今天是2025年2月27日,DeepSeek 開源周的第四天如期而至,這次他們甩出了一個大招——開源並行優化策略(Optimized Parallelism Strategies)項目。一口氣帶來了三大開源“法寶”:兩個代碼庫工具 DualPipe 和 EPLB,以及一個專門用來分析訓練和推理框架性能的數據集,其中DualPipe項目署名還有DeepSeek創始人梁文鋒!本文我繼續用更通俗的語言給大家介紹這些技術是如何造就 DeepSeek-V3 和 R1 模型的,它們又會對全世界產生怎樣的影響。

01 新項目到底有多強?
距離開源周結束還有最後一天,DeepSeek的第四彈可是誠意滿滿,一口氣拿出三個項目,今天我的工作量也相當於翻了三倍,其中DualPipe是大家關注度最高的項目,為雙向流水線並行算法,是V3和R1訓練中的核心算法,由三位開發者共同研發,分別是Jiashi Li、Chengqi Deng和DeepSeek創始人梁文鋒,這也印證了外界的普遍說法——梁文鋒作為DS的創始人&老闆始終都在第一線親自參與研發。

梁文鋒主導算法框架設計,Jiashi Li、Chengqi Deng分別負責通信優化與調度策略實現,其中Jiashi Li應該是從字節跳動跳槽到DS的,Chengqi Deng畢業於浙大和梁文鋒是校友,Deng深度參與了DeepSeek幾乎所有的項目,DualPipe最早出現在DeepSeek-V3項目中,之前放出了論文,這次是附上了完整代碼,主要用來優化MoE模型的並行計算,減少訓練中的GPU空閒等待時間。
第一個項目DualPipe,是雙向流水線並行計算;第二個項目EPLB專門針對V3和R1打造的MoE專家模型並行負載平衡器,通過動態分配模型中的負載,來提升MoE模型中GPU利用率;第三個項目Profile-Data提供性能分析數據集,用來優化計算與通信的重疊效率。直接去讀這些專業名詞可能會特別懵,接下來我們還是一步步去了解這三個工具到底是什麼、能有什麼用、DeepSeek的創新

點在哪裡。
02 DualPipe:什麼是雙向並行計算?
DualPipe這個詞拆解是Dual-Pipe兩部分,前面Dual大家應該很熟悉,索尼手柄就叫Dual-Sense,Dual前綴指“雙”,Pipe全稱為Pipeline,UNIX/Linux操作系統中的Pipe是進程間單向通信機制,而大模型領域這個詞不太好翻譯中文,大致有流程、管道、流水線這幾種說法,不過為了不引發歧義還是直接使用Pipeline更準確,Pipeline本身是一個貫穿數據處理、模型訓練到應用部署的系統化工作流。

