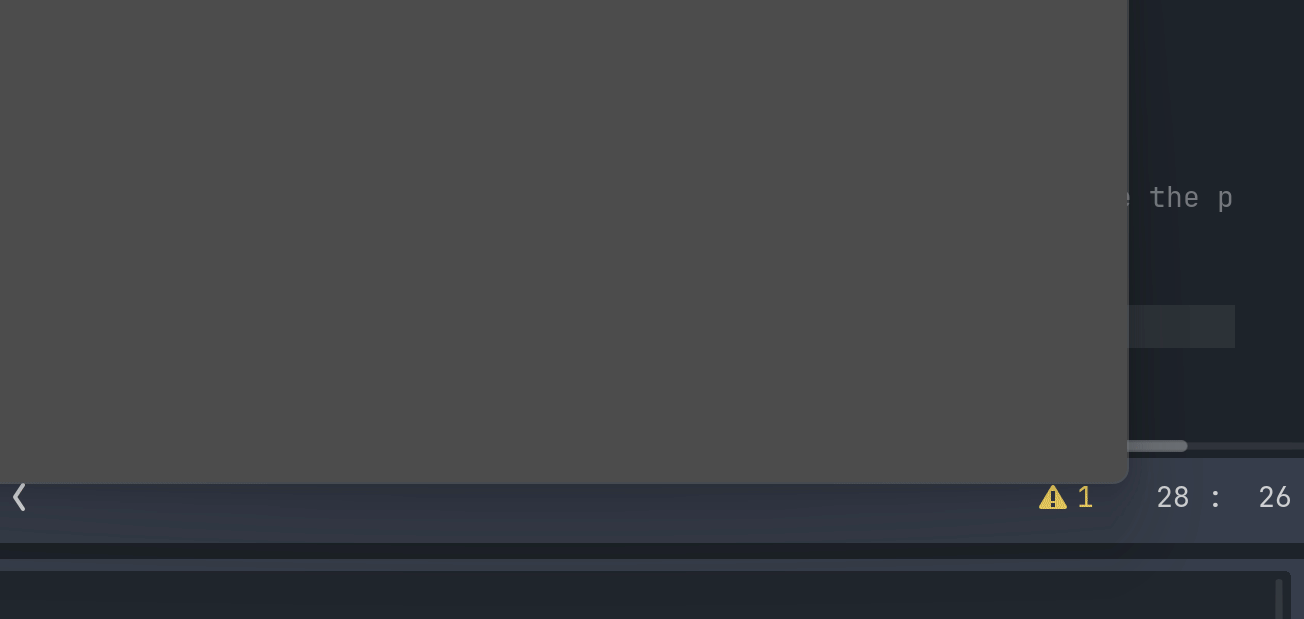
有了循环和数组的帮助,就算它有一万个也不怕!
是否在…
在上面的for in循环中出现了in关键字,实际上它还有一个更符合直觉的用途,就是检查某个东西是否存在于数组(以及其他集合中):

由此可知,in作为一个运算符,用到它的表达式也会返回一个布尔值。
字典
字典是GDScript中的另一个内置集合类型。它的作用是表达某种映射关系。在不同的编程语言中,类似的类型有不同的名字,但是作用是类似的。
好吧,那啥是映射(map)。一般来说映射是一个把两个集合(set)联系起来的函数,通过这个函数可以通过一个集合中的某元素得到另一个集合中的某元素。例如现实中的字典,是字到含义的映射。身份证号码和公民之间也存在映射关系。
在编程语言中,字典通常被描述为键值对(key-value pair)的集合。键值对就是由键和值组成的一种简单的数据结构。字典描述的就是键的集合到值的集合的映射。编程语言中的字典通常一个键对应一个值,不过多个键可以对应同样的值。在数学上可以用满射(surjection)称呼。
GDScript中可以用专门的字典字面量来构造字典:

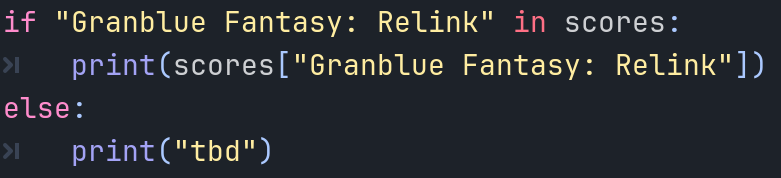
这里展示的是游戏名称和其metacritic评分之间的对应关系。可以看到,字典字面量通过花括号来构造。每个元素(键值对)和数组一样用逗号隔开。键值对中键和值用冒号隔开。这里为了便于展示将它们换行书写。
和数组类似,我们用方括号获得字典中的元素——实际上是根据键来获得对应的值:
如果试图用一个不存在的键访问字典,运行时会直接报错。in对于字典同样可用,它会检查键是否存在于字典中:
字典也可以用在循环中:
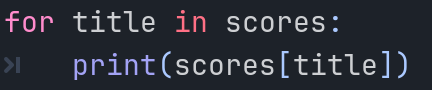
在for in循环中拿到的是字典的键。如果想要获得字典的所有的值,可以用它的values函数来获得:

可以看到,字典的键可以是字符串类型。实际上GDScript中的字典的键支持很多类型,并且同一个字典中的键和值的类型也可以各不相同:

数组一类的相对连续的数据结构可以根据元素所在位置来求得其所在(内存)位置,因此我们也就可以根据索引按顺序获得元素。而字典通常用某种哈希算法实现,它根据键的值通过某种方式计算出值所在的位置。因此使用字典时往往暗示我们不关心顺序。
这篇文章中我们又学到了一个编程中的重要概念:循环。同时还学习了可以在搭配循环使用的两种数据结构。GDScript这条恶龙已经越来越虚弱了!我们越来越接近胜利了!