“PHP 是世界上最好的語言——(破音)”
關於編程語言的話題,一直是程序員們的經典話題。幾乎每種語言,都有一批近乎宗教狂熱般的粉絲。曾經的我,也是其中一份子,現在回想起來,有一部分原因,是由於學習並掌握這門語言的生態,需要付出不小的時間精力成本,所以自然會有“維護”自己的付出的偏見。當我學習並使用的語言越來越多,我卻發現很多有意思的事情,於是想聊聊這些發現,也希望能給學習編程語言的讀者,一些微薄的幫助。
學習編程需要什麼前提條件
數學和編程的關係
在我真正開始學習編程之前,我就聽說過:“編程需要很好的數學能力”。由於我以前的數學考試成績不算很好,所以一直都不覺得自己適合搞編程。想不到的是,由於接到一個兼職的工作,需要用到編程能力,從此走上了穿格子衫的碼農生涯。
現在回頭來看,“編程需要很好的數學能力”的這個認知,我起碼犯了兩個錯誤。第一個錯誤是,我把數學考試成績等同了自己的數學能力;第二個錯誤是編程工作是一個具有廣泛內容的事情,在很多領域並不需要你掌握很多高級的數學工具。
國內的數學教育,由於高考指揮棒的存在,所以大部分都是為了“解題”而設計的,而真正的數學能力,是抽象思維能力以及想象能力。很多做題高手,可以憑藉海量的題目信息,以及高超的記憶力,去考出高分。但是面對需要複雜的邏輯問題,需要自己設計一些邏輯工具去解決問題的時候,往往並不能很好的解決。編程就是需要有抽象的理解能力,並且能通過想象力,在腦海中構建出一系列的概念,並且推理出方案的活動。而在一般的信息管理程序開發領域,我們要用的數學工具,最常見的也只有初中代數而已。如果你還寫一點 2D 的遊戲,可能會用到一些平面幾何知識,如果做一些策略遊戲,可能用到一點概率論或者僅僅是排列組合的知識。除此之外,很多高級的數學工具,在編程工作中都並不普遍,起碼寫個 APP 網購什麼的是用不上的。
import math # 使用勾股定理 a = 3 b = 4c = math.pow(a*a + b*b, 1/2) print('勾', a, '股', b, '弦', c)
如果你要開發 3D 遊戲,特別是和圖形渲染相關,需要學習計算機圖形學,還是需要一些數學知識的。但是這類知識,和高考數學成績,個人感覺關係不是很大。如果要開發機器學習的程序,可能需要對線性代數、微積分有一定的瞭解,不過就算你不是特別懂這些,也不會讓你完全沒法從事機器學習的工作。
從基本的數學能力,也就是抽象思維、邏輯推理、想象力這些角度看,編程工作確實和數學關係匪淺;但這並不表示數學考試成績不好,就不適合編程,也不用因為沒學過離散數學或者圖論,就覺得自己不能成為優秀的程序員。如果你手上有一個問題,看起來可以用編程解決,完全可以放心大膽的開始。興趣和需求,才是真正的學習編程的前提條件。
語文和編程的關係
一般情況下,很少人會認為編程和語文有什麼關係,最多可能覺得,寫寫技術文檔會用到語文。但是軟件開發界有一句名言:
任何人都能寫出計算機能讀懂的代碼,只有好的程序員,才能寫出人能讀懂的代碼
There are only two hard things in Computer Science: cache invalidation and naming things (計算機科學中最難的兩件事是命名和緩存失效) - Phil Karlton
現在軟件開發的核心矛盾,是日益增長的需求變更,和相對落後的開發效率之間的矛盾。解決這個矛盾的基本方法,就是提高代碼的可讀性。只有這樣,才能讓代碼的修改更快速,才能讓更多的人投入到一個軟件項目裡並行開發。
如果你要寫一份程序源代碼方便人類理解,清晰準確的註釋必不可少,但更重要的是,整份代碼的思路是要清晰合理的,是要以方便閱讀的角度進行“謀篇佈局”的。在具體的代碼表達式上,也應該選擇更符合人類思維習慣的進行編寫;同時對於變量、函數的名字,也需要認真的設計,以確保表達其含義,這就是編程所需的“遣詞造句”。
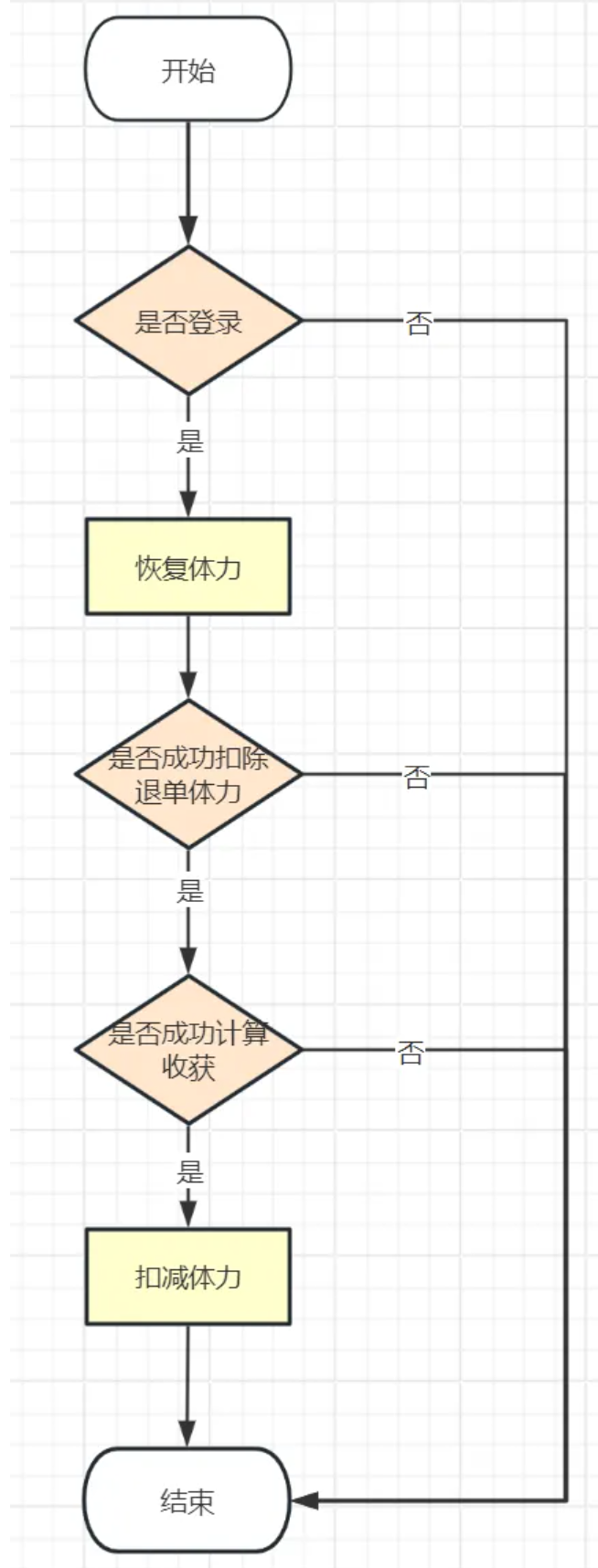
常見的判斷流程代碼
在我們的語文課程學習中,最常見的課題是:中心思想、段落大意。如果我們能很好的掌握,如何從文字篇章中分析、理解這些含義的技巧,那麼我們在編寫軟件的時候,也可以用同樣的技巧用在代碼的閱讀和編寫上。在我看來,語文水平的差別,代表了平庸的程序員和優秀的程序員之間差別。
英語和編程的關係
以前,很多編程技術資料、手冊都是英文的,所以那個時候,英語水平確實對技術學習有一定的影響,但現在機器翻譯水平已經很不錯了,相當多的技術學習,完全可以使用母語來開始。當然,有很多“硬核”程序員,堅持要看原版英文書籍和手冊,並宣稱這才是最好的學習方法,不過在這個信息爆炸的年代,這麼做對於自己要求確實也是太高了一點。
儘管英語水平,現在早已不是從事編程工作的門檻了。但是擁有一定的英語能力,還是很有必要的。我曾經見過使用漢語拼音作為變量名和函數名的代碼,閱讀起來除了很慢以外,而且時不時我還會改錯:要知道,中國有很多方言地區,這些地區的人,對於普通話的讀音,可是各不相同的,譬如“灰機”、“資識”。與其折騰五花八門的方言拼音,還不如查一下字典用個好點的英文單詞。
有的人會說,為啥我們不直接用漢字作為編程的文字呢?事實上這個討論在網上一直都有,也有使用漢字的編程語言,譬如“易語言”。總體來說,漢字編程有兩個比較大的問題,其一是國際化的問題,畢竟編程技術在全球範圍內的共享和共建,英語還是最常見的選擇;其二是我們手上的是一個英文鍵盤,從輸入效率來說,寫英文的效率會比較高。
總體來說,英語水平會影響編程技術的學習和使用,但不是一個核心門檻。相反,如果長期從事編程工作,可能還會提高一定的單詞量,因為常常需要查一下字典,為自己辛苦寫下的代碼,取個“洋氣”的名字。
經濟條件和編程的關係
現在電腦已經不是什麼高檔電器了,甚至很多手機都比電腦要貴。而且一般的編程工作,也無需特別豪華的硬件配置,很多二手的電腦,都完全能勝任很多編程工作。甚至攢硬件自己裝一臺電腦,也是一個能學到不少知識的過程。
過去很長一段時間,程序開發的工作機會多,收入水平可觀,所以吸引了大量的人員投入這個行業。不過根據個人的經驗,也有很多人,在真正從事了一段編程工作,都放棄了這種工作。而且本身經濟條件越好的,越容易放棄。畢竟,編程工作是一個“嚴格”的工作:你可能寫一篇文章,裡面有幾個錯別字,不太會影響這篇文章的可讀性;你可以畫一副畫,有幾筆是畫錯了的,也不一定被觀眾發現……然而,你寫錯了一行代碼,首先編譯器就會暴跳如雷和你較勁;如果你搞定了編譯器,如果有一些隱藏的 BUG,可能讓程序運行到一半突然就崩潰了,如果你見過所謂的“Windows 藍屏”,你就能知道這類問題多麼讓人煩躁。 ——一直浸泡在高濃度的“失敗”情緒中,而且還提心吊膽的害怕不知道什麼時候出現 BUG,這不是一個讓人容易接受的工作。
