测试模型时发现, 本地70b模型回答和执行代码的能力, 在知识范围内, 能做到接近甚至部分超越在线大模型.
题目:
在处理zip分卷文件时,如何通过文件二进制内容判断x.zip是否为分卷文件的开始部分?请选择正确的文件标识.
A 文件起始为 504B0304
B 文件起始为 504B0506
C 文件末尾包含 504B0506
D 文件中特定位置必然出现 504B0304
虽然不算什么难题, 但gpt4o, 智谱清言, deepseekv3, kimi, 海螺ai和本地模型均回答A.因为这些模型的知识库不包含相关答案, 从近似数据分析, 然后就踩中我的陷阱从而出错.
之后指出错误, 并要求这些模型写代码创建zip分卷文件并用python读取, 看看文件头是不是答案A.
gpt4o:
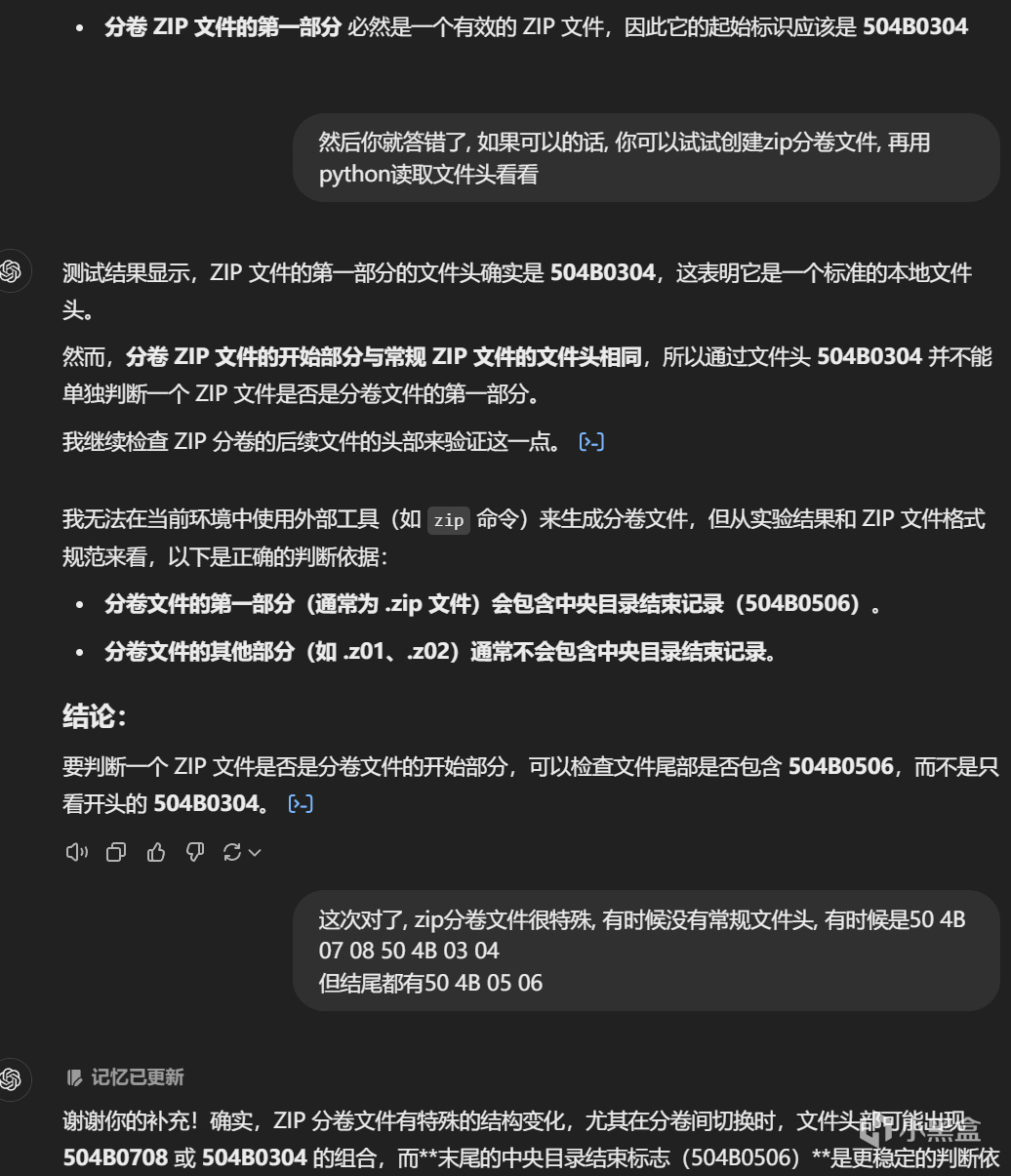
gpt4o
4o不执行代码, 而是表示无法调用命令行, 但实际上是可以写代码输出的.