Pipeline核心在於把一個複雜任務(比如訓練模型)拆成一串有序步驟,讓數據像水一樣流過去,每一步都有人(GPU)接手幹活。隨著大模型能力提升,傳統多步驟Pipeline逐漸被端到端簡化,DeepSeek的DualPipe可以翻譯為雙向Pipeline並行計算,傳統的Pipeline訓練採用單向數據傳遞,比如前向計算從首節點到末節點、反向傳播再反向傳遞,GPU經常得等著前一步計算完才能幹活,效率最多到60%-70%。
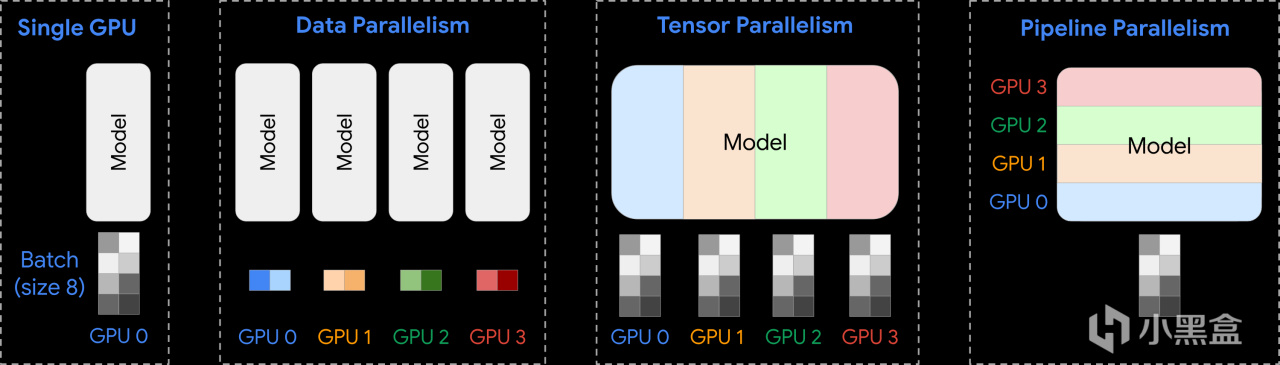
常見的並行策略
比如訓練DeepSeek-V3大模型,神經網絡層數很多,數據得從第一層算到最後一層(前向計算),然後根據誤差從後往前更新權重(反向計算),通俗來說就是一條單行道,前向是數據從頭走到尾,GPU 1 算完傳給 GPU 2,GPU 2 算完傳給 GPU 3,依次下去,反向是誤差從尾巴傳回開頭,更新模型。
問題出在這條單行道效率不高,GPU 們得排隊幹活,前一個沒算完,後一個只能乾瞪眼,比如 GPU 1 在忙著前向計算時,GPU 2 到 GPU N 可能啥也沒幹,等著數據過來。這種等待時間叫“氣泡”(bubble),浪費了不少算力。而DualPipe就是要把這條單行道改成“雙車道”,允許前向和反向計算同時雙向推進,讓車流(計算任務)雙向跑起來,形成對稱的“雙車道”Pipeline。
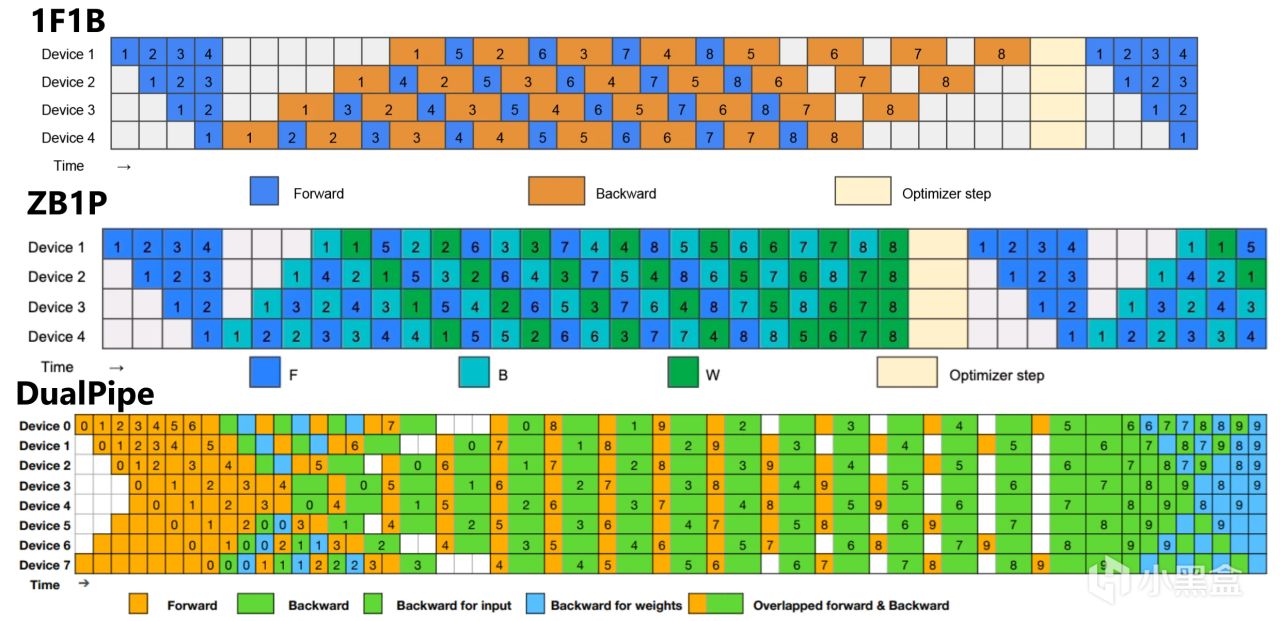
1F1B、ZB1P和DualPipe
簡單來說就是數據往前算結果的時候,誤差已經開始往回更新權重了,對於英偉達的芯片來說,就是 GPU 1 在算第一層的前向時,GPU N 可能已經在用上一輪的結果算反向了,而DualPipe光雙向跑還不夠,還可以把通信(GPU 間傳數據)和計算疊在一起,比如GPU 1 在算前向時,順手就把中間結果傳給 GPU 2,傳完接著算下一塊,不用停工,這種設計就是上面說的“計算通信重疊”,直接把每臺 GPU 的利用率拉到極致。這些通俗的語言相信大家應該能夠看懂,後面幾天我還會結合一些簡單代碼給大家做進階介紹。
