本演講為天美團隊於 2023 年 GDC 進行的非贊助核心演講(Core Concept)“千人同屏戰鬥:Unity DOTS在《重返帝國》中的應用”
分享的圖文版內容。
- GDC演講時間:北京時間3月24日週五6am-6:30am
- GDC演講官方主頁傳送門
- 演講內容中文簡介傳送門
演講者簡介
肖健(騰訊天美 T2 工作室客戶端組主程序)
肖健於 2014 年加入騰訊天美工作室群,目前擔任《重返帝國》客戶端組主程序。肖健在遊戲框架、Gameplay 和性能優化等方面都有著豐富的研發經驗。

侯倉健(騰訊天美 T2 工作室引擎負責人)
侯倉健於 2014 年加入騰訊遊戲,曾參與多款手遊的研究與開發工作。侯倉健於 2019 年加入騰訊天美工作室群《重返帝國》團隊,目前主要負責遊戲引擎和工具鏈的開發工作。

演講正文
《重返帝國》手遊畫面實錄
《重返帝國》是一款高品質全 3D SLG 手機遊戲,遊戲場景規模宏大,玩家操作自由多變,畫面上經常會出現超過1000個士兵一起戰鬥的場景。在有限的移動設備性能上,需要同時兼顧性能與品質,團隊在嘗試過C#、C++以及DOTS等多種技術方案的選型與研究後,最終選擇了Unity DOTS。