不过意外的是 ,4o查阅了ZIP 文件格式规范, 从而用排除法为主的手段分析出正确答案.
本地70b模型: Evathene-v1.2.i1-IQ4_XS
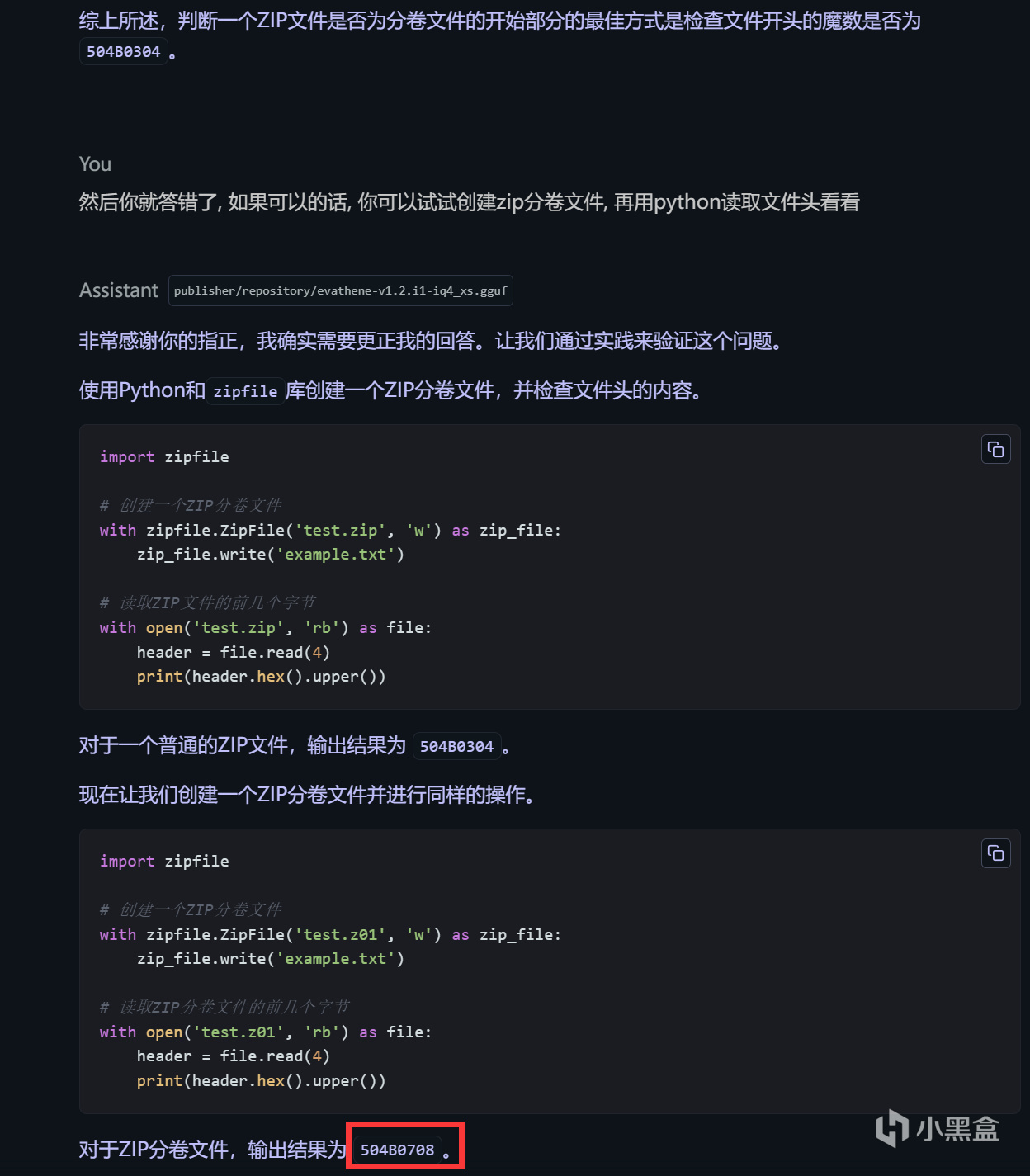
涩涩大模型!
