内置数据结构 table
很多语言都会设计一种通用数据结构,最常见的是数组。对于 C 语言来说,使用数组及其工具指针,可以构造出非常多其他种类的数据结构,譬如链表、二叉树、哈希表等等。而 PHP 则自带一种通用的数据结构,也叫数组,但实际上是一种通用的哈希表。一个自带内存管理的 key-value 类型的数据结构,其实可以解决非常多的编程实际问题。所以 Lua 也提供了这种能力,就是 table 类型的变量。
灵活的下标
table 类型的变量可以做很多事情,譬如它可以是“数组”:
a = {2, 4, 6, 8} print(a[1], a[2]) --> 显示:2 4
Lua 没有用大括号用来标记代码块,留着用来表示 table 的常量了。上面这个代码记录了一个类似数组或者链表,需要注意的是 Lua 中数组的第一个元素是从 1 开始计算的,所以 a[1] 表示取第一个元素。我们用中括号 [] 来读取 table 的元素,table 不但可以用数字作为下标来读取元素,还可以用其他的值,譬如字符串,这种情况下 table 又类似了“哈希表”:
p = {a=1, b=3, c=9}print(a["b"]) --> 显示:3 p.d = 10 print(p.a) --> 显示:9 print(p["d"]) --> 显示:10
Lua table 如果以字符串作为下标进行初始化,甚至连双引号都不需要;而且能用 . 的写法来代替["xx"]。这种 . 的写法也很类似于其他语言的面向对象语法的“取成员”符号——这也为 Lua 的面向对象特性提供了支持。
Lua 的 table 实际上是一个 key-value 对(pair)的集合,所以我们可以随意的添加任何类型值的 key 和 value “记录”到一个 table 里。
k = {} k[2]="hello" k["haha"]="world" print(k[2],k["haha"]) --> 显示:hello world
遍历 table
虽然 table 可以用下标来赋值和读取内容,但作为一种“key-value 表”,肯定是不够的。Lua 也提供了一批功能更完全的函数,帮我们做更多的事情。我们先来看看如何遍历一个 table,循环语法中的 for 专门为了这个设计了一个写法,以及一个专门的内置函数 pairs():
a={} a[1]="one" a["second"]="two" a[78]="three" a["last"]="four" for k,v in pairs(a) do print(k,v) end
运行结果是:
1 onelast four 78 three second two
用 for k,v in pairs(...) do 的写法,可以很方便的遍历并且提取整个 table 的内容。在早期的一些语言中,没有把 for 和语言常用的数据结构结合,只能通过下标来操作数据结构,代码写起来就非常麻烦。如果要遍历一个哈希表之类的结构,先要获得一个哈希表的“迭代器”对象,然后通过调用迭代器身上的方法(或者迭代函数)才能遍历。由于 table 的下标可以是各种类型的值,所以要简单的获得 table 的记录总数,一般只能通过遍历来计算,而没有什么特别简单的方法。
由于 Lua 中的变量赋值为 nil 就是删除,所以 table 中,对一个下标赋值为 nil 也是删除。由于在 table 中的记录,都是会占用内存的,所以不用的记录一定要及时“删除”,否则就会造成内存泄漏。
列表形 table
虽然 Lua 的 table 下标可以是任何的数据类型,但如果这些下标是从 1 开始的连续数字,我们就能以“列表”(list)的方法来使用 table:
- 用 # 来获得长度。需要特别注意不要用赋值 nil 来删除列表里的元素,否则#的结果是不准确的。
- 用 for i,v in ipairs(...) do 来进行顺序遍历
- 用 table.insert(tb, pos, var) 来追加和插入元素
- 用 table.remove(tb, pos) 来删除元素
- 用 table.sort(tb) 来排序,这个尤其有用,甚至可以用来排序汉字(因为汉字的内码是按拼音顺序设计的)
你可以用上面的函数来操作一个混合着数字 key 和字符串 key 的 table,但是上的函数只会对数字 key 部分生效。所以最好还是只对那些 “只有数字 key,并且从 1 开始” 的 table 使用这些函数。
一点小结
- 符号 # 在其他语言里常常是单行注释符号,Lua 用来作为长度运算符了。
- 符号 // 在其他语言里面也常常是单行注释符号,Lua 用来作为整除运算符了(Lua5.3之后支持)。所以 Lua 用了 -- 作为注释符号。
- Lua 也没有递增 ++ 和递减 -- 运算符。其实这两个运算符在 a = b++ 这种写法下,运行的结果比较反直觉,所以Python 也不支持。
- Lua 的 table 用起来和 PHP 的数组还挺像的,都是挺“万能”的。
面向对象
面向对象曾经是软件业最流行的思潮,很多语言为了跟上这个思潮,都设计了所谓面向对象的语法支持。所有这些语法支持,最核心需要完成的任务有以下几点:
- 封装:就是支持一种叫对象的变量,这个变量是可以同时携带属性值(成员变量)和方法(成员函数)的。开发者不但可以通过对象读写其携带的属性,还可以调用对象所携带的方法。很多语言还设置了类似 this 或者 self 这种关键字,以便在方法中调用携带此方法的对象变量。
- 继承:支持对象的属性和方法定义可以被重用,可以让一类对象的定义,通过继承语法自动带上另外一类对象的定义,从而避免大量的重复而类似的定义。