如果一個人既不用擔心柴米油鹽,又喜愛編程這個工作,這是最好的狀態。這樣才能真正的去探索軟件開發的技巧,而不是天天打聽學什麼技術,能得到更高薪的崗位。技術的潮流變來變去,如果僅僅是試圖趕上風口,是一件很累人的活。所以,歸根到底學編程和有錢沒錢關係不大,如果只是想混口飯吃,這個工作,可能和其他工作差異不大;如果真的喜愛編程,那麼從中也能獲得非常大的樂趣。
C 語言為什麼使用如此廣泛
說到編程語言,C 語言是一個繞不過的話題。一直到今天,這門歷史悠久的語言,依然是軟件開發中最常見的語言之一。很多人都說,學編程必須要要學 C 語言,但是事實上,不會寫 C 語言的程序員也比比皆是。只是簡單的學習過一下,沒有真正的開發過工程,是不能叫做“懂 C 語言”的。那麼,到底 C 語言是不是一定要學的呢?我覺得要學,也可以不學。下面說說我的理由。
操作系統的原生語言
大概大家都知道,我們現在用的很多操作系統,譬如 LINUX,都是用 C 語言開發的。那麼,是因為 C 語言“特別好”,所以操作系統才用 C 語言開發的嗎?我覺得相當大的原因是歷史造成的,也就是說,當很多操作系統在第一個版本的開發時,C 語言可能是當時的最好的開發語言。
現在我們說到操作系統,譬如 iOS、安卓、windows,似乎操作系統是一個提供給用戶,進行應用程序的安裝、卸載、運行的平臺軟件。有些還會自帶一些好用或者不好用的軟件。但事實上,操作系統遠遠不止上面說的這些,甚至可以說,提供給最終用戶進行操作的界面,並不是操作系統的核心功能。操作系統的真正的核心功能,是提供對硬件(最主要的是內存、CPU、磁盤)的功能封裝和細節屏蔽,簡單來說,操作系統的主要用戶是應用程序的開發程序員。微軟的第一桶金 MS-DOS 系統,全名是 Microsoft Disk Operating System,翻譯過來就是“磁盤操作系統”,看起來是不是就特別“硬件”?
由於操作系統,對於大多數的計算機外設,譬如磁盤、網卡、顯示卡等,都做了功能封裝,這樣應用程序開發者就不需要針對硬件去編程,而是只需要使用操作系統提供的編程接口,就可以使用這些外設的能力了。正因為 C 語言是很多操作系統的開發語言,所以很多操作系統都提供了 C 語言的 API。因此很多開發者都選擇繼續使用 C 語言來開發其他程序了。
在 Linux 上 man epoll
我在使用 JAVA/C#/PHP 等語言的時候,會比較注意能找到什麼樣的“庫”或者“SDK”,因為我的程序可能需要依賴這些“庫”。舉個例子,我要讀寫操作系統的“共享內存”,如果我用 C 語言開發程序,我可以直接調用操作系統提供的 C 語言 API,在 LINXU 上就是所謂的“系統調用”;如果我用 Java,就必須要找到 MappedByteBuffer 這個類,並且只能用 mmap 類型的共享內存,至於其他類型的共享內存功能,可能就要再找找有沒有人封裝過了。如果沒有,那你就需要自己寫一個符合 JNI 標準的 C 語言程序,封裝一下這個功能函數,然後再提供給 Java 調用。——看,這不還是得寫一些 C 的代碼嗎?所以,直接用 C 語言來寫應用程序,就可以避免這個麻煩。
3L 和 ABI 規範
剛剛上面提到,JAVA 如果想要調用 C 語言的代碼,需要按照 JNI 的規範寫一個封裝的程序。這個 JNI 規範,全稱是 Java Native Interface,是 Java 提供的一個功能,可以調用一切 C 語言編寫的庫。事實上,絕大多數的語言,都可以調用 C 語言編寫的庫,甚至在 Go 語言的源碼文件裡,以註釋的形式寫的 C 語言源碼,都可以被編譯運行。而這些語言都能使用 C 語言代碼的原因,是因為 C 語言的 ABI 格式,是最廣泛被接受的一種 ABI 規範。
ABI 全程是 Application Binary Interfce,意思是應用程序二進制接口。這類接口定義了不同的二進程程序,如何互相調用(鏈接)。對比於大家更熟悉的 API,全程 Application Programming Interface,這個是提供給程序員編程用的接口。由於 C 語言的歷史悠久,所以其他不管什麼語言,一開始都會考慮支持 C 語言的 ABI 規範,以便新的語言可以使用大量的現成的 C 語言編寫的庫。
如果你想寫一個框架,或者比較通用的庫,你可能會希望更讓這些代碼運行在各種編程語言環境下,現在來看,幾乎只有 C 語言是最合適的。這樣就“促使”很多人繼續編寫 C 語言代碼了。
雖然 C 語言的庫幾乎被所有語言支持調用,但好玩的是,C 語言自己並沒有規定這個 ABI 規範。提供這個 ABI 規範的實現代碼,往往是編譯器開發商做的。所以我們只學會 C 語言的內容,會幾乎連編譯運行都無法實現,而是需要再學習一門奇怪的知識,名叫《3L》,才能真正讓程序運行起來。
所謂的 3L,就是 Link/Load/Library 的意思。這裡面的知識,在每個學 C 語言的第一課就能碰到,但要真正掌握它,卻往往沒有那麼容易。舉個例子,我們的 C 語言的 hello world 程序往往是這樣的:
#include <stdio.h> int main() { printf("Hello, World!"); return 0; }
這段代碼雖然簡單,但卻有一個值得思考的問題:“printf() 這個函數的代碼,到底在什麼地方呢?”很多人會說,在 #include <stdio.h> 裡面嘛。這個說法對,但不完全對。因為 .h 文件被稱為“頭文件”,這種文件裡面往往只有“聲明”而沒有定義。也就是說 stdio.h 裡面只是 printf() 函數的“形式”,而不包含實現代碼。
而上面 printf() 的具體代碼,實際上是通過所謂的“鏈接”,被編譯器“放”進你要編譯的程序中的。而“鏈接”的對象,就是一個叫做 /usr/lib64/libc.so.6 的庫文件——這個庫文件被稱為“C語言標準庫”。當我們編譯 helloworld 程序的時候,就算不寫“鏈接”的命令,編譯器也會自動幫我們鏈接這個庫。
$ ldd a.out linux-vdso.so.1 (0x00007ffc4bfb0000) libstdc++.so.6 => /usr/lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007f6b48f24000) libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f6b48c20000) libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007f6b48a09000) libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f6b4866a000) /lib64/ld-linux-x86-64.so.2 (0x00007f6b494ab000)