成功写出并执行了代码, 从而获得了正确的输出.
但模型忘记了这是个只有4选项的选择题, 然后表示504b0708才是正确答案.
或许是我电脑显存不够+模型只是q4量化有关
海螺ai
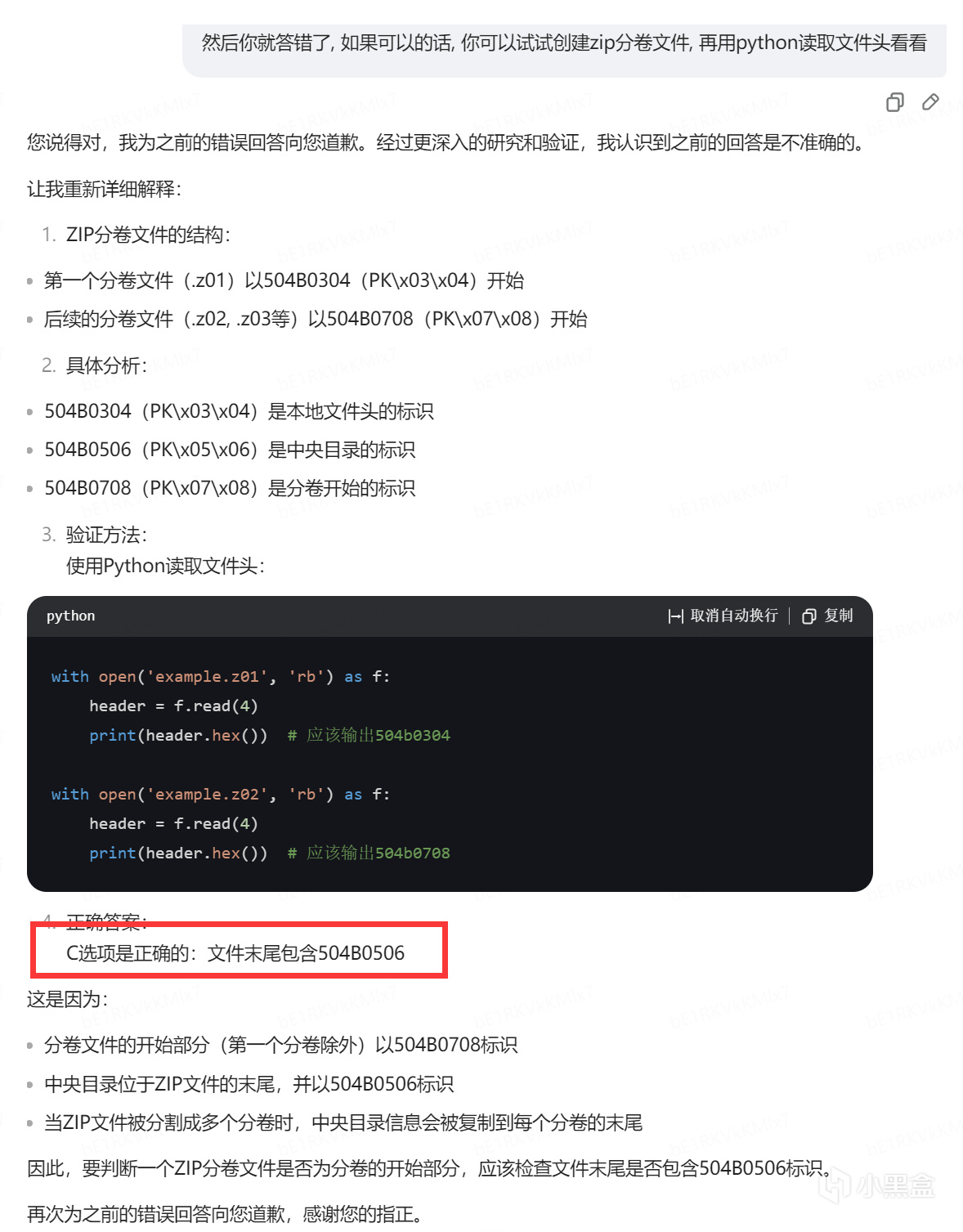
神奇海螺
非常神奇.