- 多态:支持多个不同类型(定义)的对象,只要它们都满足其中一种类型定义,就可以“作为”这类对象来使用。这种特性最常用于取代复杂的 switch...case 语法,做法就是为不同类型的对象,都定义同一个名字的方法,这些不同类型的对象,都可以被调用这个相同名字的方法,但执行的代码则会被自动调用那些应该属于那种类型的方法。等于自动以对象的类型为 switch 的选择,每个对象的方法为 case 的代码段。
为了完成上面的几种任务,不同的语言使用了不同的设计。JAVA/C++/C#/Python 这类语言选择的是所谓“对象模板”的方案,其特征就是语言中会有 class 关键字。开发者通过定义各种 class 来设计对象的内容,在运行时通过这些 class 实例化出很多对象来使用。这种做法的好处是,class 的设计非常明确且固定,在复杂的逻辑下比较不容易写错代码。但是缺点是使用这些 class 的时候比较死板和啰嗦,每个对象都必须和他的“模板”一模一样,如果有任何一点不同,就需要定义一个新的 class,如果不仔细设计,很容出现所谓“类爆炸”的情况——一个程序里面定义的 class 实在太多了,导致开发者已经分辨不过来了。这种设计对于“多态”的实现上,尤其复杂,为了让不同“类”的对象能作为同一个类来使用,就必须运行对象同时继承多个类,而同时继承多个类又比较容易出现逻辑冲突,还要设计类似“接口”这种特殊的,专门用于多态的类,总之就是越搞越复杂。
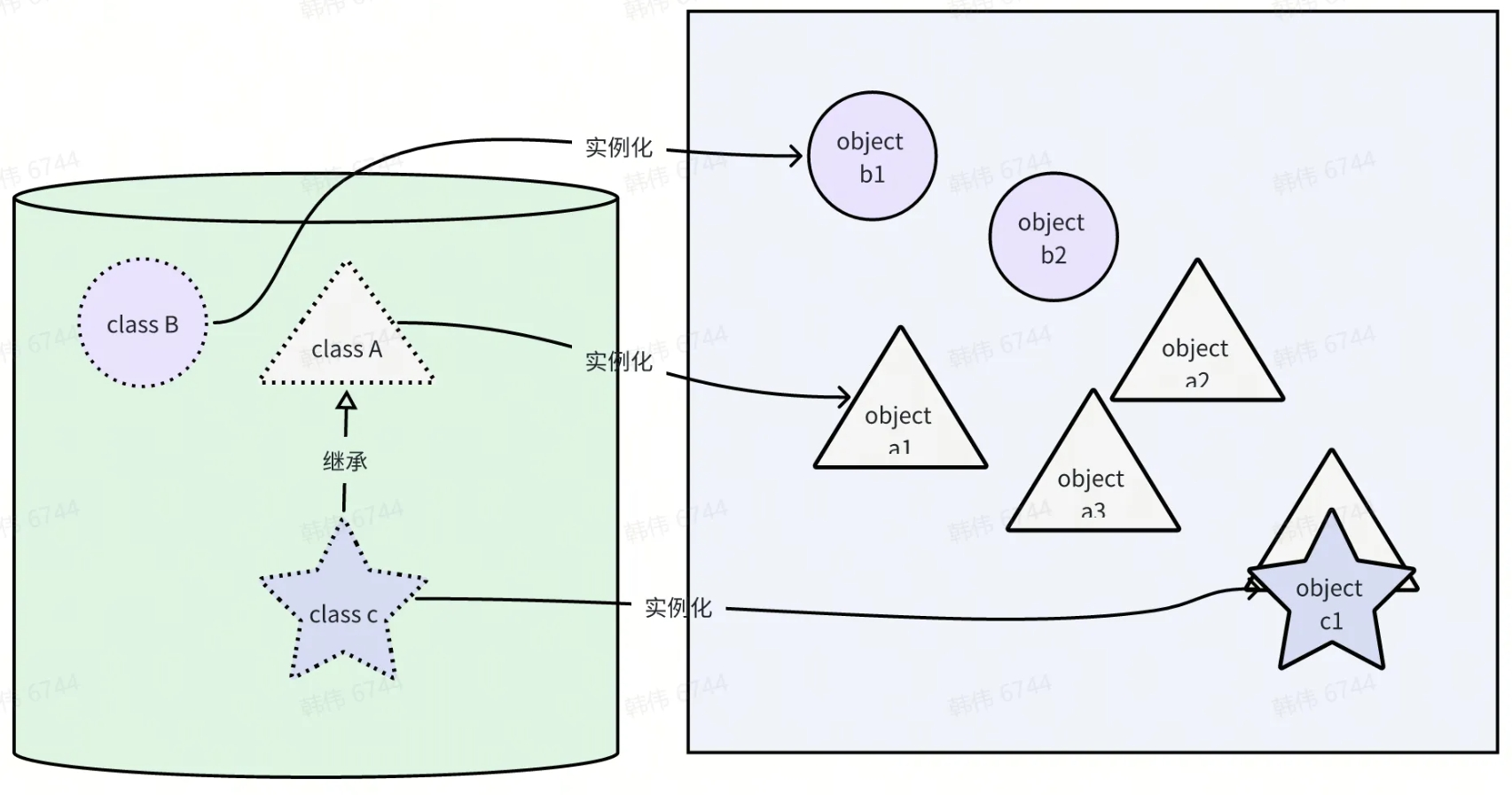
而脚本语言,因为天生就有动态对象的能力,可以在运行时对内存中的对象进行各种修改,所以好像 JavaScript 和 Lua 这种语言,采用了另外一种面向对象语义的实现方法:“原型链”。在这类语言中,一般会有关键字 object,但不会有 class
。如果要构造一个对象,就直接声明一个 object 变量就好;这个对象需要有什么成员属性,就直接添加上去就好;方法也可以通过添加一个 function 类型的成员一样加上去。继承要怎么办呢?用一个对象充当“元对象”添加上去,当前对象找不到的成员,就去这个“元对象”身上找。元对象自己也可以挂一个元对象,这样就实现了多层次的“继承”了。
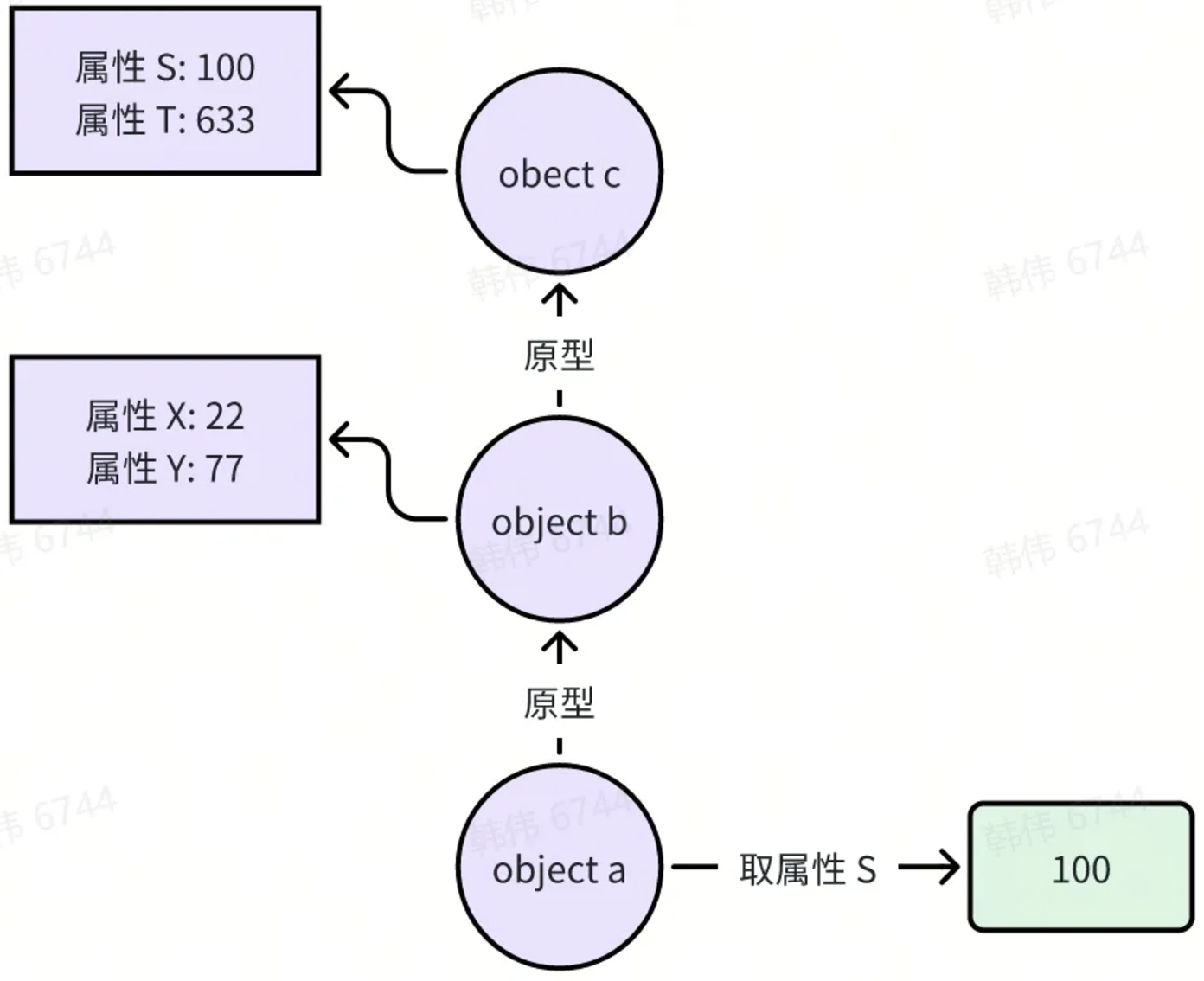
Lua 的 table 完全有能力通过“原型链”的方式,来实现面向对象的使用方法。Lua 的面向对象实现,最核心就是它的 metatable 能力。所谓的 metatable,意思就是“元表”,它能让开发者,对任何一个 Lua 的 table 变量,通过代码来自定义各种行为,包括:

除了上面这些,还有 ^ // & | ~ << >> # 等各种运算符的重定义。具体如何自定义 table 对象的运算符,可以查询 Lua 的元表和元函数手册。但是这里面,有一个最常用,也是对面向对象最重要的“元表”成员:__index。
通过原型获得属性
一旦为一个 table 变量,设置了包含 __index 成员的元表,那么所有的 table[key] 操作,都会去调用 __index 的值对象——你用一个 table 作为原型对象来提供“被继承对象(父类)”的属性,也可以写一个函数来返回 key 对应属性的值。
father = { last_name="Han", first_name="Da" } --> 被继承的父对象 son = {first_name="Xiao"} --> 子对象 meta_table = {__index=father} --> 建立去 father 查找成员的元表 setmetatable(son, meta_table) --> 设置 son 对象的元表,以便通过 father 查找未知属性 print(son.first_name, son.last_name) --> Xiao Han
方法:table 身上的函数
面向对象的属性,可以很方便通过 Lua 的 table 的 key-value 对来实现。而面向对象的方法,从原理上来说,其实也可以通过 table 的 key-value 记录,只不过 key 是方法名,而 value 是一个 function 类型的变量罢了。
obj = {} obj.method = function(a, b) return a+b end result = obj.method(1, 2) print(result) --> 显示 3
然后,上面这种方法,并不能称为真正的“方法”,因为携带方法的对象,并不能在方法代码里被使用。一个简单的做法,就是为作为方法的函数,设置一个参数,然后我们把对象传进去就好了。
obj = {a=1} obj.method = function(my_obj, b) return my_obj.a + b end print(obj.method(obj, 2)) --> 显示 3
由于“方法”这么写的话有点啰嗦:调用方法的时候,对象变量要写两遍;定义方法的时候,需要增加一个参数代表本对象——所以 Lua 提供另外一种等价的写法,但是看起来就简洁很多了:
obj = {a=1} function obj:method(b) --> 定义方法用冒号 : 会自动加上 self 参数作为第一个参数 return self.a + b end print(obj:method(2)) --> 调用方法用冒号 : 会自动传入本对象 obj 作为第一个参数
上面这种写法,用了一个冒号 :,就代替了把对象变量写到函数参数里,而且使用了固定的 self 来代替本对象。一切看起来就和其他面向对象语言一样,只是需要注意:定义和使用方法用 :,使用属性用 .