Unity DOTS對於團隊可以說是一次敢為人先的選擇,當時市面上並沒有比較知名的使用這項技術的遊戲項目,所以這項技術最後呈現出來的效果其實是沒有太多參考的。其次,當時DOTS是處於一個比較初期的版本,Unity官方還在不停的修改和完善,這意味著團隊享受不到新的features,甚至可能需要處理一些潛在的隱患,這對團隊來說是不小的挑戰。
實戰分享
團隊一方面與Unity官方保持密切的合作與交流,另一方面經過多次的技術迭代與優化,最終在《重返帝國》項目上取得了很好的實踐效果,在移動設備上為玩家呈現了極高品質的視覺效果。同時團隊也積累了一套行之有效的方法論,以下總結了幾點分享給大家。
- Job數據依賴分析與優化,提升整個系統的併發性
- 將部分ECS System的Job與非ECS邏輯並行,充分發揮多核
- 邏輯數據顯示分離,提升chunk內存利用率,減少資源加載帶來的卡頓
- 針對System進行邏輯降頻,保證效果同時也提升性能
當我們完成了整體的框架設計和核心的實現後,在進行性能分析的時候發現Job的併發性並不高,且worker存在大量的idle狀態,導致系統的整體耗時偏高。為此,我們專門開發了靜態分析工具輔助我們找出System之間的讀寫衝突與依賴,通過數據拆分、數據備份來解決衝突,讓耗時較高的Job能夠並行。
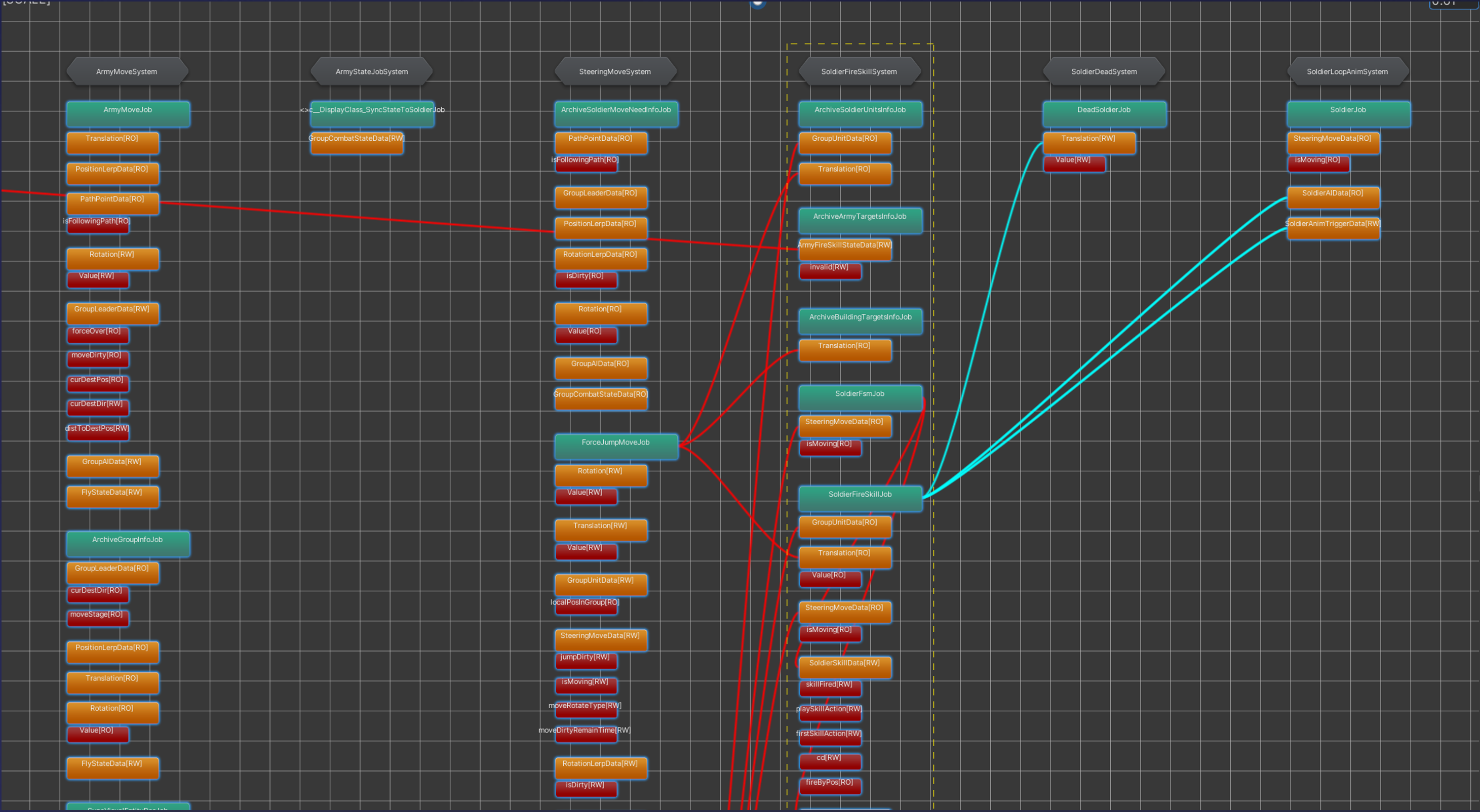
數據依賴靜態分析工具
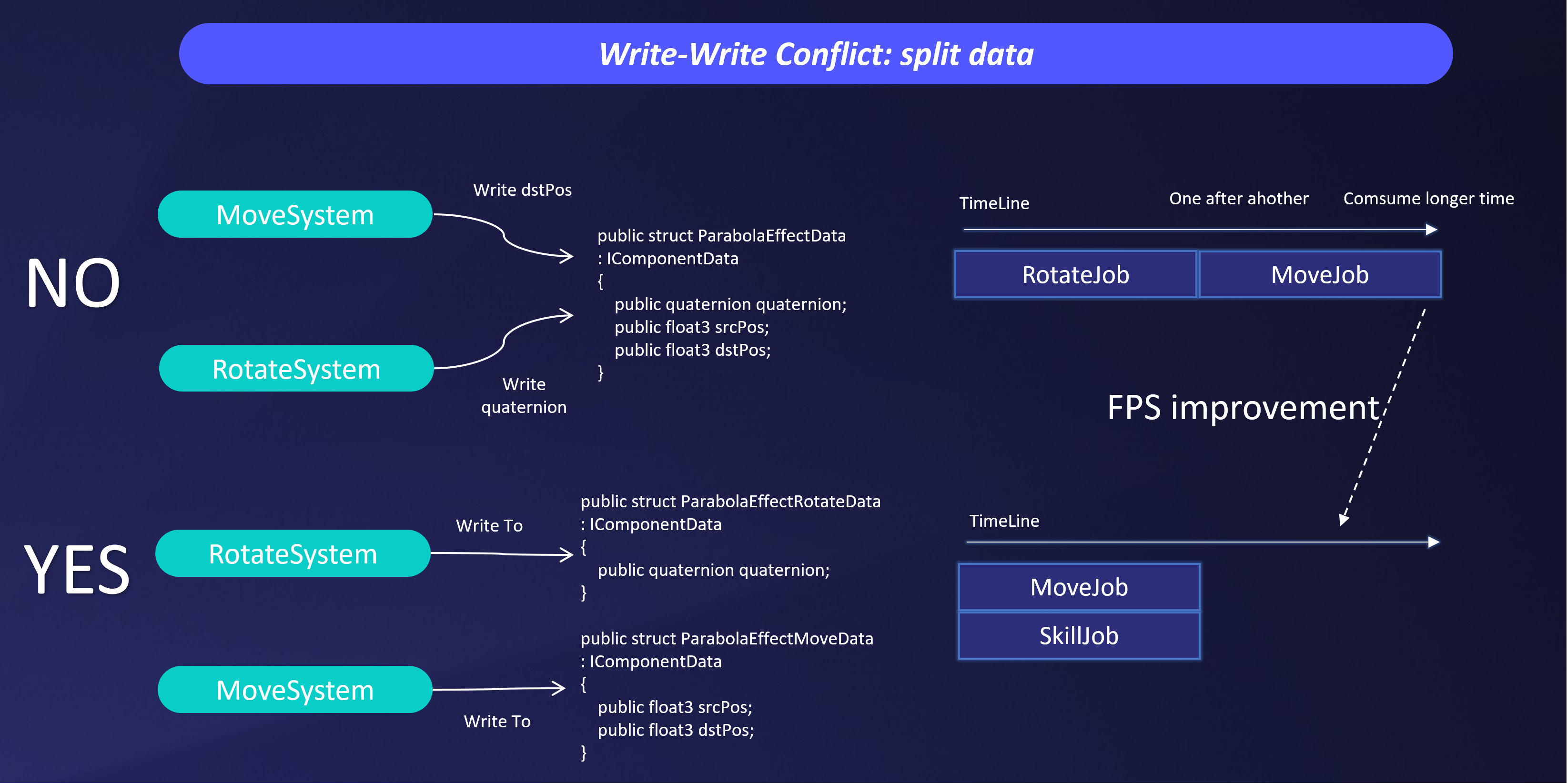
數據拆分解決寫入衝突
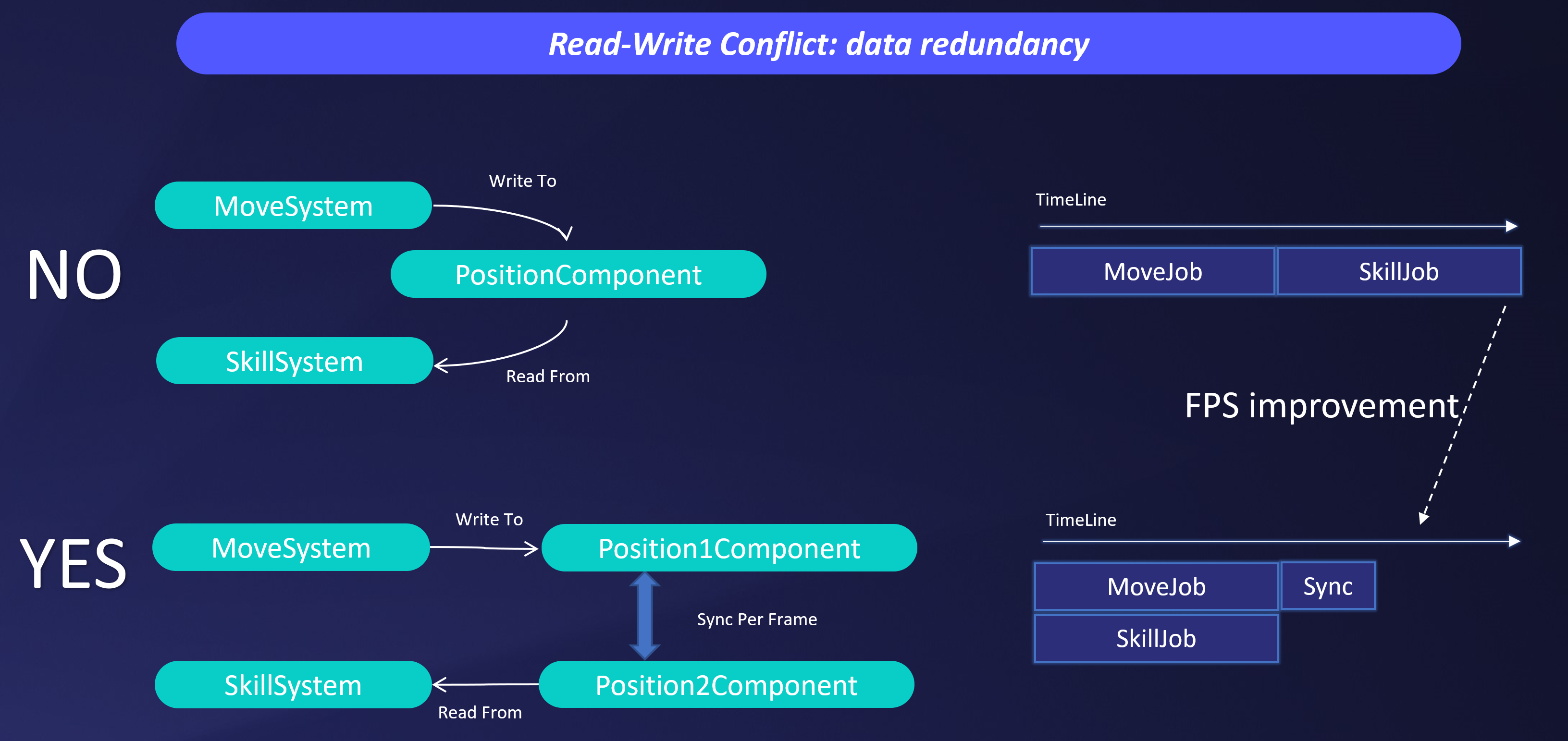
數據備份解決讀寫衝突
基於工具的分析,我們不斷的細化和調整,解決了數據的衝突依賴,顯著提高了Job的併發性,最終達到了我們相對滿意的並行效果。

數據依賴優化後Job的併發執行
之後,我們還將System按照功能進一步的細化拆分,把一部分Job的執行提前到與非ECS代碼邏輯並行,進一步從整體上提高了我們的遊戲幀率。
