先疊加:本人只是瞭解,如果錯誤歡迎指出。
為什麼不發csdn
因為全是ai水文章和賣課的,找了半天一個有用的都沒有,所以我也不想發。
像極了我水論文的樣子
前言:craw4介紹
異步爬蟲,可將爬取的網頁轉換為markdown、清理過的html語言、json語言。相比requests來說提取的網頁能直觀看懂。文檔:https://crawl4ai.com/mkdocs/
學習推薦網站:https://www.studywithgpt.com/zh-cn/tutorial/ynms80
特點(我自己總結的)
可以基於css選擇器爬取指定部分
在爬取數據前可以預先執行js代碼
爬取重複界面緩存功能
使用簡單,如下圖
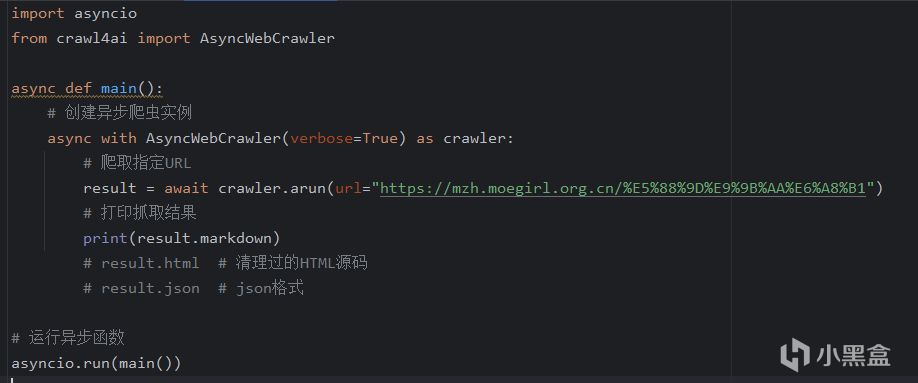
代碼
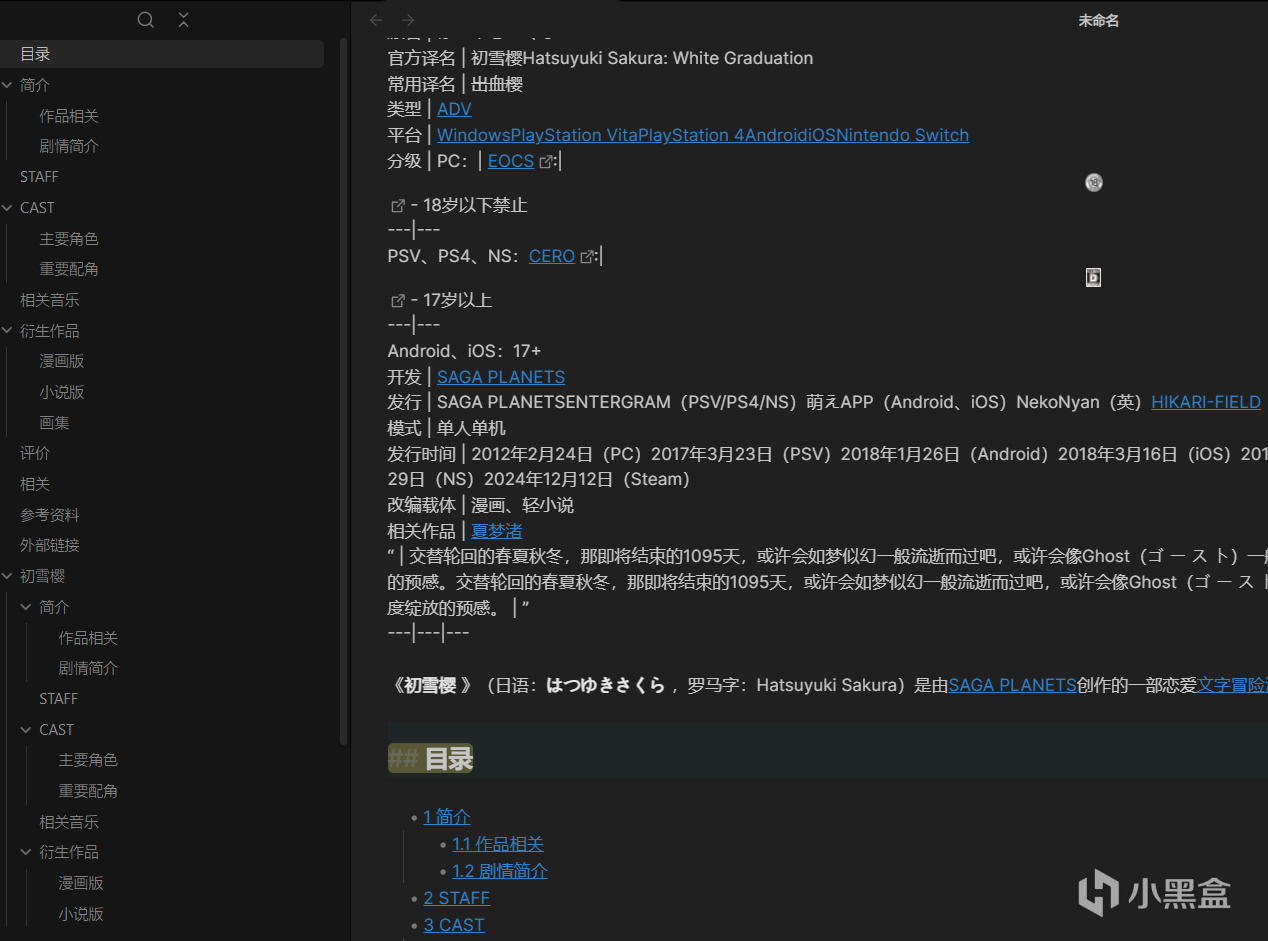
結果
正文:
目的:爬取頁面數據,返回json格式數據。(爬取萌娘百科對應的galgame信息)
步驟:
利用crawl4ai庫爬取頁面數據markdown格式數據
利用通義大模型解析markdown格式數據
pydantic驗證數據格式
輸出json格式數據
crawl4ai爬取markdown格式數據
headers和代理設置也很簡單。只需要在 verbose後加headers=..就可以
css選取了所有段落p,還有一個主要角色列表。這兩個基本就能包括所有的想要的信息
通義大模型處理
大模型網站:https://bailian.console.aliyun.com/
在對應的應用用人話寫出你想要的東西,然後進行優化。
具體大模型調用方法查看網站示例(很簡單)。
大模型返回有時會有額外內容,如提取後的json文本如下,```json 內容```,用正則過濾一下json就好,這能保證返回的data,一定是json格式
pydantic數據校驗
大模型返回json格式一般來說不會出錯,在prompt裡明確指出返回json格式包括哪些字段,沒有返回空。
如果後續要處理內容,為了數據符合格式可以加校驗。
目標格式如下,後面None表示允許空
格式
校驗很簡單,只需要try: OpenAIModelFee(**data) ,不符合格式會拋出異常。
最後,代碼輸出結果
輸出結果
代碼:https://wwkt.lanzoul.com/iyV4f2irlxgd
其他
原本crawl4有用openai直接進行處理,看起來好像不需要自己進行數據驗證,只需要把提問詞加上就行,然後能直接爬取。看起來很方便,但是我的不知道為什麼報錯,到現在也沒解決。"content": "No module named 'openai.types'; 'openai' is not a package" 好像與環境有關,但不知道怎麼解決
小黑盒什麼時候能支持代碼塊呢....