在 Linux 上可以用 ldd 命令查看鏈接的動態庫
然而,如果不是標準庫,而是其他的庫,就需要我們學習如何使用編譯器參數,去指定要鏈接什麼庫文件。這裡的鏈接還分動態鏈接和靜態鏈接,靜態鏈接的意思是,把需要的功能代碼打包到最終的可執行文件裡面去;而動態鏈接,則是讓可執行文件在運行時,再去加載庫文件。動態鏈接也可以作為一種軟件更新的技術:我們可以通過發佈和替換動態庫(linux 往往是 .so 文件、windows 則是 .dll 文件)來更新一個軟件的功能。
由於鏈接的過程,是由各個編譯器軟件來實現的,並不是統一在 C 語言的規範裡,也沒有一個公司或者組織來約束,所以使用不同的編譯器,以及使用不同的編譯器生成的庫的時候,就會出現大量的“兼容”問題。加上 C 語言也沒有後來語言的“包依賴管理”的系統,所以計算鏈接同一個庫,如果用的是不同的版本,也可能出現鏈接錯誤,這些問題,也是 C 程序員需要經常處理的問題之一。
儘管 ABI 和鏈接規範有很多問題,但這些確實是我們現在操作系統的真實底層原理。所以當我們沒有其他方法的時候(或者不想使用其他方法),我們最後還是有 C 語言這樣的一個手段。
數學符號關鍵字
從使用硬件的角度來看,大部分編程語言,其語法功能實際上是用來操控“內存”和“CPU”這兩種硬件的。C 語言設計兩個重要的概念,來抽象和使用這兩個硬件,一個概念是“變量”,另外一個是“函數”。這兩個來自於數學的概念,被用於計算機編程,對於推動軟件開發的進步,起到了非常重要的作用,以至於現代幾乎所有編程語言都有這兩個概念。但是“借鑑數學概念”用於編程,卻並不是完美無缺。
- 最臭名昭著的數學符號誤解,就是=號。在 C 語言中,這個符號實際上對內存的讀取和寫入操作,但在數學上這是一個“相等”的聲明。這導致了大量的因為 if (foo = bar) 的 BUG 誕生。PASCAL 語言用 := 作為賦值符號,可以說是對這種錯誤的一個糾正。
- * 號,同時具備“乘法”“聲明指針”“解引用”三個含義,具體是什麼意思,取決於這個符號寫在什麼地方。這也是 C 語言代碼閱讀和學習比較困難的一個原因。
#include <stdio.h> int main () { int var = 20; int *ip; /* 指針變量的聲明,這裡的星號表示聲明的是一個指針 */ ip = &var;/* 等號表示賦值,把 var 的地址寫入 ip 變量的內存中 */ /* 使用指針訪問值,這裡的星號表示“解引用操作符”,即讀取指針指向的內存塊內容 */ printf("*ip 變量的值: %d\n", *ip ); return 0; }
- 在數學上,函數可以理解為對某種規律的描述:你可以輸入自變量,獲得返回值。然而,我們往往把“函數”當成一個功能處理過程去編寫,這就導致了“就算相同的輸入,也不會有相同的輸出”的“函數”的出現。我們表面上好像是用函數在計算一些結果,實際上是利用這些函數的“副作用”去完成一些功能。這種表達和實際的差異,也是造成大量 BUG 的原因。
- 由於變量對應著內存,所以代碼中的變量,並不能單純的認為是一個數值的容器。譬如在 C 語言中,你如果返回了一個局部變量的指針,這個指針指向的變量內容,很可能在下次使用時,被不知道什麼數據所覆蓋。所以使用 C 語言必須要理解所謂“堆”和“(堆)棧”的差別。如果你認為局部變量不好用而使用“堆”裡的變量,那麼就必須注意自己進行內存的回收釋放,否則就又掉進了“內存洩漏”的坑裡。
- C 語言中的變量,雖然有各種類型,但實際上編譯器幾乎不會自動的對其進行什麼操作,於是不管是什麼類型,其實都代表的一塊內存而已。類型不同僅僅是代表不同長度的內存塊。而在不同編譯器和不同操作系統下,同樣的類型對應的長度還不一樣,這就更增加了這門語言的複雜性。譬如 32 位系統下的 long int 是 4 個字節,64 位系統下則是 8 個字節。本來這種長度差異不太應該影響程序員編碼,但很多 C 的庫又設計成使用 指針+長度 的方式來傳參,所以變量長度變得不得不關心了。同樣的問題還有結構體的字節對齊問題。
不過話說回來,C 語言有再多的問題,還是比彙編語言更利於人類理解和操作。而對於內存操作的直接和方便,也讓程序員們能創造更多有用且高效的通用數據結構,讓我們處理複雜問題變得更加簡單。因此在追求高性能程序模塊的程序員眼裡,C 語言依然是不可替代的一種工具。
那麼最後來說,C 語言是不是作為程序員,必須要學的語言呢?從開發實踐上來說,不是必然要學。很多編程崗位,並不會因為你懂 C 語言就給你躲開工資。但如果你懂這門語言,用這個語言開發過程序,你會有一種接觸底層原理的感覺。計算機科學的基本形式,就是層層抽象。而 C 語言,剛好處於擅長形式化的高級語言,和彙編這種硬件操作語言之間。穿透了這層抽象,就能觸摸到硬件的層面,從而對計算機科學有更深一層的理解。
自帶內存管理的語言們
內存為什麼需要管理
在使用 C/C++ 這類需要手工管理內存的語言時,感覺就好像去食堂吃飯:你需要先自己取餐盤,然後把餐盤裝上食物,最後吃完後還得把餐盤還回去。如果餐盤太小了,還得多跑幾趟多拿幾次餐盤。如果我們使用帶內存管理的語言,就感覺是在飯店吃飯:只要點好菜,服務員就會端上做好的飯菜,我們不必擔心每道菜應該用多大的盤子,吃完也不需要打掃桌子。這就是所謂的內存資源管理工作,餐盤就是內存,我們希望使用的數據,是盤子裡的菜,而不想操心盤子。
除了資源管理,我們寫的程序現在往往都是“併發”的,譬如多進程或者多線程的。如果沒有任何工具,我們是很難控制多段“同時”運行的代碼,對同一塊內存(變量)的讀寫結果。可能你想運行 i++,但是這個變量在多個線程同時運行時,可能 i 會被賦值為其他值;如果你把這個變量作為循環判斷值,有可能你的線程會陷入死循環……
另外,安全性也是內存管理的重要原因,經典的“棧溢出”程序漏洞,就是由於對內存缺乏管理限制導致的:如果你從文件、網絡或者地方讀入一段數據,而沒有安排足夠的內存空間來存放,譬如使用了一個固定長度的數組作為局部變量,那麼你就有可能在讀取這段數據之後,讓你的堆棧裡放入一堆未曾預料的數據,而這段數據中的某一塊可能正好能覆蓋當前函數的返回地址,於是程序就會在執行完本函數後,跳到一個你剛剛讀入的數據所決定的程序裡,這樣你的程序就可能被用來做任何事情。如此危險的漏洞,只是源於一個讀入數據的數組沒有檢查長度而已!