03 EPLB:什麼是專家並行負載均衡器?
EPLB全稱專家並行負載均衡器(Expert Parallelism Load Balancer),Expert Parallelism專家並行這幾天我介紹過很多次了,就是DeepEP中的EP,專為混合專家模型(Mixture of Experts,簡稱 MoE)設計,MoE 是一種特別聰明的大模型結構,像 DeepSeek-V3/R1 都是站在MoE肩膀上的大模型,MoE有很多“專家”(expert),每個專家其實就是一個小的神經網絡模塊,擅長幹不同的事。
這種設計很牛,因為不像傳統模型全都一股腦算,MoE 只用一部分專家幹活,效率高、參數多還能省算力。但問題也來了:專家多了,怎麼分配任務就成了大麻煩。想象一下,你開了一家餐廳,有十個廚師(專家),每個廚師擅長不同的菜。客人點單來了,你得決定誰去做這道菜。如果分配不好,可能有的廚師忙得滿頭大汗,有的閒得摳腳,放在GPU集群上解釋,每個 GPU 可能負責幾個專家。如果任務沒分均勻,有的 GPU 超載,有的閒著,整體算力利用率可能只有 50%-60%,浪費很嚴重。

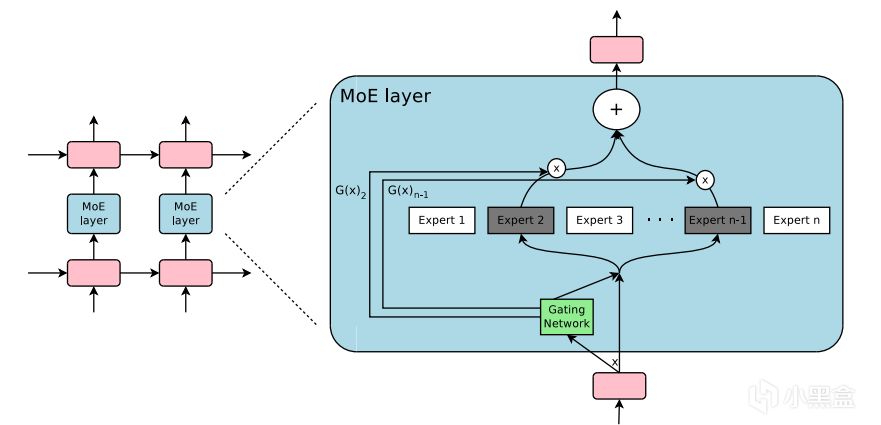
這時候就需要一個“管家”來管管這些專家,把活兒分得公平又高效,DeepSeek的EPLB就是這個管家,負責給每個專家均衡分擔負載任務,後面的負載均衡器(Load Balancer)取名也是相當形象。首先EPLB會實時看著每個廚師專家的訂單量(實時性能數據),然後再進行動態調整,把一部分任務從專家 A 挪到專家 B 那邊(即時調度),保證大家的工作量差不多,最終目標就是人人有活幹人人勞動量都差不多,DeepSeek實測用了EPLB後,一個萬卡集群的 GPU 利用率能到 92% 以上,資源浪費幾乎被幹掉。