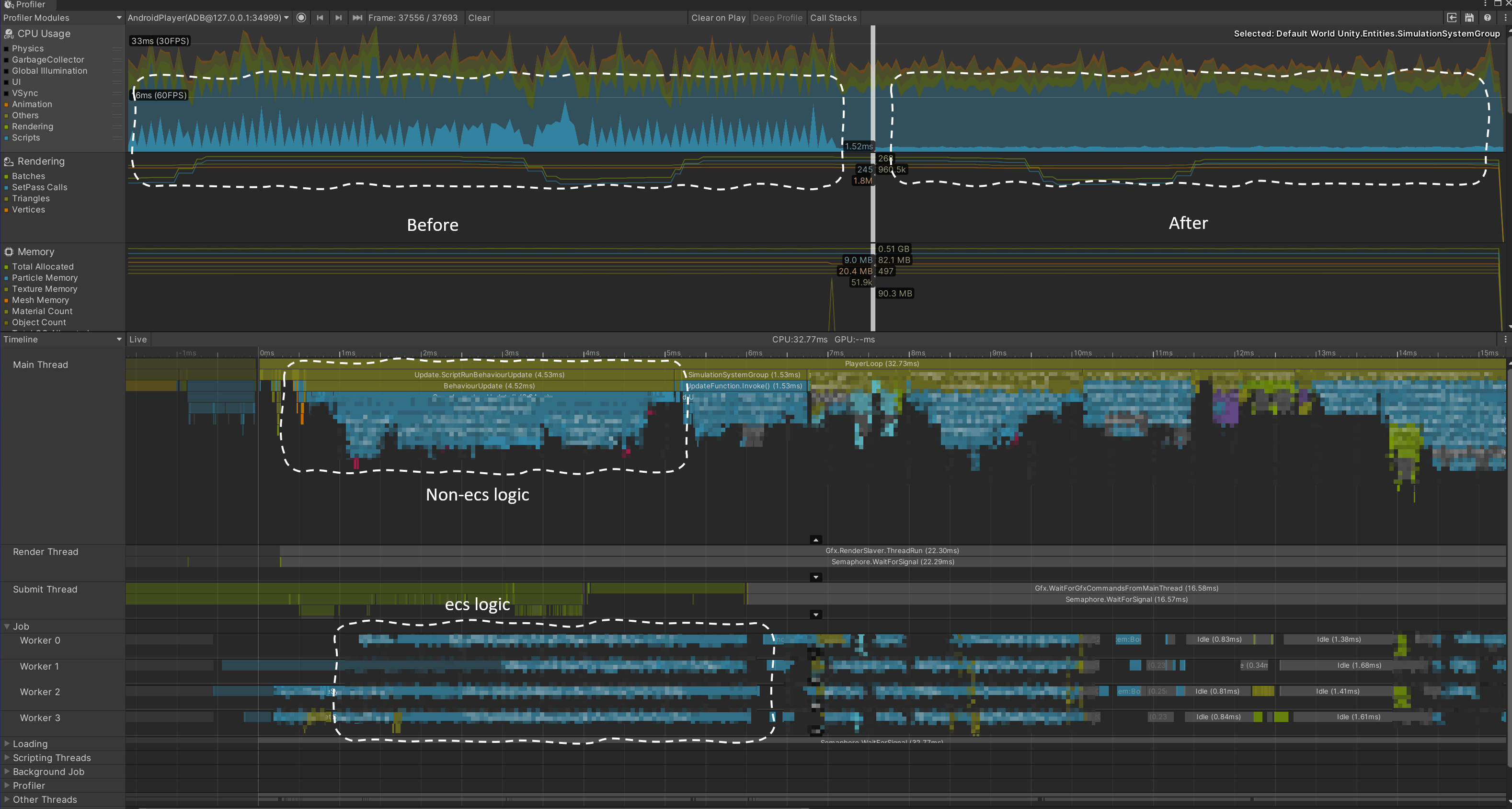
ECS Job與非ECS邏輯並行
在進行了Job並行性優化之後,我們發現在大地圖上拖動時存在由於Entity資源同步加載導致的一些耗時峰刺,這對玩家來說是體驗上的損失。所以我們針對Entity,使用邏輯與顯示分離,一方面讓資源可以異步加載減少卡頓,另一方面也提升了單個chunk的內存利用率減少CPU的cache missing。
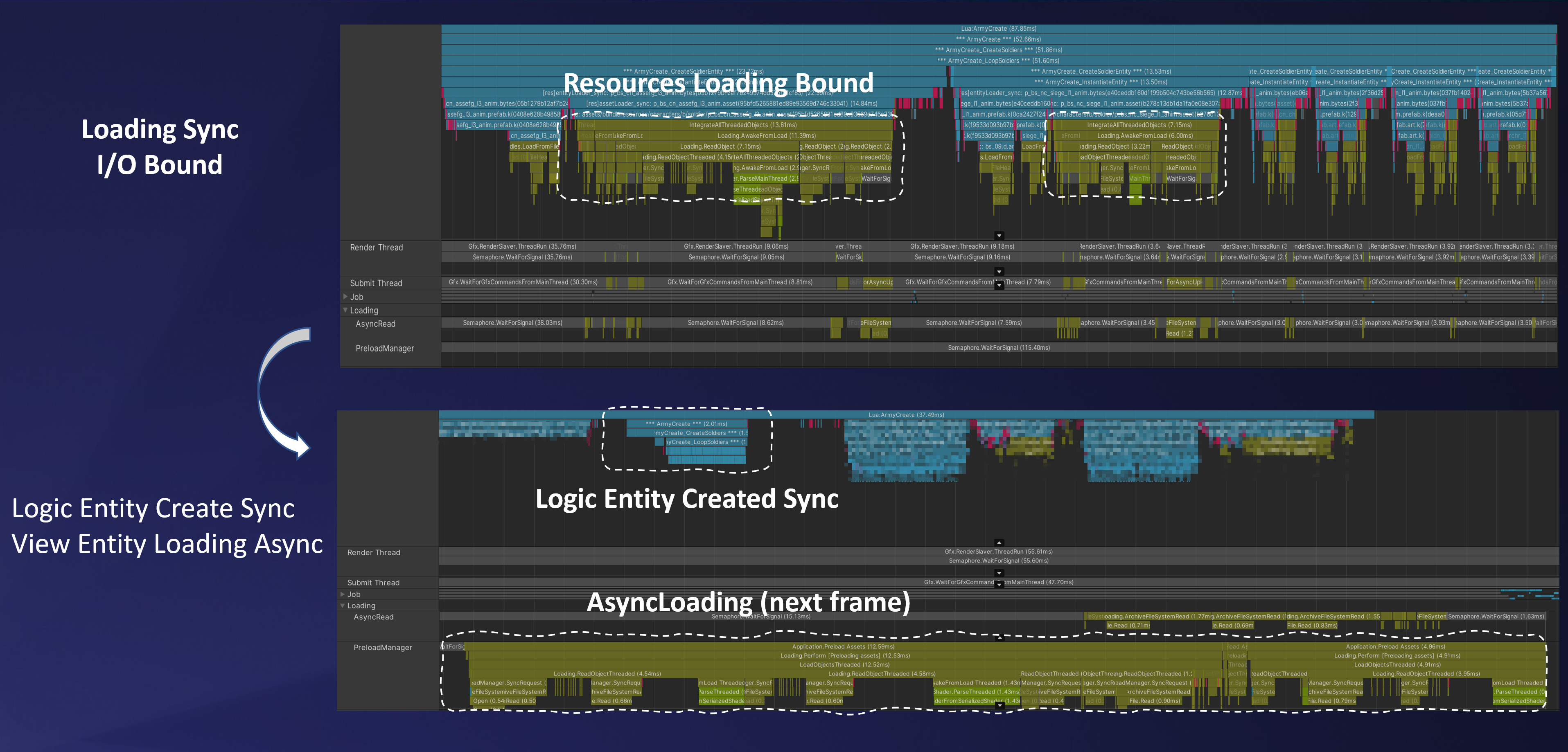
邏輯顯示分離-資源異步加載
最後,我們在不影響效果的前提下,針對部分System進行邏輯降頻與錯幀(如移動邏輯計算相關的System降到12幀、耗時較高的MoveJob與AnimatorJob錯幀執行),讓整體的耗時更加平滑,並且有效的降低了遊戲的功耗。
性能優化
當時我們使用的是 Unity2019版本,Hybrid Render V1 版本,為了能更順利的將DOTS適配到我們的項目中,我們也在原始框架的基礎上,在資產與渲染方面也進行了大量的按需開發。