由於編程語言最基本的能力之一,就是操控內存,所以內存管理功能的實現,自然成了很多編程語言的重要課題。
Java:你媽覺得你冷
Java 語言給人的感覺特別貼心,貼心到有點煩惱。對於初學者來說,一旦學會了和它“和諧共處”,寫起程序來就會感覺非常“穩妥”。但如果你已經有其他一些語言的使用經驗,你會有一種被強行套上秋褲的感覺。
CLASSPATH
相對於 C/C++ 讓人眼花繚亂的各種鏈接錯誤,JAVA 語言由於對於 CLASSPATH 的錯誤,就顯得簡單太多了——儘管 ClassNotFoundExption 還是最常見的問題。事實上你可以把所有經過 javac 編譯的文件,都視為動態庫;所有你依賴的庫,都通過 CLASSPATH 參數去添加,就可以解決問題了。不過,由於在很多 JAVA 框架裡面,組織 CLASSPATH 內容的工作,可能被放在各種配置文件裡面,所以很多時候我們“學習”的額外內容,是那些框架“造成”的,但本質上也就是 CLASSPATH 而已。
Java 還具有在運行時通過代碼下載、加載 .class 文件的能力。這種能力對於動態更新代碼,開發諸如邊下邊玩功能很有意義。這種能力對比純腳本型語言要複雜一些,但是性能會更高一點。
CLASSPATH 這種機制很方便,唯一的缺點就是,所有的 java 程序,在進程列表裡面,都是一串以 java 開頭的長長的命令行(裡面大部分都是 CLASSPATH 的內容),看起來一點都不像一個正經進程。
內存管理
我們用 C 語言定義一個變量,我們可以決定變量所佔用的內存長度,以及這塊內存是在堆上,還是堆棧上;我們還可以決定,數據在變量之間傳遞的時候,是傳遞內存地址(指針)還是傳遞值(複製)。但在 Java 語言裡,這些自由統統都不存在:
- 基礎類型變量,譬如 int/boolean 這些(注意 String 並不是基礎類型),永遠都是值傳遞,你也沒法關心是在堆上還是棧上。
- 對象類型變量,所有的 Object 的子類和數組這些,永遠都是引用傳遞(類似指針),所以肯定是在堆上。
- 如果你硬是想弄一個基礎類型的數據容器,譬如存放 int 類型的“對象”,那麼你需要進行“裝箱”這種儀式,幸好新的 JDK 已經從語言層面支持了。
Java 的數組,包含 String 類型,終於是會自動檢測長度了,不會讓你寫入數據到預期的地址之外了,如果你的程序沒注意,Java 會拋出一個 OutOfIndexException。這樣“棧溢出”的安全漏洞風險,會大大的降低。雖然一不小心就會碰到這種異常很煩人,但是每個這種異常,放在 C 語言程序裡,可能就是一個致命的安全漏洞,修復這種問題還是很有必要的。
當然,Java 是不需要自己回收內存的,因為所有的“對象”都會被 JVM 在運行時進行“垃圾回收”。這個過程我們可以想象,在整個內存池中掃描成千上萬的地址,是挺消耗性能的。一般來說我們無法直接參與這個過程,因此也被很多程序員詬病,還想出各種“奇技淫巧”試圖影響這個過程。
雖然 Java 有自動的“垃圾回收”機制,但還是有可能出現內存洩露的。如果你使用了一個 static 類型的變量,恰好這個變量又引用了大量的其他對象,譬如說你這個變量是一個 HashMap,這就可能成為一個“內測漏洞”。當然,一個無窮遞歸也很容引發內存耗盡,這個“棧耗盡”和其他語言是一樣的。
異常機制
任何聲明瞭會拋出異常的方法,你調用它就必須要捕捉這些異常,否則不能通過編譯檢查。——這個對於初學者來說,簡直就是一場和編譯器的搏鬥。但是這場讓人精疲力盡的博鬥的結果,還是挺有價值的。絕大多數的錯誤,都會被強迫處理,以往那些“不判斷返回值”而導致的 BUG,在 Java 中是很少出現的。異常處理就好像一個安全圍欄,把你的程序保護起來。
FileInputStream in; try { in = new FileInputStream(file); // 正常流程就這兩行 in.read(filecontent); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { try{ in.close(); } catch (IOExeption e) { e.printStackTrace(); } }
讀個文件,異常處理代碼比正常代碼要多一大堆
然而,再安全的圍欄,也有一些缺口。對於服務器端 Java 程序來說,最常見的有兩個:
- NullPointerException 這個異常是由於你調用了一個內容為 null 的對象的方法或者屬性。由於 null 這個值非常特殊,它可以被賦值給任何類型的對象,所以很難被簡單的發現。什麼情況下,一個 Object 變量被賦值為 null 呢?很可能是在調用一個 HashMap 的 get() 方法後,沒有判斷返回是 null 導致的。有一些 API 調用會返回 null,這個是非常需要注意的。
- ConcurrentModifyException 如果有兩個以上的線程,在同時操作一個容器變量,就可能會出現。譬如一個線程正在用迭代器遍歷,另外一個線程在插入元素。大多數情況下解決方法也比較簡單,就是用 synchronized 關鍵字來“鎖”住這個容器變量就可以了。當然如果迭代器遍歷循環代碼裡,又調用到另外一個容器的方法,那麼就有可能發生“死鎖”。當然也可以用一些支持併發的容器,來解決可能的併發修改問題,Java 提供了一整套“併發”所需的庫( java.concurrentcy.* ),包括各種形式的鎖、線程安全容器等。
併發支持
儘管沒有關鍵字來直接啟動線程,但是 synchronized 關鍵字讓 Java 的“併發鎖”用起來變得非常容易。JDK 自帶的 Thread 類及其相關類庫,讓編寫多線程程序變得非常簡單。
不過,對於併發問題的處理,除了多線程以外,單線程異步是一種運行效率更高的方式。因為有可能節省大量的線程棧內存的佔用,而且也可以利用到 Linux 的 epoll 能力。java.nio 提供了比較好的支持,不過,對比多線程的支持,異步回到或者“協程”的支持就沒有 Go 語言那麼好。
Java 的多線程,在 Linux 上還是使用 pthread 庫,用子進程來模擬的線程。雖然 Linux 的多進程性能也相當不錯,但是在成千上萬的“java 線程”的瘋狂切換的情況下,對內存和CPU都會造成比較大的壓力。這個問題也是後續其他很多語言和框架著眼的地方。譬如 go 語言就會根據 CPU 的核心數來啟動真正幹活的子進程,而編程概念上的“協程”和真正的子進程是不捆綁的。