obj.a 等价于 obj["a"]
obj.method(obj, 2) 等价于 obj:method(2)
这个语法糖,比 Python 的要甜,Python 要我不厌其烦的写 self 参数
构造器
通过原型链的思想来构造对象,我们一般会设计一个“原型对象”,代表这类对象的初始状态。然后通过复制这个原型对象来构造实际的使用对象。由于有了上面介绍的“方法”语法糖,我们完全可以写一个类似其他语言的“构造函数”来做这个事情。
-- 定义 Person 原型对象(类) Person = { Name = "default", Age = 18 }-- 构造器函数 function Person:New(name) local new_obj = {} setmetatable(new_obj, {__index = self}) new_obj.Name = name --> 此处对 new_obj 插入了属性 Name,不再需要从元表查找此属性了 return new_obj end function Person:Show() print(self.Name, self.Age) end me = Person:New("HanDa") --> 通过原型Person对象,构造一个使用对象 me:Show() --> 通过原型Person对象的Show()方法打印属性:HanDa 18
在这个例程中,通过设置元表的 __index table,让新对象和原型对象“链接”了起来。对于属性来说,如果构造新对象的时候,有赋值原型对象的同名属性,那么这个记录,就直接存在了新对象身上,因此不会去再影响原型对象;如果一个原型对象的属性没有在构造新对象时赋值,那么后面对此属性的访问,就会访问到原型对象上。——所以也需要注意,非必要时不要在运行时修改原型对象的属性值,那会让很多以它为原型的对象的行为一起发生改变。除非你确定需要通过这种手段来“热更新”你的程序。
继承
面向对象的继承,在 Lua 这里一般是一个原型对象“继承”另外一个原型对象。用的方法和上面的构造类似,也是通过设置元表的 __index 属性,来组装原型链。
-- Person 原型对象的定义 -- Person = { Name = "default", Age = 18 } function Person:New(name) local new_obj = {} setmetatable(new_obj, {__index = self}) new_obj.Name = name --> 此处对 new_obj 插入了属性 Name,不再需要从元表查找此属性了 return new_obj end function Person:Show() print(self.Name, self.Age) end -- Student 原型对象继承于 Person -- Student = Person:New("default student") Student.School = "211or985" -->添加自己的属性 function Student:New(name, school) local new_obj = {} setmetatable(new_obj, {__index = self}) new_obj.School = school new_obj.Name = name --> 覆盖掉Student原型的默认值,此处无法通过调用 Persion:New() 来进行覆盖 return new_obj end function Student:Show() print(self.Name, self.Age, self.School) end me = Student:New("HanDa","三本") --> 通过原型Student对象,构造一个使用对象 me:Show() --> 通过原型Person对象的Show()方法打印属性:HanDa 18 三本
在其他的面向对象语言中,在子类构造器函数中,调用父类构造器,用来构造完整的对象,都是一个不容易的过程——C++ 使用了专门的语法称为“初始化列表”,Java 则在构造器中以“声明”的方式调用父类构造器,但调用的实际时间在子类构造器之前。而以上面的 Lua 为例,如果要想要通过父类(原型)的 New() 方法来构造子类(原型)的对象,就需要构造出很多不同的子类原型对象来,这显然是把问题复杂化了的。所以最好的方法,是不要在我们视为构造器的 New() 方法中写太多的逻辑,最多就是进行一些属性的赋值就好——因为子类原型对象的 New() 可能无法对每个子类对象调用此父类 New()。如果一个对象,在使用之前真的有很多属性需要专门的计算和设置,那就不要放到 New() 里面,而是专门写一个 Class.Init(self) 的方法来初始化,这样子类对象就可以手工的去调用这种方法了。
function Person:Init(name) self.Name = name end me = Student:New("Anything", "大专") me:Init("HanDa") <--此处调用父类原型对象的 Init() 方法来设置自己 me:Show() --> HanDa 18 大专
如果子类原型对象也有一个 Init() 方法,那么可以通过 Parent.Init(self, ...) 的写法,通过小数点 . 的方法,去调用父类原型对象的初始化方法。