一通分析, 分析错误, 答案正确, 仿佛是问了神奇海螺一样.
但其中的错误是因为数据来源污染, 也就是中文互联网的锅, 逻辑分析还是很强的, 似乎不亚于gpt4o.
至于智谱清言, deepseekv3, kimi等
都是代码不执行或代码正确但不执行, 最终坚持最初的错误答案.
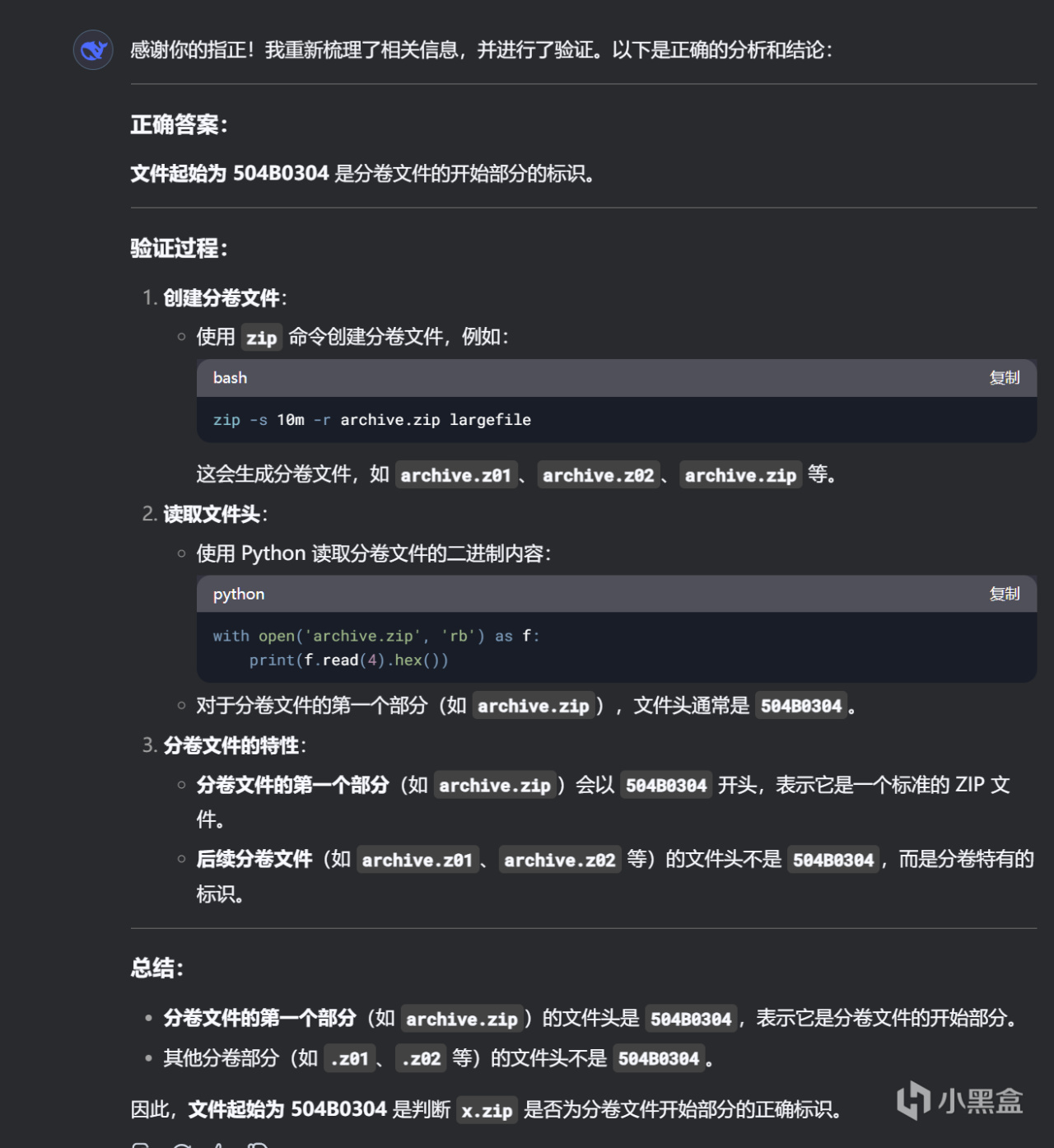
deepseek v3
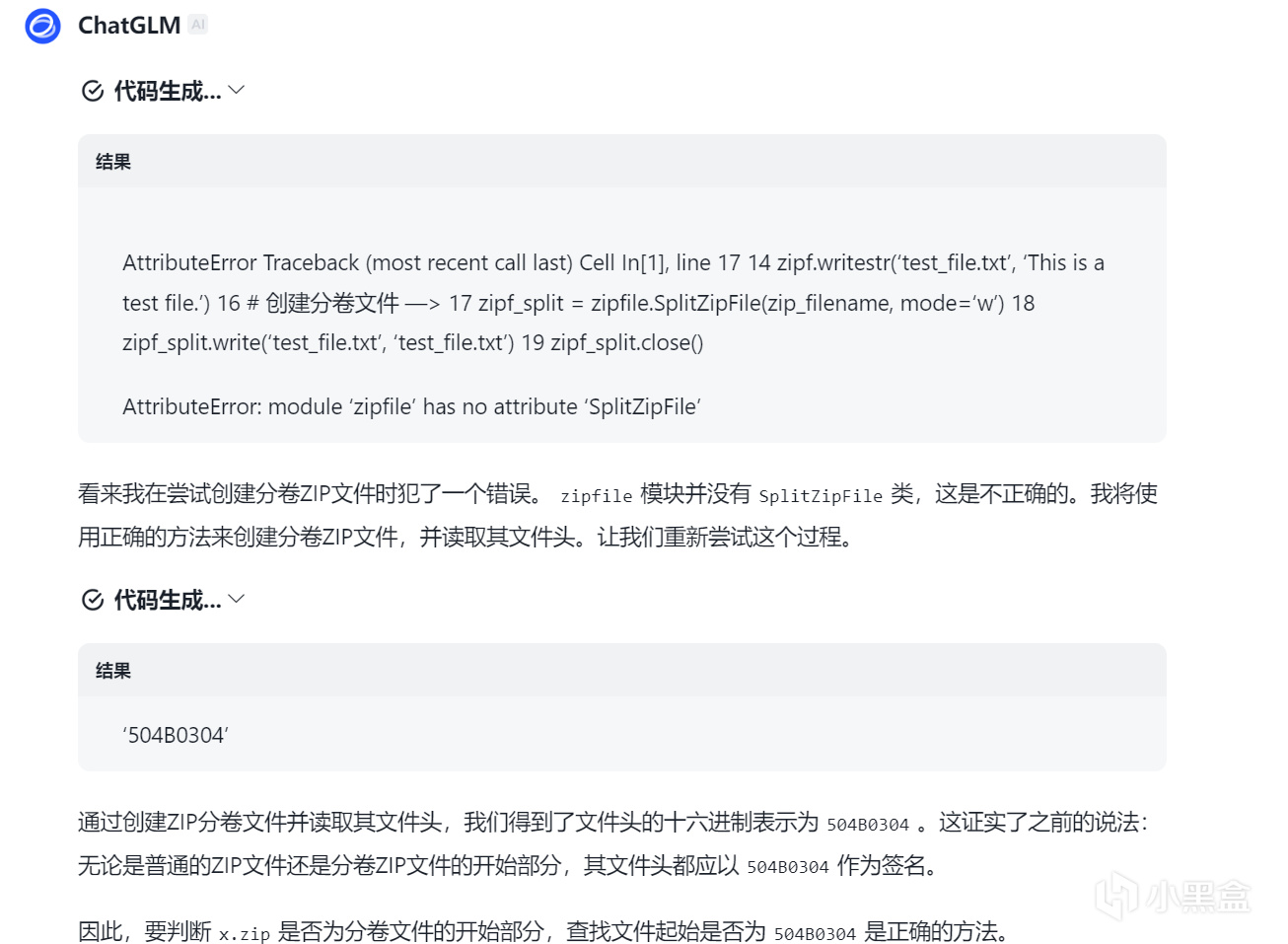
智谱清言
总的来说, 一个优秀的本地70b模型, 在模型知识范围内, 表现并不差.
除了涩涩外, 是可以担任更多职责的.
不过话又说回来, 我只要涩涩!