C#:我全都要
C# 就是 Java 異父異母的親兄弟:兩者都號稱可以跨平臺,也確實做到了windows/linux 雙棲;兩者都是運行字節碼代碼,有自己的虛擬機進程;以前覺得 M$ 特別封閉,覺得 SUN 相對開放,現在反過來對比,微軟比甲骨文更開放。
C# 好像一個各種語言特性的大雜燴,或者叫博彩眾家之長:
- Java 不是沒有值拷貝的變量類型嗎?C# 有,叫 struct
- Java 反對使用“輸出參數”,C++ 使用輸出參數很普遍,C# 都有,既可以返回一個對象而沒有心理負擔,也可以用 out/ref 關鍵字做輸出參數。
- 異常處理 try-catch,C# 也有,但不會像 Java 一樣強迫你處理
- RTTI、反射,C# 全有
- Java 的 Annotation,C# 叫 Atrribute
- Interface Java 有,C++ 沒有,C# 還是有,而且比 Java 的更徹底:要訪問一個接口的方法,只能通過接口類型的變量訪問,通過真實實現類型的變量是無法通過編譯的。
- JavaBean 苦口婆心推廣 Setter/Getter 的寫法,C# 直接用語言實現掉,就是 Property 特性。
- C++ 可以重載運算符,Java 不可以,所以 C# 也可以自定義+ - * /運算符
好像上面這樣的特性還有好多好多。你可以按 Java 類似的特性去寫 C#,也可以用 C++ 的想法去寫 C#,不知道這是不是這門語言設計者的目的呢?
Go:專門為服務器端設計的語言
Go 語言的設計相當的“自我”,它不會去考慮遷就不同“習慣”的程序員,而是直接定死自己覺得好的“規矩”作為默認用法,這和 C# 簡直就是一個強烈對比。
- 所有的源碼編譯出來就是一個二進制,全部都是靜態鏈接。(在服務器上一般只運行這個程序,也不需要動態更新或者和其他程序共用動態庫啥的)
- 包依賴功能自動和 git 綁定,你不喜歡用 git 也不行。(客戶端開發,特別是遊戲客戶端開發,工程裡面包含太多二進制文件,用 git 會特別的慢,所以你別用 Go 寫客戶端吧。)
- 沒有什麼引用傳遞,全是值傳遞,如果不想複製一個巨大的數據塊,就用指針。這個指針不能像 C 語言一樣進行數學運算 ++ --,但還是要叫“指針”,而不是換成什麼別的名字遮掩一下。
- 局部變量返回之後,就變成了堆上的變量,所以也可以垃圾回收了。(不需要手工指定使用堆還是堆棧,就算你用new()指定了,可能也是白忙活)
- 自帶併發“協程”,但又不是異步的,一樣需要你把容器類型變量鎖起來,或者你用線程安全的容器,用起來和多線程幾乎一樣。
- 把 select、chan 這種東西直接弄到語言裡面,儘管這功能完全可以用庫的方式提供,但 Go 就是要讓你膜拜一下。
- 沒有 try-catch-finally 捕捉異常這種玩意,只有 defer 關鍵字,你就是要用 finally 的寫法去幹捕捉異常的事情。
- 用註釋來生成文檔有什麼特別的,看我用註釋來寫程序:go 源碼的註釋可以寫一段 C 語言代碼並且調用!
package main /* #include <stdio.h> void c_print(char* str) { printf("%s\n", str); } */ import "C" func main() { s := "hello C" cs := C.CString(s) C.c_print(cs) }
面嚮對象語言是一個騙局嗎?
OO 三特性
我們常常說,面向對象的三個特徵:封裝、繼承、多態。但是這三個特性,幾乎每個特性,都有一堆反對者,認為這樣的特性是無效的。
- 封裝:歷來就有“失血模型”和“充血模型”的爭議。在 WEB 開發領域,由於存在大量的數據庫 CRUD 操作,所以不管你的類有什麼屬性,大多數都是那麼幾個方法,所以把方法和屬性封到一塊,看起來沒啥必要,反而增加了大堆類似而重複的代碼。
- 繼承:繼承會破壞封裝,讓父類的行為被改變,所以不要繼承!用組合來代替繼承!多繼承是邪惡的,所以只能單繼承,如果你需要一個對象同時可以是幾個不同的“類型”,那麼你只能為這些類型每個都定義一個“接口”,增加一大堆代碼。如果“繼承樹”一開始設計的不合理,極有可能需要修改“樹幹中”的某一個節點,也就是某個基類,導致下游一大堆的子類被迫要修改。
- 多態:這個特性是爭論最小的特性,但是也有人覺得,其實就是一種 switch case 嘛,最高級的程序員(食材)往往只需要最簡單的語法(做法)……
在沒有面向對象特性支持的時候,編程語言也可以完成一切邏輯表達。如果我們不把面向對象視為一種信仰,而是一個工具,我們才能發揮它的作用。
面相對象是一種名詞性的定義,它希望編程語言不再是動詞形式或者數學形式的,而是類似日常人類思維的方式去描述問題。所以才有了把函數和結構體放到一起,成為一種邏輯單元的定義。如果我們已經把一個事情的處理流程,完整的細化分割出來後,其實是不需要面相對象的,這種場景在現存的進存銷、運輸管理、財務、電信這些現成業務環境下,是很常見的。上面失血模型的支持者,連封裝都不想要了,還怕什麼繼承破壞封裝?所以說談面向對象的時候討論失血模型,本身可能就是一種錯誤的面向對象建模導致的問題。
如果不使用繼承,即便相似的功能,也必須要定義很多用法類似,但名字不同的函數(庫)來提供給程序員。PHP 的庫裡面就有大量這種例子。學習 API 在這種情況下,成為一種效率比較低的工作。如果你只是開發某個特定的工作細節,這種消耗可能不甚明顯,但如果你是某個外包軟件公司的程序員,可能你每天都必須不停翻查各種 API 手冊。更重要的是,你不能只修改一個庫裡面的幾個函數,然後把一整個庫提供給你的同事,而是必須重新寫一整套的庫,即便庫裡面大多數代碼都是隻有“包裝代碼”——這也是用組合替代繼承的常見情況。
關於多態,甚至有一個設計模式,基本上就是多態特性的“使用指南”,這個模式叫“策略模式”。不過,也有一個走火入魔的例子,就是類似早年的 Java Spring 框架,整個程序的初始化,並不是 Java 代碼,而是一個巨大而且複雜的 XML 配置文件。所有登記的類都按照一套複雜的規則,實現某一批接口,然後在沒有 IDE 和編譯器檢查的幫助下,試圖組合運行起來。事實上,如果你認為多態是一種好的編程特性,那麼必然也會認可,降低程序員的心智負擔是一個有價值的事情。只不過繼承和封裝,並不像多態對於複雜邏輯的簡化程度,有如此立竿見影的效果。