我們在接入 DOTS 技術棧時,主要面臨了以下3個問題:
- 資源兼容性:因為在接入時已經處於項目中期,很多遊戲資產及對應的生產流水線已經成型,所以如何將已有遊戲資產轉變成可在 DOTS 技術棧中運行的資產,是我們需要解決的問題。
- 邏輯階段的基礎開銷過大:可能會導致千人同屏場景出現時出現卡頓。
- 渲染階段無法修改自定義的材質屬性:因為我們對於戰鬥場景的還原重度依賴 GPU Instancing 技術,所以需要很多自定義的材質屬性可以在運行時被複寫。
於是,我們針對以上問題逐個研究核心痛點,找到了適合我們項目的解決方案。
在資源兼容性方面,在綜合評估了各種方案之後,我們決定實現一套自己的序列化和反序列化流程。我們的方案分為離線和運行時兩個階段:離線時,我們將遊戲中各類資產對應的prefab拆分成二進制文件和引用到的資源文件;運行時,我們創建了一個“deserialize world”,用來把離線時生成的二進制文件和資源文件反序列化,生成entity。當entity生成好後,我們再把它們移入default world進行運行。這樣我們既可以在資產製作階段使用我們熟悉的prefab,也可以減少運行時的轉換時間。
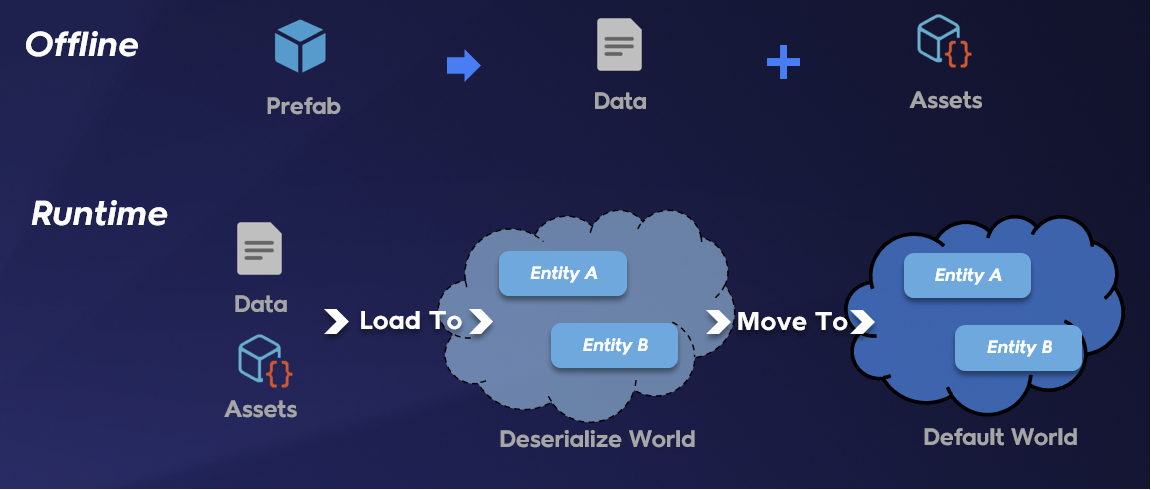
資產Entity實例化
對於HybridRenderV1在邏輯階段的開銷過大,我們定位到了核心的瓶頸是主線程阻塞。比如整個生成合批信息的過程都是放在主線程中進行的,這個過程有很大的優化空間。
我們的優化方向就是多線程化,充分利用移動端的多核優勢。其實在生成合批信息時,不同的RenderMesh一定對應不同的batch,任務本身具有可多線程化的特性。所以如下圖所示,我們分配了一個較大的緩存數組,數組的大小與線程數量和RenderMesh數量相關。多個線程並行完成對含有RenderMesh的Chunk進行篩選,並填入緩存數組的指定位置。因為在緩存數組中,每個線程都有自己的寫入空間,所以多線程並行時,不會產生數據寫入衝突。