反思
原型链方式实现面向对象的语义,如果不考虑“继承”这个特性,而是采用“组合”的方式来复用原型对象,那么其实会更加简单。元表的 __index 属性可以是一个函数,通过定义这个函数,我们可以组合很多其他的对象,让一个对象复用大量其他已有对象的功能。所以即便 Lua 的继承有很多种不同的写法,但我们也可以完全不去实现所谓的“继承”,直接通过组合对象和元表定义来实现面向对象的代码复用。
模板和泛型
模板和泛型一般是对强类型语言有用,就是为了让一批不同的类,都能被开发者以类似的方法所使用的技术。开发者定义了模板,这个模板可以通过使用时结合不同的类型,在编译时生成各种不同的具体模板类,但是这些具体的类,都会以类似的方法工作。——这种情况最适合就是各种容器数据结构了,譬如链表、哈希表、二叉树这些,因为这些数据结构存放的数据,往往是不同数据类型的。但是对于 Lua 这种动态类型语言了,基本上可以不管这些,因为 table 里面可以放各种数据类型的值,你如果想做一个什么容器,肯定也是用 table 来做的。所以 Lua 在这一部分基本上就跳过吧。当然也有人会研究 for 循环的“泛型迭代器”的细节,其实也是很好的。不过实际开发中我们很少需要自己定义迭代器就是了。
内存管理/垃圾收集
有些语言要求用户手工进行内存管理,所以每个变量都会需要选择是建立在“栈”还是“堆”上,并且用户写代码去回收“堆”上的变量——C语言就是这种。而 Java、C# 这类语言,由于代码是在一个“虚拟机”里面运行的,这个“虚拟机”程序会跟踪记录“堆”上的变量,并且自己找时间去清理那些无用的变量,所以关键字里面只有 new 而没有 delete——这对于开发者来说尤其友好。像 Go 这种语言,则连 new 关键字都不存在,只要返回一个“函数内的局部变量”,也就是“栈”上的变量,就自动会编译成堆上的变量,并且标记为需要跟踪清理。在程序的运行中,Go 写的程序也会自动回收“无用”的堆变量。Lua 和很多脚本语言一样,由于是通过解析器运行,所以可以认为所有的变量,都是解析器在管理,因此也无需关注到底是“堆”变量还是“栈”变量,总之会自动进行垃圾回收就可以,所以既没有 new 也没有 delete。
不过 Lua 中需要注意的是“全局变量”和“局部变量”,如果我们直接声明一个变量,那就是“全局变量”,这个变量很可能在某个其他代码段中,因为“重名”而被修改。所以我们建议尽量使用“局部变量”——声明的时候前面加上关键字:
local。
a = 10 function f() a = 11 b = 20 end f() print(a,b)
上面的代码会打印出结果 11 20,可以看到,变量 a 作为全局变量,在函数 f() 里面被修改了内容,而且还增加了一个全局变量 b。这对于习惯于其他语言的开发者来说,是非常“坑爹”的设计,因为其他语言变量默认都是局部的。默认是全局变量很容易导致比较大型的项目中,全局变量的名字“碰撞”到重名,导致莫名其妙的内容就被改掉了。所以请一定记住尽量多用 local 关键字,下面是正确示范:
a = 10 function f() local a = 11 local b = 20 end f() print(a,b) -- 打印结果:10 nil
至于为什么 Lua 要设计“默认都是全局变量”这么“坑”的东西呢?我觉得有一种可能,就是 Lua 的源文件,可以很方便的用来作为其他程序的“配置文件”。对于“配置文件”来说,变量就是配置项,肯定是“全局”的比较方便使用。另外,如果我们用 Lua 源文件作为某些数据的载体,譬如用来作为游戏的脚本,本身代码里面的大量常量,譬如道具名称、武器威力这些,都是全局使用的。
虽然 local 变量是在函数内独立隔离的,但如果我们返回了一个 local 又会怎样呢?其实不会怎样,既不会好像 C 语言那样出故障,也不会导致内存泄漏。因为 Lua 的变量大部分类型都可以直接复制其数值,所以就是复制了一下而已。而可能存放大量数据,而且成员复杂的变量类型 Table,返回的只是 Table 变量的“引用”,并不会整个 Table 里面的成员都复制一份。而 Table 本身的数据,其实是存在类似“堆”上的,所以返回出去之后,一样是可以使用的。
那么 Lua 的又是如何知道哪些是垃圾需要回收的呢?其实规则很简单:
- 所有的全局变量都不会被回收
- 所有的非 Table 类型的 local 变量,都会被回收。
- 正在被使用的 Table 变量,包括全局变量和局部变量——其内容的 key 和 value 都不会被回收,除非这个 Table 被声明为 weak 弱引用的。
- 如果有一个变量,所有包含它的 Table 的引用(包括 key 和 value)都是弱引用,那么它就会被回收。
简单来说,如果你不想你的 Lua 程序内存泄漏,只需要注意:
- 尽量使用 local 局部变量
- 不要往一个全局的 Table 变量里面无限制的加入内容
- 如果一个变量,明确已经在某个 Table 里面包含了,那么其他使用这个变量的其他 Table,可以考虑作为 weak 弱引用 Table 来包含它。这样有助于减少泄漏的可能性,如果使用大量 Table 包含一个变量,这里面任何一个 Table 不小心放到某个全局变量或者全局 Table 里面去了,就会泄漏了。
错误处理
