DeepSeek 的熱度,終究還是被車圈蹭上了。
就在這幾天,當我們還在跟 DeepSeek 互噴服務器繁忙的時候, N 個國內的車企就跟商量好了似的,先是嵐圖,後是極氪,緊接著就是智己、寶駿和
之後甚至人傳人到了斑馬智行和億咖通這些做車機的企業,都一個接一個的表示,自家的產品已經和 DeepSeek 最新的 R1 模型合體了。

而就在脖子哥寫稿的時候,這個名單還在變長。
不知道大夥咋想啊,反正我在看到這些消息的時候,腦子裡就是一連串的問號:
把 DeepSeek 用在車上有啥意義?他們說的深度融合到底是個啥形式?車載版本的 DeepSeek 和網頁版又有啥區別?
當然最重要的靈魂拷問是,這些車企們,到底是不是只是為了營銷的熱度在硬蹭 DeepSeek ?
你別說,在狠狠研究了一番以後哥們已經有結論了。說人話就是, DeepSeek 的成功對汽車行業確實有用,但壓根不是上頭這些車企這麼用的。
至於為啥,我們慢慢來看。
首先第一個問題,車企們是怎麼把 DeepSeek 放到車上的?
可以肯定的是,大家都沒有選擇在車機裡裝 app 這種最直給的方式。因為從各路新聞稿裡可以看到,大家都提到了 DeepSeek-R1 模型和自有模型在底層算法上的融合,部份品牌還提到了模型蒸餾的技術。


再加上一家名叫思必馳的雲端大模型服務公司,前一陣也官宣了自己在雲端模型裡融合了 DeepSeek 模型,給像是長城、比亞迪這樣的車企提供雲端 AI 助手的支持。

基本可以確定目前上車的 DeepSeek-R1 ,大概率會是以下兩種形式之一:
一是通過 DeepSeek 的 MIT 開源協議,在自家的服務器上佈置滿血版或是蒸餾後的 R1 模型,然後通過微調融合,和自家原有的模型變成一整個大模型。車主呢,則是通過車機聯網來使用這個大模型的交流功能。
第二種則是通過蒸餾的方式,把 R1壓縮成一個體積非常小的小模型然後更新到車端,讓車主就算不聯網,也能用上 DeepSeek 的一部分功能。

這兩種方式說到底,就是給這些車上原本的 AI 模型上了一個 DeepSeek 的 buff ,讓它擁有一部分 R1 的能力。
那這些模型是用來幹啥的呢?其實。。。就是能讓語音助手說起話來更有人味而已。
是不是覺得有點無聊,是的,因為類似的功能已經在很多新勢力車型上實現了。
比如之前很火理想 MindGPT 和蔚來的 NomiGPT ,對話溝通啥的不僅比傳統的語音助手更流暢,一些比較抽象的問題,比如 “ 鑿壁偷光需要判幾年 ” 這種弱智吧問題,能答上來的概率也能相對高點。
但要我說啊,這種用法壓根就沒發揮出 DeepSeek-R1 模型的能力,改善用車體驗啥的就更別指望了。
你問為啥?
要知道, DeepSeek 的 R1 模型之所以產生了這麼大的轟動,開源是一方面,最重要的還是它在訓練的時候,很 big 膽的使用了強化學習 + 獎勵模型的方式,最終湧現出了超強的推理能力,非常適合解決困難的邏輯問題。
打個比方啊,高中班裡有倆同學 A 和 B ,面對同一道數學題, A 的做法是循規蹈矩的用各種公式,一步步按部就班的解題。而 B 則是管你公式這那的,自己靠著之前做過的超多題目,自己摸索出一個解法。
而這個解法,很有可能就會比硬套公式來的高效的多。就跟咱們學了高等數學再回去做高中的題似的,直接就秒了。
久而久之,相比死記公式的 A , B 同學就更能理解問題和答案之間的邏輯關係,在面對沒見過的複雜問題,比如巨難的數學和編程問題的時候,也能更快、更準確的推理出正確的答案。
而這個 B 對應的,其實就是 DeepSeek-R1 的純強化學習的訓練模式。
不需要像以往的監管學習一樣一直用規則來微調和修正,只靠著做對了就獎勵,讓 AI自己領悟推導過程。

這時候再回到車上的語音助手,問題就來了,因為咱們壓根不會問它什麼太複雜的問題,頂多就是問問天氣放放歌啥的。
這些功能就算不是 DeepSeek 這種級別的大語言模型,其實也都能解決的七七八八。只要你不是開車開一半突然就問語音助手:

那在體驗上大概率就不會和現有的車載大模型有太大的差別。
再加上經過蒸餾和融合之後的小模型,能力對比滿血版有著不小的閹割,對於自己本來就有自己的大模型的車企來說,再加一個 DeepSeek 著實沒啥必要。
所以啊,那些著急喊出 DeepSeek 口號的車企們,我的評價是熱點麼肯定是想蹭的,DeepSeek 上車的實際效果,肯定也遠沒有宣傳裡那麼邪乎,大夥可以坐下了。

當然,如果車企本來在座艙 AI 上有短板,能靠著開源的 DeepSeek-R1 做做查缺補漏,讓自家的模型追上一線新勢力的水平,確實也不是什麼壞事。
可就像我開頭說的, DeepSeek 如果只是拿來做語音助手的話,那屬實是有點浪費了。畢竟它更大的潛力,其實是在智能駕駛上。
就這麼說吧,甭管是很火的端到端還是規則算法,如果能更多的用上 DeepSeek 的強化學習模式,或許就能讓能力往上提高一大截。
真不是我吹啊,大夥還記得前頭做題的同學 A 和 B 麼,其實類似的道理在智能駕駛上也同樣成立。
現在幾乎所有的主流智能駕駛其實就是那個循規蹈矩的同學 A ,在訓練模型的時候都是模仿學習為主。模仿嘛,顧名思義就是讓智駕算法能跟專家的行為示範對應,也就是模仿人類開車。
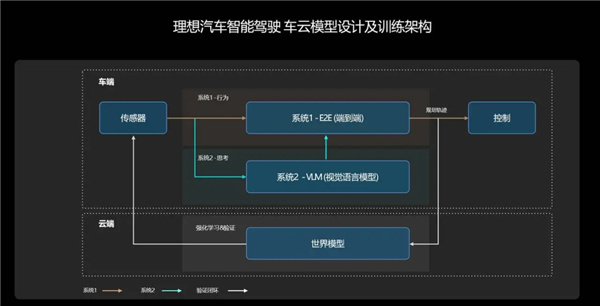
比如特斯拉、比亞迪和華為,就都會從駕駛評分比較高的車主那收集駕駛數據,比如攝像頭拍的視頻餵給算法,研究車主們怎麼從 A 點開到 B 點,再進行一個模仿。
很明顯,這種思路到頭來訓練出的就是跟人類開車水平持平的智駕。但強化學習則完全不同,因為它學習的不是駕駛的過程,而是通過不斷的試錯,領悟出從 A 點開到 B 點最高效的路線。
而這個領悟的上限,可不就只是能讓智駕開得像人了。
要知道智駕系統對於環境的感知能力,其實比我們人類司機強很多。當我們過路口的時候還在東張西望看前後左右有沒有障礙物的時候,智駕通過車上各種的攝像頭和雷達只要一瞬間就能看個大概。
當我們只能單線程的先觀察、後打燈、再變道的時候,智駕也能在同一時間用一個操作搞定。
理論上,只要學習和領悟到位,智駕就能推理、總結出許多比人類司機效率更高、更能利用好各種車輛性能的駕駛方式。很多咱們覺得很難、用模仿學習咋學都學不會的小眾場景,強化學習可能分分鐘就能搞定。
都說現在的智駕是剛拿駕照司機的水平,用上強化學習之後,指不定真就會變成有了十幾年駕齡的超絕老司機。
當然了,理論終究是理論,想要在智駕訓練裡大規模的用上強化學習,依舊有不少難點和瓶頸。
就比如,強化學習的試錯過程需要巨大的算力資源,對於國內很多需要租算力做智駕的企業來說其實不太能搞得定。
再比如強化學習很容易出現的幻覺問題,咱們有時候在用滿血 DeepSeek 的時候會經常發現它擱那胡言亂語,本質上就是因為強化學習學的有些魔怔了,開始湧現出一些不符合事實的內容。
智駕算法也是如此,如果獎勵和微調的機制沒有設計到位,就很有可能幻想出 “ 需要開到天上 ” 的開法。
就算不出現幻覺,也可能出現急加速、猛剎車這種賽道開法。效率是高了,但誰的脖子和腰頂得住啊?這就需要車企花費很多精力設計獎勵模型,並且通過一些微調措施來限制 AI 的發揮,這就非常考驗主機廠的算法能力了。
即使是賊早開始做智駕的特斯拉,也只有在非常少的公開資料裡表示自己有在部分模塊裡有限的使用了強化學習。
可見難度是實打實的,而且還不小。

但我覺得啊,想要真正讓智駕的能力再上一層樓,多用強化學習肯定是各家未來的大方向。把強化學習的成果做到大規模的落地,未來可能也是繼把智駕做到白菜價之外,各家車企和供應商們 battle 的下一個戰場。
這不比做語音助手啥的有意思多了嘛。
文章來源: 快科技-汽車頻道