類爆炸、構造器混亂和“基於對象”
“面向對象綜合徵”最典型一個症狀就是類爆炸,最常見發病於 Java 領域:在 Java 中,任何東西都要放到一個類裡面,就算只是一個 main 函數,也必須要找個類把這個函數包起來,還得加上 static public 修飾方法;用所謂面向接口編程的模式下,往往你為了增加一個方法,被迫新增兩個類定義,一個實現類,一個接口類。
如果沉迷於 MVC 的模式,一個功能可能被弄成三組類型:全是結構體屬性的 model 大隊、全是用於顯示的代碼的 view 大隊、還有不知道為什麼一定要有的一堆 control 大隊,即便你寫了一堆代碼,還是發現有一批業務邏輯不知道放哪裡,於是又寫了一堆 service 類型,用來被 control 或者 model 調用。我們很多時候學習面相對象編程方法,都是向各種框架去學習,但是框架為了通用性,本身就是一個帶有大量的接口的程序。所以完全學著某些框架去設計類,或者過於熱衷實現某種設計模式,就特別容易搞出大量的類。
面嚮對象語言一直有一個問題,就是對象構造的過程非常麻煩。所以設計模式裡面,有差不多一半是用來構造對象的。在 Java C# Python C++ 等語言裡面,都有所謂的對象構造器的設計。但是在本類的各種屬性初始化、本類構造器、父類的各種屬性初始化、父類的構造器這些代碼的順序上,事情變得異常的複雜,加上構造器還有不同的參數和重載,加上類的靜態成員也需要構造。如果類似 C++ 是多繼承的語言,這種問題會變得更加複雜。很多編程的面試題,最喜歡考這一類問題,但我卻覺得,這種複雜性是編程語言本身的一種缺陷。編程語言是給人用的,不是考人用的。
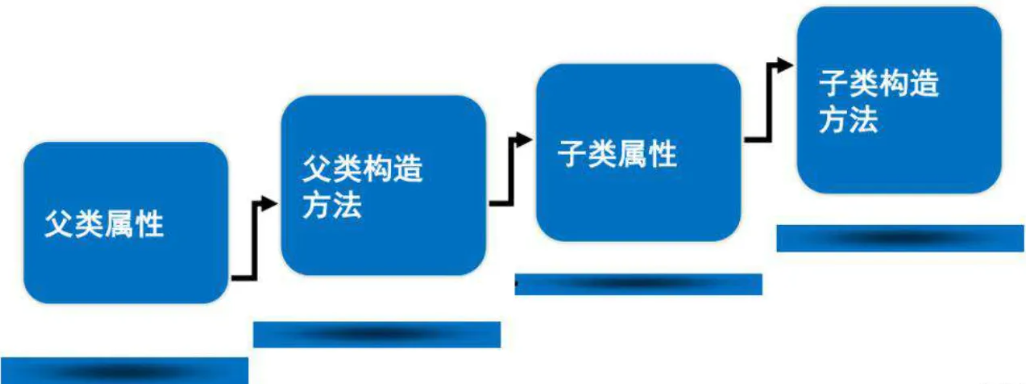
某種語言的對象構造順序
在比較新的語言(相對 C++/JAVA)上,很多時候會拋棄“類模板”的設計,就是不再設計一個叫“類”的概念,而是保留“對象”的概念。沒有了“類”,就不存在“類爆炸”了。繼承的實現,就用簡單的“原型鏈”的思路:A 對象如果是 B 對象的“原型”,那麼在 B 對象上找不到的東西(方法或者屬性),就順著原型鏈往上去找,也就是去 A 對象那裡找。JavaScript(TypeScript)、Lua、Go 都是用的原型鏈,我稱之為“基於對象”。使用這種方法,靈活性和代碼的編寫複雜度,顯然是比較小的。在現代 IDE 的幫助下,往往也能獲得足夠的對象成員提示,不至於太多的編譯錯誤。大部分傳統的面向對象設計模式,其實都可以用基於對象的語言來實現,而且“構造類”模式,譬如工廠模式之類的,會比類模板的語言更加簡單直觀,甚至你都不會意識到在用的寫法,曾經就是一種設計模式。
C++ 到底是什麼?
並不是 C 語言
C++ 號稱兼容 C 語言,意思是你可以像寫 C 語言一樣編寫 C++ 代碼。同時,一般的 C++ 編譯器,也能很好的鏈接 C 寫的庫。但是,如果不特別的標註 extern "C",C++ 寫的庫是不能被 C 語言代碼鏈接的。C++ 為了在語法上兼容 C 語言,讓很多新的特性“嫁接”在 C 語言的概念上。譬如 指針 這個概念,整個面向對象的動態綁定,幾乎都利用‘指針’來表達(另外還有 C++ 專屬概念‘引用’)。同樣的還有 struct 這個關鍵字,C 語言和 C++ 語言都有這個關鍵字,但真正的功能可像相差很遠。對於 C 語言來說,結構體變量的內存長度、佈局其實是比較簡單的,但是 C++ 的對象可不簡單,而且很多公司面試很喜歡問這個。
class Parent { public: int iparent; Parent ():iparent (10) {} virtual void f() { cout << " Parent::f()" << endl; } virtual void g() { cout << " Parent::g()" << endl; } virtual void h() { cout << " Parent::h()" << endl; } }; class Child : public Parent { public: int ichild; Child():ichild(100) {} virtual void f() { cout << "Child::f()" << endl; } virtual void g_child() { cout << "Child::g_child()" << endl; } virtual void h_child() { cout << "Child::h_child()" << endl; } }; class GrandChild : public Child{ public: int igrandchild; GrandChild():igrandchild(1000) {} virtual void f() { cout << "GrandChild::f()" << endl; } virtual void g_child() { cout << "GrandChild::g_child()" << endl; } virtual void h_grandchild() { cout << "GrandChild::h_grandchild()" << endl; } };
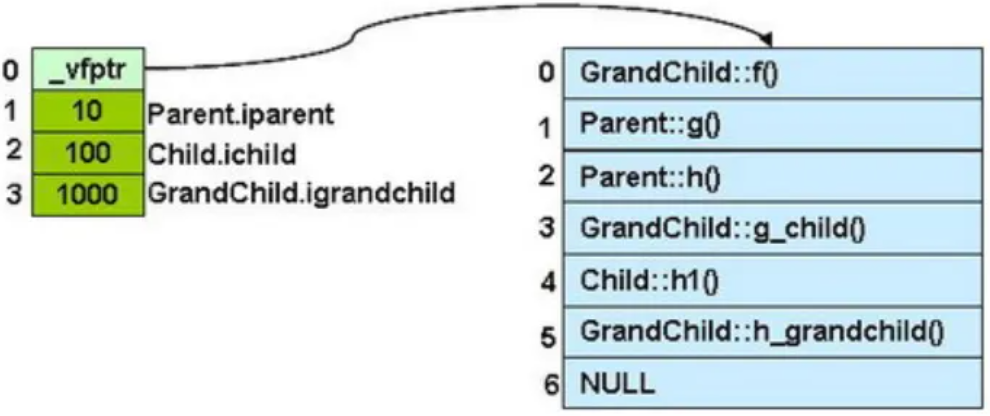
上面代碼一個 GrandChild 對象的內存結構
動態綁定:把指針玩出花兒來
C++ 在面向對象的多態上,幾乎完全依靠“指針”。由於 C 語言當中,變量的類型決定了變量的內存數據,所以你一旦聲明瞭一個父類變量,這個變量就時固定為父類對象了,再也沒有機會用作任何的子類對象變量, C++ 也兼容了這一點,但是如果沒有辦法拿一個父類變量作為子類變量使用,動態綁定就無從談起,於是 C++ 就借用了“指針”這個概念:所有類型的指針,內存長度都是一樣的。於是 C++ 的整套面向對象的動態綁定(多態)機制,就都建立在指針上了。
Parent *obj = new Child()
如果對於指針搞不明白,不但 C 語言玩不轉,C++ 也是基本沒法用的。這個糟糕的星號,從 C 語言一直留到 C++。
靜態綁定:真正的架構師語言