程序在运行时,总是会碰到各种各样的“异常情况”,我们称之为“错误”。代码除了预期一切正常下,要处理的事情以外,还有非常多的代码,用来处理各种各样非预期情况下的事情。譬如你希望用户输入一个日期,但是用户可能输入了一段不能解析成日期的其他文字;又或者程序要从文件或者网络读取某些数据,作为程序处理的依据,但是文件可能被删除了,或者是网络断开了。早期的语言,并没有针对这些“错误”的处理,提供什么特别的支持,所以以上问题,都需要开发者自己来解决。最常见的处理方法就是所谓“错误码”:如果某个函数的运行出现了问题,就通过返回值来提示调用的程序出问题了,调用程序通过判断这个“错误码”返回值进行“错误处理”。随着这种情况越来越成为代码的“主要部分”,语言的设计者也把处理错误的事情放到语言设计中。
对于错误处理,一般需要两个步骤:
- 发现“错误”后,生成一个错误信息,让调用代码知道这个情况。对于 C 语言我们常见的有返回错误码,设置一个全局的 errno 变量等法子;Java 语言则设计了异常,可以通过throw关键字作为一种特殊的返回值抛给上层。
- 调用代码在发生“错误”后,编写一段特别的代码来处理它。C 语言的代码通常通过 if 判断返回值是否为 0,来发现函数中是否发生了错误;Java 代码则被要求必须编写 try...catch 代码来捕获和处理抛出的异常(或者继续抛出这些异常)。
对于 Lua 来说,错误处理更像 C 和 JAVA 的一种折中:
- 你可以通过 assert(expr, "err msg") 函数来进行判断,如果表达式为 false,则会“抛出”一个 Lua 定义的错误;你也可以直接调用 error("err msg") 来抛出一个 Lua 错误。只要抛出了错误,Lua 程序在默认情况下,就会中断执行,并且打印你定义的错误消息内容,以及错误发生的源码位置,函数调用(栈)信息等等。
- 你可以通过使用 pcall(func_name, ...) 的方式来发起对一个函数的调用,如果这个函数会抛出错误,Lua 程序将不会中断运行;而是让 pcall() 返回两个返回值:false 和 errinfo,其中 errinfo 返回值是你通过 error() 函数传入的参数,不必是一个字符串,可以是一个 table,这样你可以设计任意的内容以便上层调用者进行处理。如果 pcall() 调用的函数没有抛出错误,那么它返回的一个返回值会是 true,而后面的返回值则是具体调用函数的返回值。
-- 此函数会抛出错误 function add(a,b) assert(type(a) == "number", "a is not a number") if type(b) ~= "number" then error("b is not a number") end return a+b end -- 通过 pcall() 捕获错误 rs, err = pcall(add, 1, "kk") print(rs, err) rs, err = pcall(add, "ww", 2) print(rs, err) rs, err = pcall(add, 1, 2) print(rs, err)
代码运行结果:
false test.lua:4: b is not a number false test.lua:2: a is not a number true 3
Lua 通过 pcall() 捕获“异常”(错误),其实和 JAVA 有点像:抛出的错误如果在上一层调用者函数没有被 pcall() 捕获,则会继续往更上一层的调用者函数捕获,直到有一个 pcall() 进行处理。如果最后都找不到处理者,Lua 虚拟机最终的处理方式,就是中断程序并且打印错误信息。
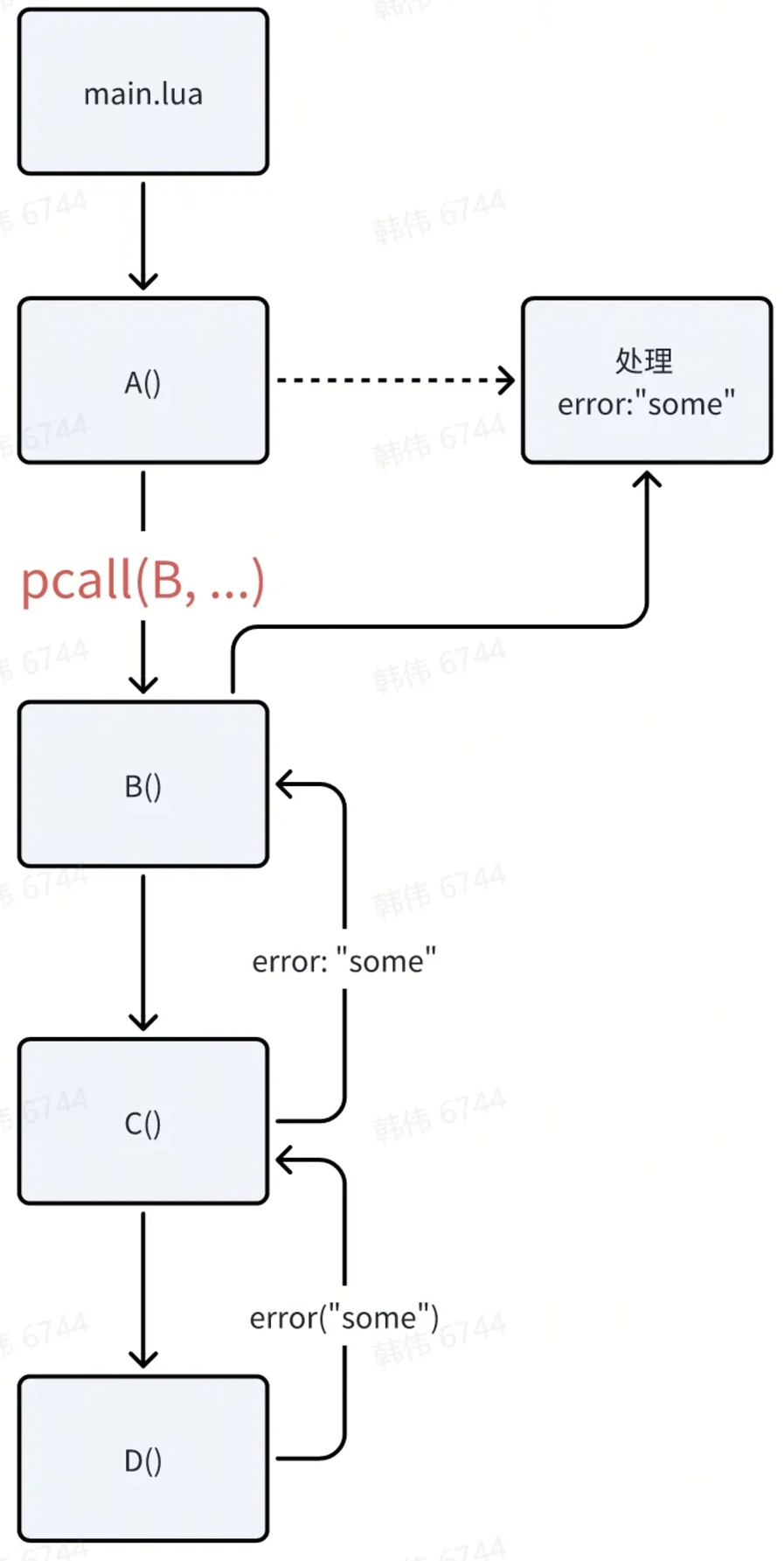
运行时错误,作为一种特殊的“函数返回”,一直是编程语言不得不面对的问题。Lua 其实和 C++ C# 一样,都是采用的自愿处理原则,也就是程序员可以不处理,但程序最终会中断。而 Java 采用的是强迫处理原则,如果一个函数声明了可能抛出异常,调用者必须处理这些异常,否则代码编译不过——这个做法确实能强迫开发者编写错误处理代码,但代价就是程序写起来费劲很多。而 Go 和 C 语言则显得非常佛系,你可以选择处理返回值里面代表错误的变量,也可以忽略,程序依然会继续运行,直到一个开发者无法预料的结果。这三种设计到底哪种最好,其实并无定论。你也可以在 Lua/C++/C# 这样的语言中,使用 GO 和 C 语言的错误处理策略,但重要的是必须要处理各种错误而不是漏掉。
多任务支持
现代计算机系统,基本上都支持“同时”运行多个程序。除了操作系统上,我们可以启动多个进程同时运行,我们编写程序,也往往会需要在一个程序里面处理多个事情,譬如游戏里面,我们需要一边让画面上的角色活动,一边等待和处理玩家的输入;我们在加载或者处理一个大型文件内容的时候,同时需要在屏幕上显示正在处理的进度信息;网络服务器程序,需要同时处理多个玩家的操作等等。——所有这些需要同时运行的代码,实际上是对计算机 CPU 的运行时间分配和管理提出了需求。如何解决这个需求,不同的计算机语言也提出了不同的方案。
