快科技7月18日消息,日前由上海人工智能實驗室旗下司南評測體系OpenCompass,對7個AI大模型進行了高考9個科目的全科目測試,從而能全面評測大模型實力。
此次參與測試的模型分別來自阿里巴巴、零一萬物、智譜AI、上海人工智能實驗室&商湯、法國Mistral的開源模型,以及OpenAI的閉源模型GPT-4o。
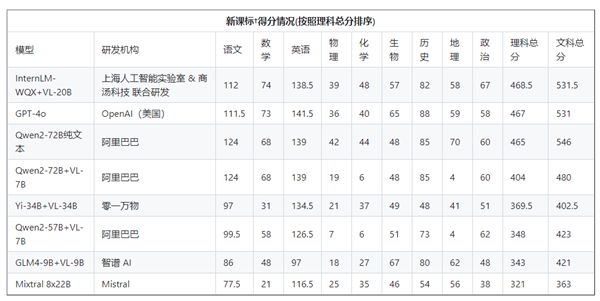
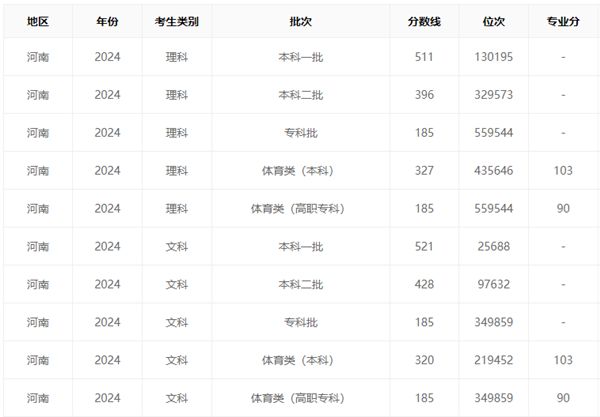
以參加高考人數最多的河南省分數線作為參考,文科成績最好的AI模型能夠達到一本線,而理科成績最好的模型則只能上二本。
文科狀元由阿里通義千問大模型以546分的成績奪得,而理科狀元則是上海人工智能實驗室&商湯聯合研發的浦語文曲星,得分為468.5分。
OpenAI的GPT-4o在文科上得分531分,排名第三,理科得分為467分,排名第二。
在評測中,AI在文科科目如語文、歷史、地理、思想政治等科目上展現了深厚的知識儲備和理解能力,但在理科科目中,數理推理能力普遍存在短板。
特別是在面對帶圖題目時,得分率僅有37.64%,顯示出在圖片理解和運用能力方面,所有大模型均存在較大提升空間。

閱卷老師指出,儘管大模型在基礎知識掌握上表現出色,但在邏輯推理和知識靈活應用方面仍有較大差距。
例如在作答主觀題時,大模型常常無法完整理解題幹,導致答非所問;在解答數學題時,解題過程機械且邏輯性差。
文章來源: 快科技