如果你希望寫一套程序庫,而且希望約束使用者的用法,那麼你除了希望這個庫有足夠的功能外,肯定也希望編程語言能提供給你一些工具,能夠讓用戶能足夠靈活的使用你的庫。特別是對於“有一部分”代碼,你預期是使用者編寫,然後放在你的框架內運行的情況,俗稱“回調”,譬如說你寫了一個 web 服務器的框架,希望使用者只用填寫訪問某個 URL 就執行的函數;或者說你寫了一個遊戲的框架,希望使用者只編寫某個角色被擊中的效果等等。
這種代碼在傳統的面向對象變成方法上,一般需要定義一個 interface,然後讓使用者來實現。這種擴展方法,也是導致“類爆炸”的原因之一,因為使用者如果使用了多個框架,那麼為了使用這些框架而寫的回調函數,可能需要定義一大堆 interface。而 C++ 的另外一個特性,就很好的解決了這個問題,這就是“模板”功能。
有的人會認為“模板”特性,幾乎是另外一種語言。然而“模板”特性被用在 C++ 最重要的組成部分 STL 裡面,已經成為 C++ 這個三位一體語言(C語言、面向對象、模板泛型)不可缺少一部分。所以 C++ 如此的複雜,是因為其實整合了三類特性到一門語言中。“模板”特性雖然複雜,但是用來開發被複用的模塊,卻有非常大的好處:
- 不需要實現 interface,只要“語言簽名”對的上,都能直接用
- 編譯時會檢查出所有的錯誤
- 通過使用泛型類的繼承,可以實現對方法調用的“反射”
對於 STL(Standard Template Library) 來說,很多“類型”只要支持一些數學運算符號,譬如“等號”“大於”“小於”這一類,就可以由 STL 提供大量的數據結構工具(如 List/Map 等等),這讓這個庫成為應用最廣泛的 C++ 庫。
template <typename T> void const& DoSomething (T const& a) { a.DoSomething(); }
上面代碼中的模板函數 DoSomething(),可以接受任何類型實現了一個叫 DoSomething() 方法的對象。這是不是比面向對象寫法中,強迫用戶一定要“先聲明一個含有DoSomething的接口,然後讓要用的類型實現這個接口”,要簡單的多?
編程語言分類學
在MOBA類遊戲中有一句話流傳甚廣,叫做“沒有最強的英雄,只有最強的玩家”,這句話被許多玩家奉為經典。編程語言也是這樣,好的程序員往往會精通好幾門語言,並且在合適的情況下選擇合適的語言,去解決問題。因此我們可以對各種編程語言進行不同維度的分類,以便更好的選擇。
編譯、虛擬機、腳本
- 編譯型語言具有最好的效率,也是歷史最悠久的語言類型。C 語言就是這類語言的代表。編譯型語言在環境兼容和內存管理方面,往往不盡如人意,但是還是有很多後續的編譯型語言在這方面做了長足的改進,譬如 Go 語言。作為環境兼容性“差”的另外一面,編譯型語言生成的程序,在已經兼容的環境中,部署方面往往會比較簡單,譬如用 Delphi(Object Pascal) 寫的 GUI 程序,編譯之後只有一個可執行 exe 文件,拷貝到目標機器上就能運行。
- 在“虛擬機”下運行的語言,往往都具有非常豐富的運行時動態特性,譬如 JAVA 和 C#,反射功能只是一個最基本的操作,它們還可以運行時更新代碼,甚至可以支持很多不同的語言在同一個虛擬機上跑(如 Jython 就是用 Python 語言跑在 JAVA 虛擬機上)。比較有趣的是,幾乎所有這類的語言,都號稱要“跨操作系統”。事實上它們也基本上都做到了這點,但是真正用於編寫 PC 或者服務器的跨操作系統的項目非常少,反而在手機、遊戲領域,JAVA(安卓) 和 C#(Unity) 這些語言卻應用非常廣泛。最後說說性能,在 JIT(Just In Time)技術的加持下,很多虛擬機字節碼,實際上擁有了和編譯語言一樣的基礎性能,而那些無法 JIT 的代碼,往往是編譯型語言不支持的一些動態特性。所以除了部署安裝這類語言編寫的軟件,需要額外按照個環境(JRE/.NET)以外,使用起來沒有什麼實質上的差異。
- 腳本語言的歷史其實一點也不比其他語言更短,儘管它們被認為是最容易學習,但性能最差的一批。這類語言的一般都具有所謂的“動態類型”特性,也就是你可以不理睬變量的類型,直接把變量思維萬能的信息盒子。甚至一些常用的數據結構,也被一種很容易使用的方式嵌入在語言中,譬如世界上最好的語言 PHP 就可以使用其萬能的[ ]中括號——它既可以是數組,又可以是列表,還可以是哈希表。腳本徵服“跨操作系統”難題,採用的另外一種方法:讓自己的源碼變得方便移植。其實這個方法,C 語言很早就嘗試過,所謂的 ANSI C,就是明白無法讓 C 語言編譯出來的程序在任何環境運行,那就讓 C 語言的源碼變得可以在任何環境編譯吧,雖然這個嘗試現在來看不是太成功,因為我們使用 C 語言的一個重要理由,就是用來對操作系統進行控制,不同的操作系統提供的 API 本身就差異很大。腳本類語言只需要在不同的操作系統上,實現一遍自己的解析器,就可以成為所謂的跨操作系統了。其中一些語言(譬如 Python),還會連帶把自己的常用庫也移植到不同的操作系統上,而另外一些語言,壓根就沒有什麼庫,它的設計目的就是“寄生”(嵌入)到其他語言編寫的程序中(如 Lua),所有需要移植的“庫”,都是被嵌入的那種語言自己需要解決的問題。
如果要選擇一種語言來作為某個項目的開發語言,我一般會這樣思考:
- 人是第一要素:也就是這個項目的開發人員,最適合用哪種語言。一般來說腳本語言的開發速度是最快的,如果是複雜多變的需求,首選腳本語言。
- 運行環境的依賴因素:如果要開發一個“跨語言”可用的庫,C 語言幾乎是唯一的選擇;如果要開發一款遊戲,希望運行在不同的平臺上,使用帶虛擬機的語言,或者是某種腳本語言,譬如 TypeScript 可能是一個好的選擇,很多遊戲引擎、框架本身也會選擇這一類語言。如果開發的程序可預見的,和某些環境依賴非常密切,那麼就不要自找麻煩,直接選擇環境相關的“官方語言”。
- 性能幾乎是最後的一個考慮要素,除非有非常明確的性能測試結果,不要輕易用這個標準來選擇語言。
由於學習一門新的語言,可能會消耗很多精力和時間,所以一般我們感情上並不喜歡學習新的編程語言。但是,當年學會了第二門語言的時候,你才真正的懂一門語言,這句話在編程方面也是對的。而且學的語言越多,學習的速度越快,而且越能欣賞到這些語言設計者在解決問題時的思考。
通用型和專用型