通过 C 语言,我们能利用 Linux 操作系统的 fork() 等系统调用函数,比较方便生成子进程,这样当前运行的函数,就会在两个进程里“同时”运行了。但是这种机制有很多问题,譬如这两个进程运行的函数都是同一个,虽然可以通过写代码的方式在后续的运行中再选择不同的代码,但是用起来也太麻烦了点。另外,操作系统的子进程建立和销毁,从性能上来说还有改进的余地。所以后来也出现了 pthread 库这种“多线程”的功能库,让使用者可以直接启动任何一个需要“同时”运行的函数,到后来的 JAVA C# 以及更新版本的 C++,都对多线程进行了更好的支持。
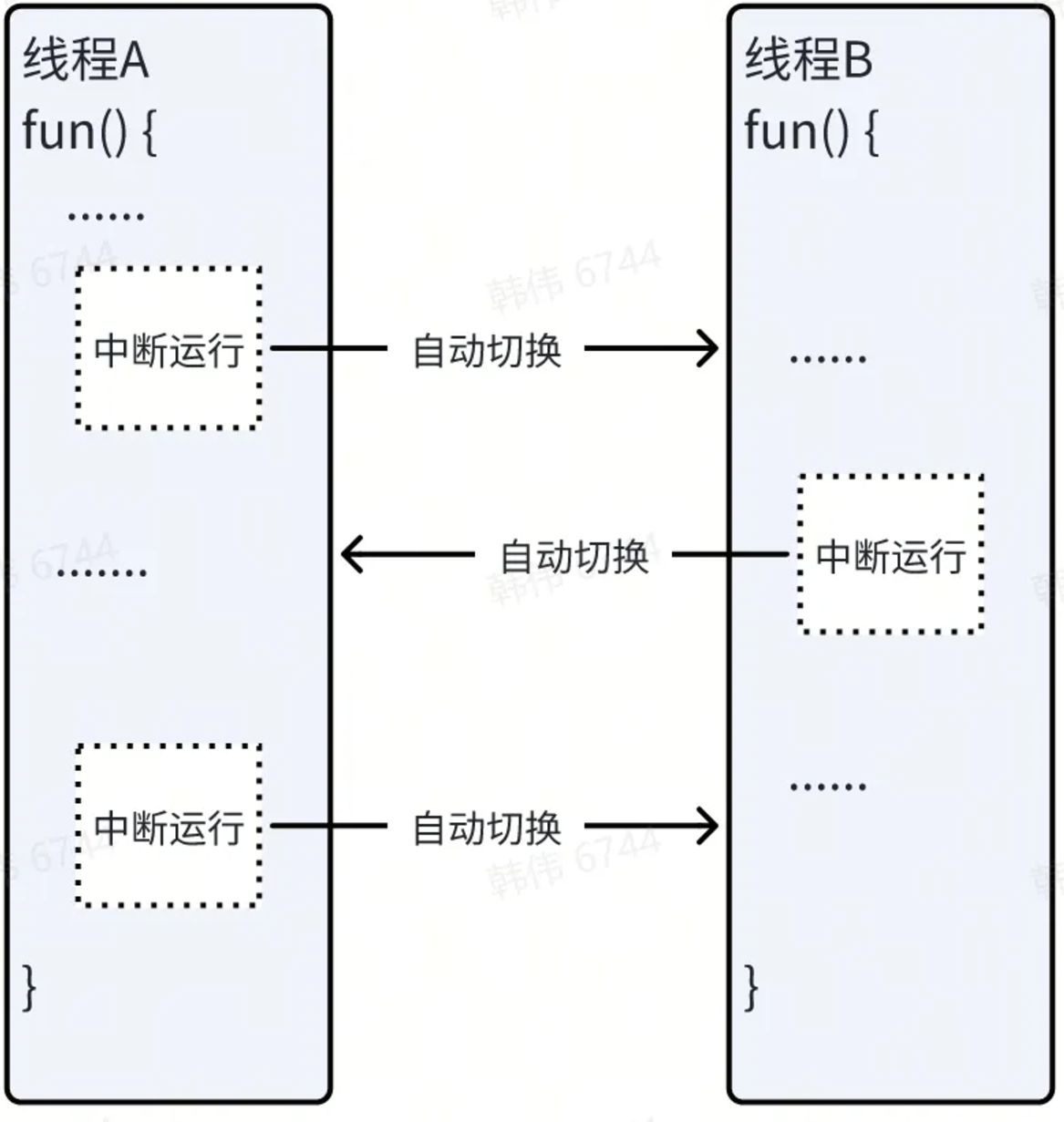
尽管多线程概念非常容易理解,就是多个同时运行的函数,但是还是存在一些待改进的问题:
- 同时运行的多个函数,对于可以读写的同一块堆内存(或者叫变量),可能造成不可预期的结果。因此诞生了很多种类的“锁”,来试图解决多个程序同时修改、读取同一组变量造成的故障。
假如有一个变量存放了银行存款余额,有一个购买商品的函数,它们都会先读这个变量来看是否足够来购买商品,然后再减少这个余额,一旦两个购买行为同时运行,这个函数被同时调用,那么可能都会认为此余额是足够的,但最后两个购买行为一起去扣减,最后导致余额变成负数。
- 同时运行的多个函数,也许不是性能最好的做法,因为计算机需要在这多个函数的运行环境之间反复切换,这种切换本身也需要成本。
为了解决上述的问题,另外一个解决多任务的思路,就是不试图去同时运行几个函数。而是让函数可以运行到某些代码之后,就切换到运行其他函数,当条件满足之后,在切换回来继续运行。这种做法比较典型的是,当函数运行到一个需要 CPU 等待的操作的时候,譬如等待读取网络、等待读取文件、等待用户输入这类操作的函数之后,就切换出去运行其他需要“同时”运行的函数上,直到之前在“等待”的事情有结果了,再切换回来继续运行这些代码。
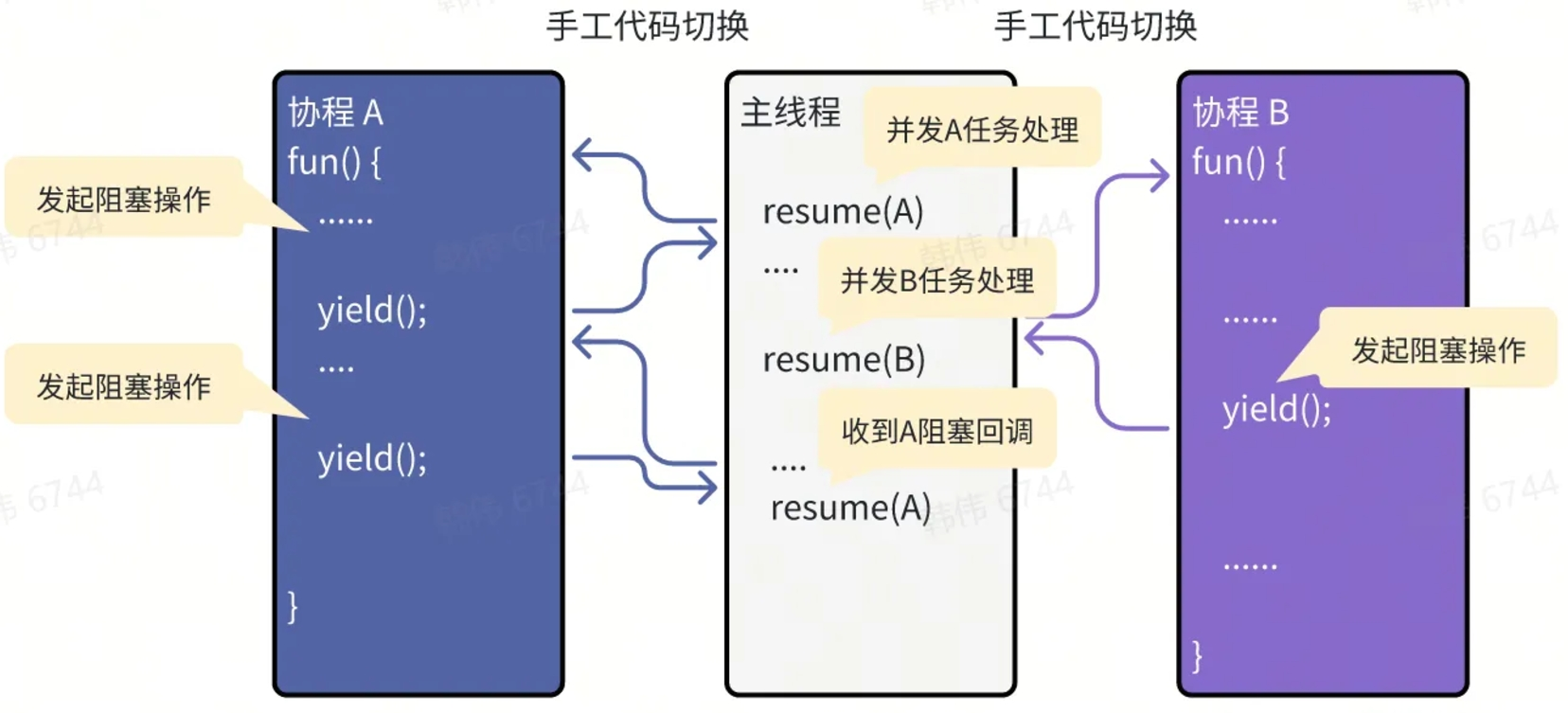
在这种手工切换函数运行时机的概念下,这种函数运行时机,我们称为“协程”。从“协程”切换出去的操作称为 yield,而从其他协程或者主线程切换回来的操作,称为 resume。在这种情况下,虽然“同时”有多个函数在运行,但始终只有一个线程在运行。程序不再是仅以 return 语句为结束退出函数运行,而是增加了一种特殊的退出手段:yield。而函数的运行也不再仅仅是从函数开始,而是通过 resume 操作,可以从最近一次 yield 的地方开始继续运行。通过这种方法,对于上面多线程的问题,有了新的解决方法:
- 对于同时读写变量的问题。由于协程是可以自己写代码进行切换的,所以把可能出现同时操作的代码,有意识的不要用 yield 断开。由于始终只有一个线程在运行,只要别切换出去,变量就不会被其他程序修改。——这样也不需要什么锁了。
- 由于只有一个线程在运行,协程之间切换的代价会大大降低,而且切换的代码是手工编写的,也提供了更细致的调优的手段。
Lua 用的就是这种方法进行多任务的支持:
function foo() print("协同程序 foo 开始执行") local value = coroutine.yield("暂停 foo 的执行") print("协同程序 foo 恢复执行,传入的值为: " .. tostring(value)) return "协同程序 foo 结束执行" end -- 创建协同程序 local co = coroutine.create(foo) -- 启动协同程序 local status, result = coroutine.resume(co) print(result) -- 恢复协同程序的执行,并传入一个值 status, result = coroutine.resume(co, 42) print(result)
用图来说明这个最简单协程的运行流程:
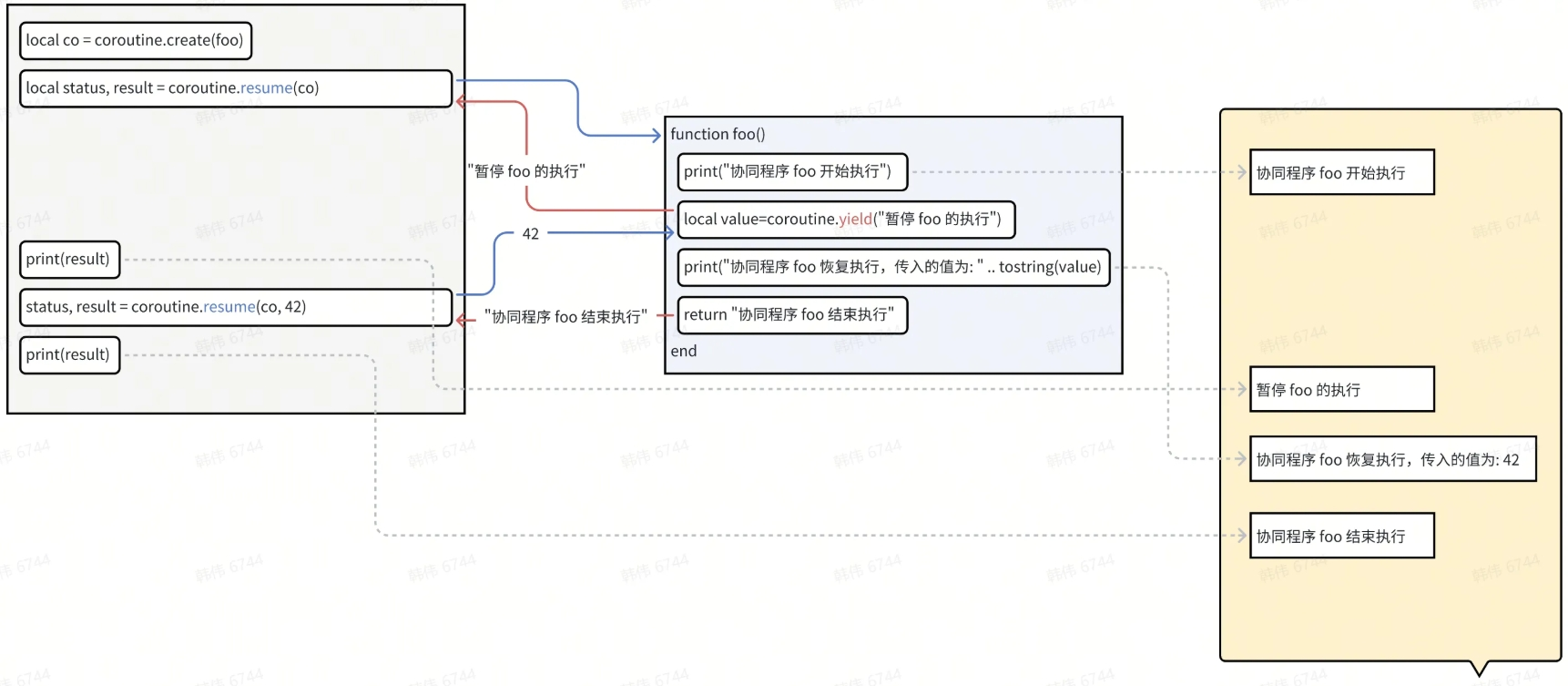
- coroutine.resume() 用来进入一个协程函数,输入参数会成为协程函数的入参,或者 coroutine.yield() 的返回值。Lua 支持多返回值的好处这里就看见了,多个 resume() 参数可以自然的成为 yield() 的多个返回值。
- coroutine.yield() 用来以一种特殊的 return 切出函数,其参数是 coroutine.resume() 的返回值。如果协程函数结束,return 的返回值也会以 resume() 的返回值形式提供给调用者。
在使用 Lua 的协程时,必须要注意所有的函数,都必须是非阻塞的,因为只有一个线程,所以任何一个阻塞就会把所有协程都阻塞了。因此对于网络 IO 等操作,就要用类似 epoll 这类异步 API。同步的阻塞 API 只能在 C 语言那侧启动多线程,然后再发起回调到 Lua 这一侧。
框架支持
随着软件项目的越来越大,很多时候我们写的代码,并不仅仅是给具体的用户来使用的,而是会为其他开发者也写很多代码。这种提供给开发者使用的代码,是通过代码的各种编程接口来提供的。最简单的就是我们写了一个函数,然后提供开发者调用。这些函数如果有很多,我们会整理成为一个集合,称之为“函数库”(Library)。库里面的有一部分函数,是为了实现库的功能而存在,是不希望被开发者使用的,而另外一部分,则是设计用来专门提供给开发者使用的——这些函数我们称之为 API(Application Programming Interface)。但是现在 API 这个名词已经被庸俗化的限定成 RESTful API 的含义了,让我很不爽。