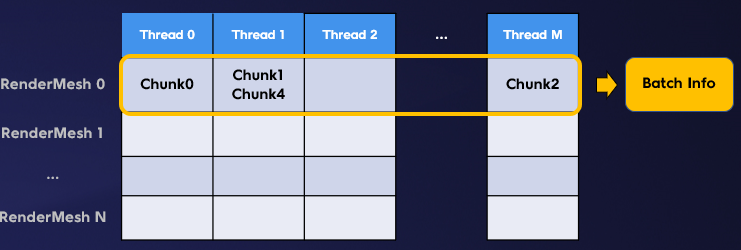
多線程RenderMesh Batch
我們還對遊戲中LOD的結構進行了優化。我們遊戲中的模型一般有4層LOD,在轉換成entity後,將會有6個相關的entities生成。
過多的entity不僅浪費內存,同時也會導致很多冗餘計算(比如同步位置信息),而根據LOD的特點,我們可以只記錄單個LOD的信息,在渲染時按需替換成應當顯示的LOD Mesh即可,這樣我們就可以把原本的4個LOD網格當做一個單獨的網格來對待。同時,我們也將LOD Group節點和Root節點進行了合併,Entity的數量也從原來的6個下降到2個,性能也有了提升。
這種方式帶來的一個額外好處是當我們更高層級的LOD還未加載完成或渲染壓力過大時,我們可以只加載低層級的LOD模型來顯示。
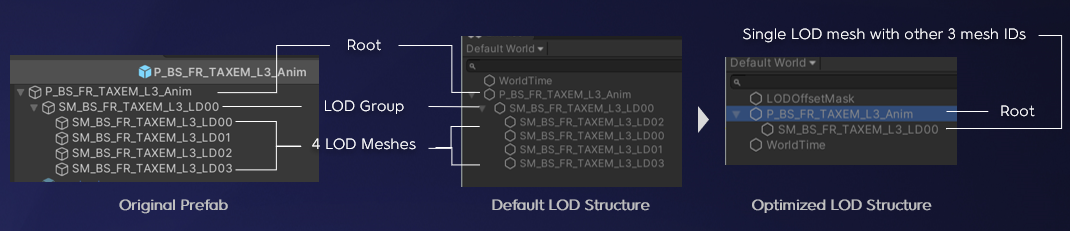
LOD結構優化
