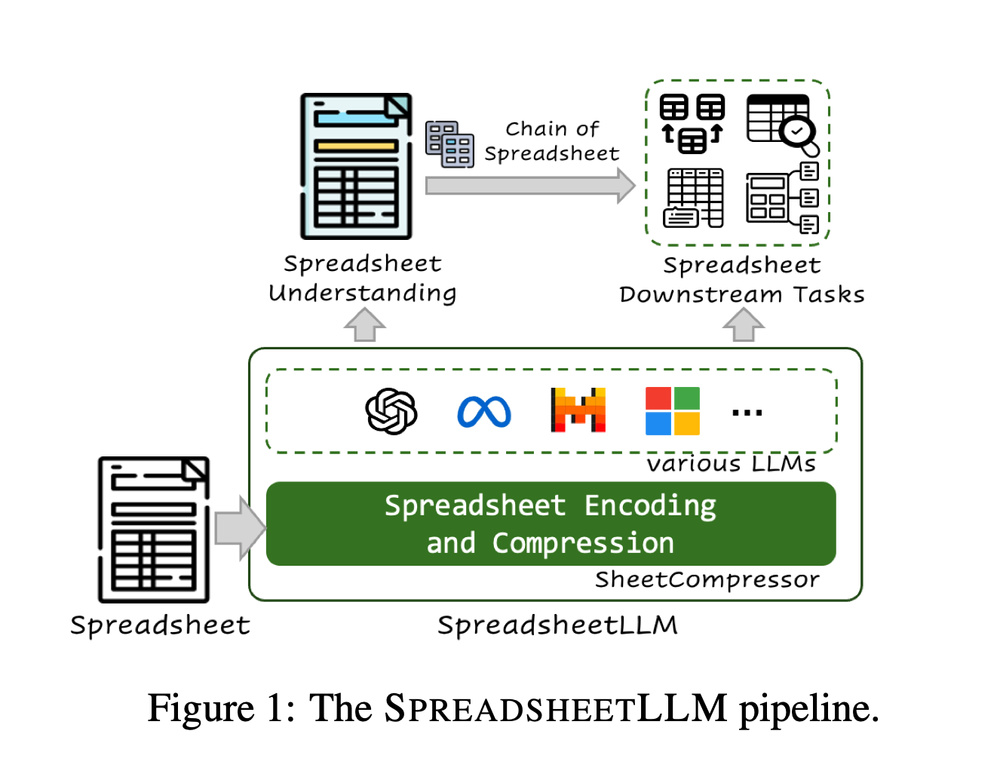
微软发布了一款新型大型语言模型,名为SpreadsheetLLM,专门用于处理电子表格。这款模型在数据管理和分析方面展现出卓越的性能,有望颠覆现有的数据处理方式,提升用户交互的智能化和效率。

这款新模型解决了传统大型语言模型在处理具有复杂二维网格结构、灵活布局和多样格式选项的电子表格时遇到的挑战。微软团队开发了名为SheetCompressor的创新编码框架,有效地压缩电子表格,使得模型在表格检测任务中的性能比传统方法在GPT4的上下文学习设置中提升了25.6%。
SpreadsheetLLM包含三个主要模块:基于结构锚点的压缩、反向索引转换和数据格式感知聚合。通过在电子表格中设置结构锚点,模型能更准确地理解表格内容,并通过移除距离较远的同质行列,生成精简的表格骨架版本。索引转换通过采用JSON格式的无损反向索引转换,不仅优化了模型的token使用效率,也保持了数据的完整性。
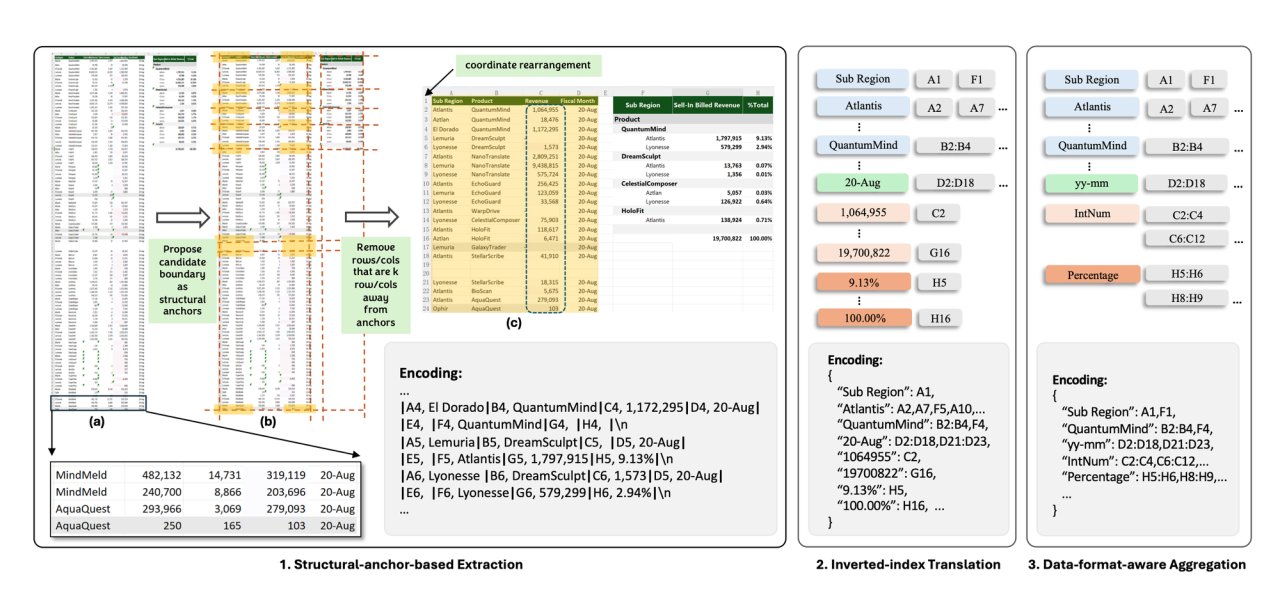
此外,该模型还能有效处理数字格式相似的相邻数值单元格。通过提取数字格式字符串和数据类型,并将相同格式或类型的相邻单元格聚集,简化了对数值数据分布的理解,避免了过多的token消耗。
经过在多种大型语言模型上的全面评估,微软发现SheetCompressor显著减少了电子表格编码所需的token使用量,高达96%。在电子表格检测方面,SpreadsheetLLM表现出色,显示了其在电子表格理解的基础任务上的优异性能。
这一新型大型语言模型基于“Chain of Thought”方法论,引入了名为“Chain of Spreadsheet”(CoS)的框架,能够将电子表格推理分解为表格检测、匹配和推理的流程。这一框架的扩展展示了其在电子表格下游任务中的广泛适用性和潜力,有望改变电子表格数据管理和分析的方式,为用户提供更智能、更高效的交互体验。
SpreadsheetLLM的发布预示着大型语言模型在未来可能在处理结构化和非结构化电子表格数据方面发挥重要作用,对财务预测、财务分析和估值等多个应用场景具有广泛的应用前景。