除了 API 以外,还有一种提供开发者使用的代码方式,就是“框架”(Framework)。所谓框架,就是让开发者按某个规则来写一段代码,放到我(框架开发者)的代码里面来运行。这是和 API 库一样历史悠久。写过 C/JAVA 程序的人都知道,程序的启动都需要写一个 main() 函数,而函数的参数就是命令行参数,返回值会被操作系统记录为进程的结束状态。这就是一种“框架”的设计,main() 的格式就是一种框架的接口要求,启动进程这个过程就是框架在工作,然后调用使用者的代码。
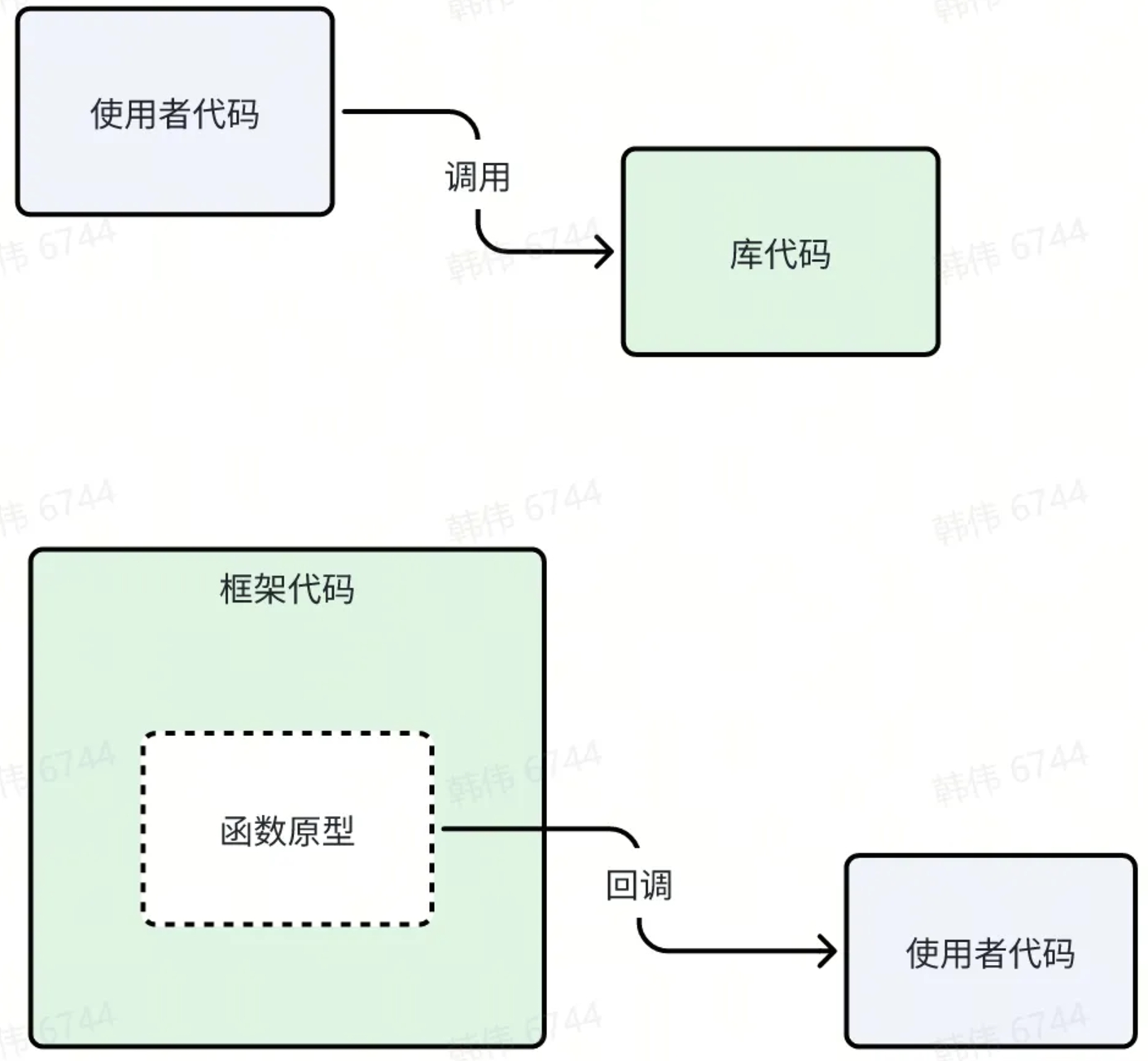
回调函数
最简单的框架接口,一般就是一个约定的函数格式,包含:这个函数的参数有几个,返回值有什么作用。框架代码在使用者传入按照约定格式的函数之后,根据自己的功能要求,在合适的时机调用这个使用者的函数。这种函数也被称为“回调函数”(Callback Function)。
C 语言里面一般通过定义一个“函数指针”来定义这个约定的回调函数格式。在 Lua 里,函数 function 是一种值的类型,所以可以直接像定义一个变量一样,定义一个函数。框架接受这种 function 类型的变量值,就可以用来发起回调了。
-- 回调函数 add = function(a, b) return a+b end sub = function(a, b) return a-b end -- 框架代码,主要功能是打印计算结果 function cal(cal_fun, a, b) print(cal_fun(a,b)) end --使用框架 cal(add, 3, 2) --> 5 cal(sub, 3, 2) --> 1
上面的例子中,add sub 两个变量就是函数类型的变量,使用者可以定义任何的 function(a, b) 并且有一个返回值的函数,来构造一个这样的变量,用作参数传入框架 cal() 中使用。
反射
虽然我们可以让使用者,通过代码的方法传入“回调函数”,来提供框架运行的功能,但是如果框架功能比较复杂,需要根据不同的情况,传入大量不同的回调函数,这就很容易出现传入回调函数出错的情况。譬如,用户输入“加减乘除”的命令行参数,对应执行加减乘除的回调函数。——这种情况下我们必须设计四个用户输入的命令,然后传入对应的回调函数,这个过程如果让使用者去做,难保不会理解错命令到函数的含义,这个时候,我们可能会想到:函数的名字本身就是一个“字符串”,我们能不能直接用这个函数名字,来作为对应的输入操作指令呢?作为一种脚本语言,Lua 显然可以很简单的做到这点:
-- 框架代码:从命令行参数执行命令 function run_cmd() -- arg 是一个全局 table 变量,记录了全部的命令行参数 if not arg[1] or not arg[2] or not arg[3] then print("Usage: cmd arg1 arg2") return end local f=load("return "..arg[1].."("..arg[2]..","..arg[3]..")") print(f()) end -- 回调函数 function add(a, b) return a+b end function sub(a, b) return a-b end -- 运行框架 run_cmd()
运行示例:
$ lua test.lua add 1 3 4 $ lua test.lua sub 1 3 -2
在上面的例子中,我们直接用函数名字 add, sub 作为指令进行调用,关键是调用了load()这个函数,这个函数可以解析传入的字符串,按照 Lua 代码的格式进行处理,并且把这段代码构造成一个函数返回。如果我们输入命令lua test.lua add 1 3,实际上动态的构造了一个如下的函数:
-- local f=load("return ".."add".."(".."1"..",".."3"..")") local f = function(...) return add(1,3) end
上面说了用一个字符串调用同名函数,其实源码中的变量,也是可以字符串中的名字进行访问的。最典型的就是 table 支持的语法:
tb = {a=1, b=2} pirnt(tb["a"]) --> 1
Lua 中的全局变量,都是存在一个大 table 里面的,这个 table 的名字是 _G,所以全局变量都是可以用字符串名字访问的:
a = 100 print(_G["a"]) --> 100
所谓反射,就是可以在运行时,通过在字符串变量名中的函数名字来调用这个函数;通过字符串变量中的变量名字来读写变量。
注解
当我们编写一份程序源代码的时候,我们的这些代码,除了编译运行以外,还有可能需要和其他的一些程序产生关联,或者根据这份源码自动生成其他一些代码以便共同工作。譬如我们在定义一个数据结构体(由多个不同类型的变量组成的一个复合变量)的时候,可能需要同时让这个数据结构能被序列化成 JSON 以便在网络上传输,或者记录成文件;又或者我们在定义一个函数或者方法的时候,希望这个函数能够在游戏中的某类物品碰撞时被调用。——传统的做法是我们直接通过框架的函数,去“注册”这些数据结构或者函数,但是有一些语言,支持我们可以在源码上加上一些特殊的代码(主要是标记在数据结构和函数上),然后框架代码可以通过语言提供的能力,提取这些特殊代码,及其被标记的数据结构和函数,产生新的代码或者处理程序。在 Java 里叫 annotation,在 C# 里叫 attribute,在 Go 里叫 tags。