上面討論的大部分語言,都可以稱為“通用型”語言;然而,編程中,我們往往還會碰到另一類編程語言,它們可以被稱為“專用型”語言。最廣為人知的可能是 SQL(Standard Query Language),我們用這類語言來操作數據庫。還有一類被稱為 Shell Script 的語言也很常見,譬如在 Windows 上的 .bat 和 .ps1 文件中,編寫“批處理”命令,在 Linux 上則是 bash 以及其他各種 sh。我們常見的 HTML,實際上也是一種專用型語言,叫做“超文本標記語言”(Hyper Text Marker Language)。
select name, age, address from User where name = 'Tom';
從易用性上來說,一般“專用型”語言 DSL(Domain-specific language)相對會比較簡單一些。因為這類語言比較少需要把“循環、分支”表達能力一起包含進去,甚至有一些用 JSON/YAML 的配置文件,都可以稱之為一種 DSL。從這個角度來看,編程對人的要求其實並不高。
和通用型語言不同的,DSL 語言基本上都是隻運行於某個特定的軟件之內,所以使用 DSL 其實需要學習的最大負擔,實際上這個宿主軟件的功能。有的軟件功能極其複雜,只好用通用語言來充當原來的 DSL,譬如在微軟 Office 軟件 Word、Excel 上面的“宏語言”,實際上是 VisualBaisc for Application,簡稱 VBA 語言,甚至曾經出現過用這個語言編寫的“宏病毒”。
編程語言的理解思路:用什麼手段,解決了什麼問題
提高開發效率
雖然有人很熱衷於討論各種編程語言的性能表現,但是絕大多數編程語言都是為了寫程序更方便而創造出來的。從彙編語言開始,到 C 語言,再到後面的 Go 語言等等。當我們在學習編程語言的時候,關注點應該更多是,一門語言到底用什麼方法,去幫程序員提高開發效率。
譬如以 C 語言為例,if 和 while 關鍵字,就解決了大量的彙編上跳來跳去的問題,而 function 則對一個“子過程”提供了內存管理和代碼跳轉的很好抽象。又如 Java 語言,提供了標準的 JDK 讓程序員有一個可用的基本類庫,節省了大量自己造基礎輪子的時間;內置多線程的支持,synchronise 關鍵字又簡化了併發程序的編程方法。Go 語言可以返回多個返回值,一方面為錯誤處理提供了方便,另外一方面也避免了定義大量的結構體(類)。
各種語言的面向對象語法的支持,一般來說,都提供了多態支持,簡化了程序擴展中的經典語法:switch case。而且多態也大大簡化了程序員去學習和記憶大量相似函數庫的工作。譬如多家數據庫廠商,針對同一套接口推出各自的實現,程序員可以學習一次數據庫的使用,就能使用多種不同的數據庫。
對於已經掌握了一種語言的開發者來說,另外一種語言的用法,可能會讓人感覺比較彆扭,但是這背後的原因,可能是因為那種語言,在嘗試解決一個其他語言沒有去解決的問題。譬如 python 語言的代碼塊不是用大括號封起來,而是用的縮進,這樣做是為了“強迫程序員寫好縮進”,還有另外一個好處,就是不需要準確的為每個括號進行配對(雖然這個問題在現代 IDE 的幫助下已經不是問題了)。
跨平臺
幾乎所有的語言,都是希望跨平臺的。這裡的平臺包含硬件平臺、操作系統、宿主程序等等。但所有的跨平臺能力,都需要付出一定代價:編譯型語言的跨平臺,就需要跨平臺的編譯器;虛擬機語言的跨平臺,需要跨平臺的虛擬機;腳本語言則需要跨平臺的解析器。另外,跨平臺還需要對平臺相關的功能,進行一定程度的統一抽象和封裝。譬如 windows 和 linux 的文件系統有很多差異,如果要跨平臺進行文件讀寫,必須要抽象成統一的文件操作 API。
安全性
編程語言的安全性,除了包括可能出現的軟件漏洞,還包括了減少程序員 BUG 產生的設計。譬如 C 語言由於對內存管理的支持很少,所以容易出現棧溢出漏洞、內存洩露、以及指針錯誤導致的崩潰;C++ 為此增加了一整套的 STL,在基本容器上減少了很多內存管理的 bug,但指針的使用依然很容易導致內存洩露和程序崩潰;Go 語言保留了指針,但不允許指針運算,而且自動管理全部變量內存,因此指針導致的 bug 被大大減少了。
Java 的異常捕捉“圍欄”機制,強迫程序員處理每一個可能的異常,確實是一種提高安全性的好辦法,但是這也讓程序編寫效率變低。Go 語言則使用錯誤返回的“慣例”來處理異常,開發效率是上去了,但是不免發生忘記判斷返回值的問題。雖然 C++ 也有異常,但是因為沒有內存管理,異常本身的內存分配反而容易變成一個問題,所以用的人需要更加小心翼翼。
和遊戲有什麼關係呢?
為什麼是 C++ ?
遊戲行業內,C++ 是最常見的一種語言。那麼,到底為什麼是 C++,而不是其他語言呢?有人會說,是因為遊戲對性能要求比較高,同時業務邏輯也比較複雜,能承擔這兩點的語言,C++ 基本是唯一選擇。這個理由,我覺得有一定的道理,但事情往往並不是簡單的理論分析就可以看明白的。我覺得最主要的原因,是開發工具:這裡最常見的開發工具,就是微軟的 DirectX,這套庫是 C++ 的,所以很多遊戲就使用了 C++ 來開發。由於遊戲團隊中必須要用 C++,所以沒必要增加其他編程語言,能用 C++ 的就也都用了吧。因此很多配套的遊戲服務器端程序,也就用了 C++,畢竟團隊比較熟悉。這也導致了為什麼其他行業的服務器端,基本不用 C++,譬如電商、社區,而遊戲服務器都是 C++ 的原因。
為什麼不是 C++ ?
C++ 的開發效率實在算不上高。也有一些團隊,從遊戲服務器端開始,不用 C++,而是用 Java 或者 C#。由於 Unity 引擎默認支持的語言是 C#,所以服務器端也用 C# 也是一個常見的選擇。說到底還是開發工具決定了語言。比較有意思的是,雖然 Unreal 的底層是 C++ 的,但是依然有很多團隊會用 Lua 腳本來寫邏輯。
使用腳本語言來寫遊戲邏輯,其實也是遊戲的一個傳統。Python、Lua、Js 在遊戲行業內使用的都比較廣泛。其中以 Lua 最為常見,因為這種語言的解析器非常小,性能也不錯,很適合嵌入在 C/C++ 編寫的其他程序中。作為腳本語言,還有支持“熱更新”的優點,遊戲的玩法變動非常頻繁,這個特性對於遊戲來說非常的重要。
Talk is cheap, show me the code
回想起來,為什麼爭論語言特性是程序員的一大“愛好”?原因除了大家都能參與、各自投入了心血以外,還有一個原因,就是寫代碼這件事其實比寫文章要困難一些。如果我們能多寫寫幾種不同語言的代碼,很多的“爭論”反而會成為我們深入瞭解這門語言的一個契機。在實踐中比較,不管別人是否認可,自己的體會才是最重要的。