04 DeepSeek的數據集是幹什麼的?
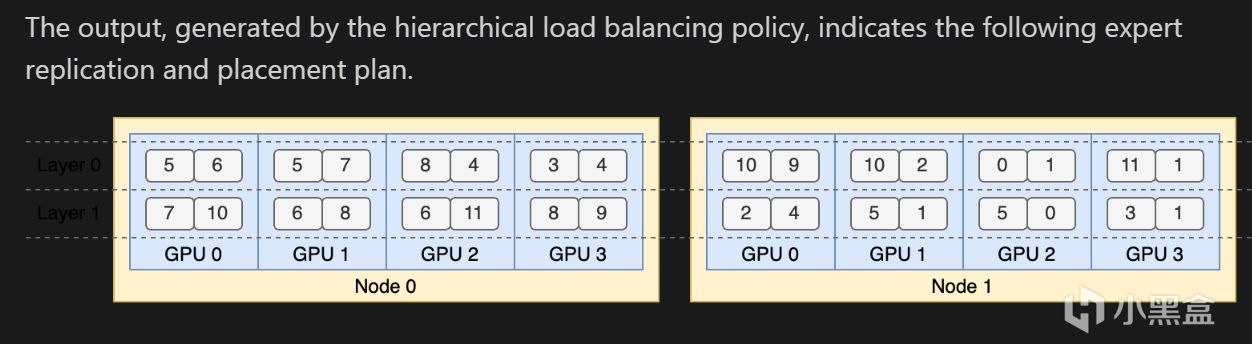
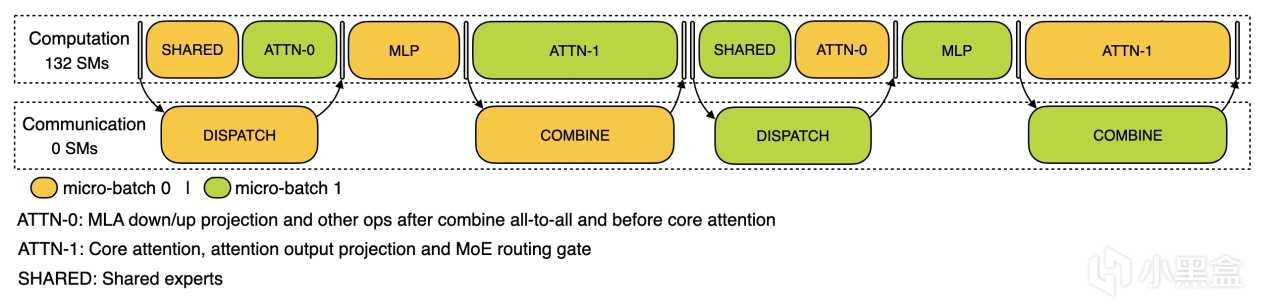
最後一個 profile-data 數據集,主要用來對訓練、推理框架進行性能剖析。傳統數據集是用來喂大模型的,這個數據集你可以理解為DeepSeek怕大家看不懂他在做什麼,專門發佈一個可視化工具,幫助社區更好理解上面DualPipe通信計算重疊策略。這個工具也是 DeepSeek 團隊在訓練和跑 DeepSeek-V3、R1 模型時的實用工具。

訓練階段
比如在訓練階段,模型計算用了多久,通信(GPU 之間傳數據)花了多少時間,都被可視化出來,推理階段,模型回答問題時,分成“預填充”(prefill,準備上下文)和“解碼”(decode,生成答案)兩個步驟,哪個快哪個慢也被可視化出來。profile-data類似於模型訓練推理時候的透視顯微鏡,讓開發者看清楚模型跑起來的每一個細節,方便調優。
解碼階段
05 DeepSeek是如何創新的?
大家每日嘲笑OpenAI是ClosedAI,因為他們技術藏得深,成果秀得多,PPT花式展示,天價廣告打到了超級碗中場秀,但唯獨怎麼做到的往往是個黑箱,社區只能猜。而DeepSeek給大家完整展示了他們是如何取得領先的,秘訣只有一點——實事求是,務實。
今天的DualPipe、EPLB和profile-data三個代碼庫,我給大家揉碎了掰開講,技術層面都非常枯燥,沒整花哨的噱頭,而是盯著問題下手,實打實地解決問題,你看完一整篇解讀文章,可能也不如營銷號給你提供的情緒價值高,但就是這些工具造就了DeepSeek——
先把問題想明白,然後根據不同的問題去對原有的輪子進行改造去創新,一步步積累產生質變。我這幾天講的很多技術其實也不是憑空造新輪子,而是找到大模型訓練的硬傷,然後在現有技術上“修修補補”,最後修出質變。美國人確實非常擅長造勢,DeepSeek給人感覺完全不玩這套,就埋頭苦幹,把訓練的“髒活累活”幹漂亮了,這次開源有論文有代碼,DS團隊還在社區給大家做QA解答,數據都擺桌上了,沒一點神秘感,接下來就是靜靜等待明天開源周的最後一天,期待DeepSeek的新項目!