至于 Lua,语言上似乎并没有这种特殊的设计。但是得益于脚本语言的好处,我们可以获得运行时整个 Lua 虚拟机里面的所有变量、函数对象,也可以通过 dofile() 函数执行任意的 Lua 文件。所以完全可以很简单的编写代码来对已经载入虚拟机的所有 Lua 代码进行二次处理,譬如对这个源文件里面的所有变量和函数进行登记和注册,然后生成任意新的 Lua 源码文件,做任何注解可以做的事情。
模块管理
现在大部分语言的源码,都不会仅仅放在一个文件里面。那么如何才能让多个不同的源文件,合并到一起工作呢?这就是所谓“模块管理”要解决的问题。很多时候,我们可以把一个源文件视为一个“模块”,那么这个源文件要能作为模块被其他源文件使用,必须要遵守一定的规则。不同的语言对于这个问题有不同的设计,比较奇葩的是 C 语言就没有对此有任何的标准的规定,可能是因为这门语言实在是太古老了。
一般来说一门语言需要在模块管理方面,定义以下三个方面的内容:
- 定义模块:怎样写代码,怎样命名文件才能成为一个合法的“模块”
- 引用模块:怎样写代码才能调用另外一个模块里面的功能,譬如调用函数或者构造类对象
- 编译或运行的方法:怎样操作才能让各个模块的代码一起运行
对于 Lua 来说,定义模块的方法是:
- 建立一个以模块名为文件名的源码,譬如 aaa.lua,就代表了你想要设计一个叫 aaa 的模块
- 在模块源文件内,定义一个 table,如 tb = {},然后把你希望提供给使用者的变量、函数,都存放到这个 table 变量(tb)里面,最后在源文件末尾写上 return tb 来返回这个 table
引用模块的写法也很简单,就是一句:require("aaa"),这里的 "aaa" 是你定义的模块的名字,也就是那个模块文件的名字。一旦你运行了这行代码,你在之后的代码中,就可以使用 aaa.XXX() 或者 aaa.YY 的方法来使用定义在 aaa.lua 里面的各种函数和变量了。——这基本上就是一个通过文件名读取一个 Lua 的 table 的过程。
最后要注意的是,你的模块文件应该放在使用者的 .lua 文件同一个目录,或者,放在环境变量 LUA_PATH 里面定义的多个文件路径里。在编写环境变量的路径的时候,可以用 ? 号来代替模块名,以指定实际的完整 .lua 文件路径。
模块文件例子,文件名为 module.lua
module = {} -- 定义一个常量 module.constant = "这是一个常量" -- 定义一个函数 function module.func1() io.write("这是一个公有函数!\n") end local function func2() print("这是一个私有函数!") end function module.func3() func2() end return module
调用模块的例子
-- module 模块为上文提到到 module.lua require("module") print(module.constant) module.func3()
运行结果:
这是一个常量 这是一个私有函数!
可以用作搜索模块的路径定义例子:
export LUA_PATH="./?.lua;/usr/local/share/lua/5.1/?.lua;/usr/local/share/lua/5.1/?/init.lua;/usr/local/lib/lua/5.1/?.lua;/usr/local/lib/lua/5.1/?/init.lua"
搜索的路径:
./module.lua /usr/local/share/lua/5.1/module.lua /usr/local/share/lua/5.1/module/init.lua /usr/local/lib/lua/5.1/module.lua /usr/local/lib/lua/5.1/module/init.lua
最后,对于想用 Lua 实现“热更新”的开发者,Lua 也提供了一个手段。因为 Lua 的 require() 操作,是会先去全局变量 package.loaded["aaa"] 里面找一下,是否存在同名(aaa)的模块,然后再决定是否加载模块文件的内容。因此我们只要把 package.loaded["aaa"] 设置成 nil,就可以重复调用 require() 进行重新加载了。
虽然,通过 dofile() 也可以实现类似“热更新”的方案,但其实这是每次都去运行解析一次 Lua 源文件,并不能妥善的处理加载前和加载后的内容,所以还是使用package.loaded 这个 table 比较好一点。
小结
Lua 的高级特性,很多都是依赖于其通用数据结构 table 来实现的。所以只要理解了 table 的原理,很多事情都可以自己去实现。我们也不必非要按照其他的某种语言的惯例,去改造 Lua 的用法,而是应该去思考,怎样才是最快实现功能的方法。因为 Lua 本身就是为了提高开发效率而设计的一种语言,如果我们为了符合某种范式,写了一大堆的架子代码,可能反而丧失了这门语言的优点。
下一篇介绍 Lua 为数不多但灵活好用的库函数