為了在C#中更改材質的Instance屬性,我們定義一個和Instance屬性完全匹配的IComponentData Struct,在數據對齊方面,我們遵循std140內存數據對齊原則。如下圖所示:
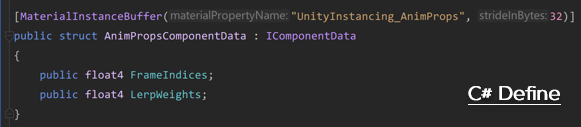
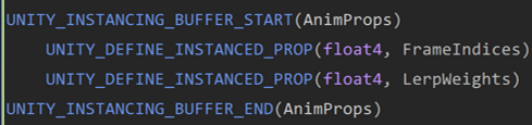
Instance屬性對齊
在渲染運行時,我們根據entities的數量預先分配一塊大的緩存,之後利用多線程把各個可見的entity的InstanceParam數據複製到Buffer中的指定位置。最後將整個緩存直接提交至GPU,我們就可以按照傳統的GPU Instance方式來使用緩存中的數據了。
在有了RenderMesh上的材質信息和mesh數據之後,我們的InstanceBuffer也組織好了,這樣通過調用Unity的DrawMeshInstanced接口就可以進行渲染了。

Instance Data Buffer
以上都是團隊在實踐中不斷迭代總結出來的寶貴經驗,希望能對那些同樣想使用Unity DOTS技術的團隊能有所啟發。